Digest of Effective Java
目录
chapter 2. Creating and Destroying Objects
- item 1. 考虑用 static factory 方法代替 constructor
- item 2. constructor 参数列表很长时考虑用 Builder 模式
- item 3. 用 private constructor 或者 enum 来强化 singleton
- item 4. 用 private constructor 来强化 util 类
- item 5. 避免创建不必要的对象
- item 6. 消除过期引用
- item 7. 避免使用
finalize()
chapter 3. Methods Common to All Objects
- item 8. 严格的
equals(Object)方法 - item 9. 覆写
equals(Object)时请一并覆写hashCode() - item 10. 请始终覆写
toString() - item 11. 如何覆写
clone() - item 12. 如何覆写
compareTo()
chapter 4. Classes and Interfaces
- item 13. 关于 public class 的 public 字段
- item 14. Use getter/setter in public class
- item 15. 如何写一个不可变类(不可变类对象一定是线程安全的)
- item 16. 组合优于继承
- item 17. 如果一定要设计成供别人继承的形式,请务必提供文档说明;提供文档意味着提出承诺
- item 18. 接口优于抽象类
- item 19. 接口只用于定义类型;常量接口是对接口的不良使用
- item 20. 类层次优于标签类
- item 21. 使用函数对象表示策略
- item 22. 优先考虑静态内部类
chapter 5. Generics
- item 23. 泛型与泛型的 raw type、wildcard type
- item 24. 尽量消除 unchecked warning(意味着不会有
ClassCastException)以及如何使用@SuppressWarning - item 25. 泛型优于数组
- item 26. 如何写一个
Stack<E> - item 27. 如何写一个泛型方法
- item 28. 如何使用
<? extends E>和<? super E>以及 PECS 原则 - item 29. 如何使用
Class<T>
chapter 6. Enums and Annotations
- item 30. 用 enum 代替 static final int
- item 31. 尽量避免使用
enum.ordinal属性 - item 32. 用
EnumSet代替 bit 标志位 - item 33. 若需要按 enum 分类,可以使用
EnumMap(enum 做 key) - item 34. enum 可以实现接口(把 enum 可以包方法 中的方法抽到接口中即可)
- item 35. 注解初步
- item 36. 请坚持使用
@Override - item 37. 标记接口与标记注解
chapter 7. Methods
- item 38. 请检查方法参数的有效性
- item 39. Defensive Copy
- item 40. 如何设计方法签名(特别强调一点:boolean 参数请改用两实例的 enum)
- item 41. 慎用重载
- item 42. 如何正确地使用可变参数列表 (
Type... args) - item 43. 返回零长度的数组或者集合 instead of null,以及如何正确地返回零长度的数组或者集合
- item 44. 如何正确地使用 JavaDoc(
{@literal}真尼玛好用;以及package-info.java的用法)
chapter 8. General Programming
- item 45. 最小化局部变量的作用域
- item 46. for-each 优于传统的 for,更优于 while(少局部变量);三情况下不要使用 for-each:遍历 remove / 遍历 replace / 并行遍历多个集合
- item 47. 类库好处都有啥(比如有了
Random.nextInt(n)就不要再用Random.nextInt() % n了) - item 48. 如果需要精确的计算,请避免使用
float和double,可以降低单位(比如不用秒用微秒,不用 dollar 用 cent)使用int或long,或者使用BigDecimal - item 49. 使用 boxed primitive (如
Integer)时的注意事项 - item 50. 哪些情况下不适合使用
String - item 51. 大量的字符串拼接请用
StringBuilder - item 52. 大多数情况下应使用接口来引用对象(其实就是叫你多用多态)以及三种不适合用接口来引用对象的特殊情况
- item 53. (接上条)反射创造的对象最好也用接口来引用
- item 54. 谨慎使用 Java Native Interface (JNI)
- item 55. 正确理解性能优化
- item 56. 有哪些命名规范
chapter 9. Exceptions
- item 57. 不要将 exception 用于控制流(比如用
ArrayIndexOutOfBoundsException来判断数组已经遍历完毕);反过来,API 应该如何设计才能避免用户将 exception 用于控制流 - item 58. 如何区别使用 checked exception / runtime exception / error
- item 59. 如果不确定是否该用 checked exception,或许使用 unchecked exception 会更好,以及如何改写成 unchecked exception
- item 60. 优先使用标准的异常
- item 61. 如果高层代码调用了底层 API,不要直接抛出底层 exception,应抛出与抽象层次对应的 exception
- item 62. 使用
@throws说明方法抛出的异常,最好包括RuntimeException;永远不要声明一个方法 throws Exception - item 63. 应在 exception 中包含错误细节;可以强制把细节数据作为 exception 构造器的参数,比如
IndexOutOfBoundsException(int lowerBound, int upperBound, int index) - item 64. 努力使对象成为 failure atomic
- item 65. 永远不要使用空 catch,即使一定要忽略某个异常,catch 里也应写上说明或者记录日志
chapter 10. Concurrency
- item 66. 当多个线程 share 可变数据的时候,读写方法都必须是同步的;以及什么是 liveness failure, safety failure 和 safe publication;当然最好是 share 不可变的数据
- item 67. 不过过度同步,i.e. 不要在同步块中做过多的事情(高级内容,请看书)
- item 68.
Executor+Task比Thread更好用 - item 69. 优先使用并发工具类,
wait()、notify()什么的太老土了;以及如何正确地wait() - item 70. 线程安全性的文档化以及线程安全性的级别
- item 71. 谨慎使用 lazy initialization
- item 72. 程序不能依赖 JVM 的线程调度器实现(高级内容,请看书)
- item 73. 不要使用
ThreadGroup,因为已经 obsolete 了
chapter 11. Serialization
- item 74. 实现
Serializable接口不是件很容易的事情(高级内容,请看书) - item 75. 如何选择序列化形式,是默认还是自定义?(高级内容,请看书)
- item 76. 如何 defensively 实现
readObject()方法(高级内容,请看书) - item 77. 单例类如何安全地实现
Serializable以及这么搞不如把单例类设计成 enum(高级内容,请看书) - item 78. 考虑用 serialization proxy 内部类来降低序列化的风险(高级内容,请看书)
chapter 2. Creating and Destroying Objects
item 1. 考虑用 static factory 方法代替 constructor
好处 1:语义更清晰,参数列表更短
CustomLPaper.aNewTemporaryOne()比new CustomLPaper(isTemporary = true)意义更清晰- 不需要再为 constructor 的参数列表写 javadoc
- 如果定义了
public static HashSet<K> newInstance(),可以直接写Set<String> set = HashSet.newInstance(),比Set<String> set = new HashSet<String>()来得方便
好处 2:不用每次都 new 对象
- 比如 enum、singleton
好处 3:可以用 Base 的 static factory 方法返回 Ext 对象
- 可以隐藏
Ext类 Ext也可以设计成 interface,此时在设计Base的 static factory 方法时,可以不关心Ext的具体实现,比如List Collections.unmodifiableList()- 可以实现 Service Provide Framework (参考实现有JDBC)
- 可以方便改造成 Adapter 模式
Service Provide Framework
组件 1:Service Interface
- 可以理解为一个 PO,调用者拿到这个 PO 可以实现他想要的功能
- 如 JDBC 的
Connection
组件 2:Provider Registration API
- 可以理解为 Service 层的一个方法,调用者通过将配置信息传参给这个方法,framework 根据配置确认可以提供这个类型的 Service Interface
- 如
DriverManager.registerDriver(new com.mysql.jdbc.Driver()) - 题外话:如果是直接调用
class.forName('com.mysql.jdbc.Driver'),那么会new com.mysql.jdbc.Driver(),而com.mysql.jdbc.Driver有一个 static initializer 会调用DriverManager.registerDriver(new Driver())
组件 3:Service Access API
- 可以理解为 Service 层的一个方法,通过 Service Provider Interface 或者 反射 来获取 Service Interface
- 如
DriverManager.getConnection("jdbc:mysql://192.168.194.4:3306/letterpaper?user=user&password=password")
组件 4 (option):Service Proveider Interface (SPI)
- 可以理解为一个高级的 PO,负责生成 Service Interface
- 其实我更倾向于称其为 Service Interface Provider,与组件1对应嘛 =。=
- 像上述
getConnection()方法,接受了一个字符串参数,包含了 Service Interface 的名称(”mysql”),如果不用 反射 的话,可以用类似Map<String, ConnectionProvider>的结构来存一个<"mysql", MySQLConnectionProvider>,然后用MySQLConnectionProvider来生成 Connection - JDBC 中,SPI 实际是
interface java.sql.Driver,具体到上述例子中就是com.mysql.jdbc.Driver
很明显,组件 3 Service Access API 是一个 static factory 方法
item 2. constructor 参数列表很长时考虑用 Builder 模式
construtor 参数列表很长时,一般有两种常规做法:
-
telescoping constructor 层叠构造器
形如:
constructor(arg1, arg2)
constructor(arg1, arg2, arg3)
constructor(arg1, arg2, arg3, arg4)- 缺点一:does not scale well,参数列表一长,写起来没完……
- 缺点二:参数顺序的错误很难发现
-
JavaBean
形如:
obj = new constructor();
obj.setArg1(arg1);
obj.setArg2(arg2);- 缺点一:JavaBean 在构造的过程中,自身的状态不一定正确(setter 没执行完就被拿去使用)
- 缺点二:construtor 不能做状态检验
- 缺点三:JavaBean 很难做成不可变类(why? see item 15)
救星是 Builder 模式。Builder 模式可以简单理解为 setter 的一个变种,它是一个链式的 setter。
比如 LPaper(docId, font, bgColor),对应的有 LPaperBuilder(docId, font, bgColor)
LPaperBuilder {
LPaperBuilder docId(arg) {
this.docId = arg; return this;
}
LPaperBuilder font(arg) {
this.font = arg; return this;
}
LPaperBuilder bgColor(arg) {
this.bgColor = arg; return this;
}
LPaper build() {
return new LPaper(this.docId, this.font, this.bgColor);
}
}
LPaper lp = LPaperBuilder.docId(1003401).font("SimHei").bgColor("red").build();
进行状态检验的时机:
- build 过程中,Builder 的字段 copy 到目标对象后,在 对象域 而不是 Builder域 中做状态检验(why? see item 39)
- 类似层叠构造器的一种变种,比如有两个字段需要满足一个特定状态,可以定义一个包含两参数的方法:
LPaperBuilder init(arg1, arg2) {
// code checking arg1 and arg2 goes here
if (OK) {
this.arg1 = arg1;
this.arg2 = arg2
return this;
} else {
throw new IllegalArgumentException();
}
}
该方法的好处是:不用等到 build 时才发现问题。
注意,此时 目标对象 可以是 不可变 的,因为可以没有 setter。
另外,Builder 很适合 抽象工厂(Abstract Factory)。可以定义一个
public interface Builder<T> {
public T build();
}
抽象工厂持有一组这样的 Builder 实现,就可以方便生产类型的对象。
item 3. 用 private constructor 或者 enum 来强化 singleton
一般的 singleton 写法有两种:
public class singlton {
public static final Singleton INSTANCE = new Singleton();
private Singleton() { ... }
...
}
public class singlton {
private static final Singleton INSTANCE = new Singleton();
private Singleton() { ... }
public static Singleton getInstance() {
return INSTANCE;
}
...
}
如果为了防止通过反射来访问 construtor,可以在 construtor 中直接抛异常(好贱啊……)。
为了防止 反序列化 重新生成一个新的 INSTANCE,需要做到:
- 将 INSTANCE 标记为
transient(意思是:”hi,这个字段是不参与序列化的,忽略它吧~”) - 覆写
readResolve()方法,直接返回 INSTANCE
随着 Java 1.5 引入 enum,现在 singleton 也能用 enum 实现了:
public enum Singleton {
INSTANCE;
// fields all go in constructor
// method goes here just like other classes
...
}
enum singleton 的优点:JVM 无偿提供的序列化机制,绝对防止 反序列化 生成新的 INSTANCE,原因是:
The serialized form of an enum constant consists solely of its name; field values of the constant are not present in the form. To serialize an enum constant,
ObjectOutputStreamwrites the value returned by the enum constant’s name method. To deserialize an enum constant,ObjectInputStreamreads the constant name from the stream; the deserialized constant is then obtained by calling thejava.lang.Enum.valueOf()method, passing the constant’s enum type along with the received constant name as arguments.
readResolve() 方法与序列化
一个常见的 序列化 与 反序列化 的调用类似于:
public Object serialize() throws IOException, ClassNotFoundException {
// 序列化
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
oos.writeObject(this);
// 反序列化
ByteArrayInputStream bais = new ByteArrayInputStream(baos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bais);
return ois.readObject();
}
序列化 和 反序列化 实际涉及到方法有4个,依次为:
Object writeReplace():替换参与 序列化 的对象,即可以让this以外的对象来 “狸猫换太子”void ObjectOutputStream.writeObject(Object obj):JVM 自带的序列化io实现Object ObjectInputStream.readObject():JVM 自带的序列化io实现Object readResolve():直接提供 反序列化 的结果,可以是readObject()的结果,也可以不是
题外话,What are writeObject() and readObject()? Customizing the serialization process
item 4. 用 private constructor 来强化 util 类
方法在 item 3 中已经说了,private construtor,保险点再加一个异常。最好加注释说明一下。
item 5. 避免创建不必要的对象
典型的例子是方法中每次都创建的 日期对象,完全可以在定义为 static field;但也没有必要用懒加载,把事情搞复杂了。
避免自动装箱 (autoboxing):比如 Long l = 0L; l++; 因为 l 声明为 Long 对象,所以每次 l++ 都会创建一个 Long 对象(详见 item 49)。
item 39. defensive copy 的场合与本 item 不同:当重用对象的代价远大于创建新对象的时候,请使用 defensive copy;与本 item 并不矛盾。
item 6. 消除过期引用
过期引用,即 obsolete reference,is simply a reference that will never be dereferenced again。
比如说你自定义一个 stack,然后 pop 操作只是 top--,那么 stack[top+1],i.e. 原 top 元素就可能成为一个 obsolete reference。
内存泄露也可称为 unintentional object retension,无意识的对象保留。如果一个对象被保留,那么它引用的对象也会被保留。
避免产生 obsolete reference 的一个最简单的做法是 object = null;(this is a kind of dereference),但刻意去做这件事情显得很别扭。最好的方法是:让引用对象结束生命周期。这要求你在最紧凑的作用域内定义变量。
内存泄露来源:
- 自己管理的内存:
- 比如自己实现的 stack
- 解决方案是:及时的 dereference
- 缓存:
- 缓存中的对象可能被遗忘
- 解决方案:
WeakHashMap: 当WeakHashMap的 key 被 GC 之后,对应的 entry 也被删除。see:- 起一个线程定时清除。
LinkedHashMap#removeEldestEntry()will be your good friend.
- 监听器和其他回调(待学习)
Understanding Weak References
Reference 有四种强度:Strong / Weak / Soft / Phantom
1. Strong Reference
我们说一个 reference 是 strong 的,表示在定义 reference 的定义域内,这个 reference 指向的 object 是无法被 GC 的,这个 object 有被称为 strongly reachable (if an object is reachable via a chain of strong references (strongly reachable), it is not eligible for garbage collection)。
2. Weak Reference
A weak reference, simply put, is a reference that isn’t strong enough to force an object to remain in memory.
You create a weak reference like this:
WeakReference<Widget> weakWidget = new WeakReference<Widget>(widget);
and then elsewhere in the code you can use weakWidget.get() to get the actual Widget object. Of course the weak reference isn’t strong enough to prevent garbage collection, so you may find (IF there are no strong references to the widget) that weakWidget.get() suddenly starts returning null.
ReferenceQueue
ReferenceQueue<Widget> refQueue = new ReferenceQueue<Widget>();
WeakReference<Widget> weakWidget = new WeakReference<Widget>(widget, refQueue);
WeakReferences are enqueued as soon as the object to which they point becomes weakly reachable. ReferenceQueue 是 WeakHashMap 的重要组成部分。
3. Soft Reference
An object which is only weakly reachable (i.e. the strongest references to it are WeakReferences) will be discarded at the next garbage collection cycle, but an object which is softly reachable 相对比较坚挺,不会那么快被 GC. 除此之外,soft reference 与 weak reference 并无差别。
实际上,只要内存够用,softly-reachable object 是不会被 GC 的。所以 soft reference 是做 cache 的好材料,因为 GCer 会帮你判断内存是否不够用而要进行 GC。
4. Phantom Reference
与 object 几乎没有关联,get() 方法永远返回 null。唯一的用户是用来 keeping track of when it gets enqueued into a ReferenceQueue, as at that point you know the object to which it pointed is dead.
IMPORTANT: The difference is in exactly when the enqueuing happens. WeakReferences are enqueued as soon as the object to which they point becomes weakly reachable. This is before finalization or garbage collection has actually happened; in theory the object could even be “resurrected” by an unorthodox finalize() method, but the WeakReference would remain dead. PhantomReferences are enqueued only when the object is physically removed from memory, and the get() method always returns null specifically to prevent you from being able to “resurrect” an almost-dead object.
Phantom Reference 的两大用处:
- 准确告知 object 被 GC
- 可以杜绝在
finalize()中使 object 复活(复活的方法比如重新创建一个 Strong Reference)
chapter 3. Methods Common to All Objects
item 8. 严格的 equals(Object) 方法
水深,多读书。
明确一点,当有子类出现时,父类的 equals() 和子类的 equals() 关系就很微妙。
假设有一个非 abstract 的父类,有两个字段,有一个子类 A,加了一个字段 a。此时子类 A 如果用父类的 equals(),那么子类间的比较会漏掉字段 a 的比较。如果子类 A 自己写一个 equals() 比较三个字段,那么子类 A 和父类的比较就很麻烦,需要慎重处理。因为要确保 子类对象.equals(父类对象) == 父类对象.equals(子类对象),如果你一定要做这样的比较的话。建议的做法是:约定哪些字段是需要比较的,哪些字段不需要比较;如果需要比较的字段都相等,可以判定两个对象相等。
如果你在 equals() 里限定 o.getClass() == this.getClass(),那么又违反了 Liskov 置换原则。考虑一个子类 B,没有加字段,那么它和父类的比较,不需要限定 class 相等。所以,还是用 instanceof 比较科学,注意,(子类对象 instanceof 父类) == true。
用组合代替继承的话,equals() 也有新的写法,如下:
class Ext {
private Base b;
private NewField nf;
public Base asBase() {
return b;
}
@Override equals (Object o) {
if (o == this) {
return true;
}
if (!(o instanceof Ext)) {
return false;
}
Ext e = (Ext) o;
return o.asBase().equals(this.asBase()) && o.getNewField().equals(this.getNewField());
}
}
float 的比较请用 Float.compare(),double 的比较请用 Double.compare()。
item 9. 覆写 equals(Object) 时请一并覆写 hashCode()
just read the book
注:工作经验告诉我们:如果自定义的 PO(的对象)会作为 HashMap 的 key,或是存放到 HashSet,请务必覆写 hashcode() 和 equals() 方法;用 eclipse 自己生成的那个就好了,绝对写得比你好
item 12. 如何覆写 compareTo()
比 equals() 简单点,compareTo() 不需要考虑子类父类的关系(考虑了也没啥意义,你会拿不同 class 的对象来排序么?),如果两个对象的 class 不同,直接让类型转换抛出 ClassCastException 好了。
需要保证的一点:如果 x.compareTo(y) == 0,那么 x.equals(y) == true。
如果父类实现了 Comparable,子类想加一个字段,最好是使用组合而不是继承(考虑 Base b1 = new Base(); Base b2 = new Ext(); list.add(b1); list.add(b2); 的情况,此时 list.sort() 是要抛 ClassCastException 的。
chapter 4. Classes and Interfaces
item 13. 关于 public class 的 public 字段
根据 1)是否final;2)是否可变,有以下四种情况:
- public non-final mutable
objobj可变,且可以指向不同的对象。过于 open,且 non-thread-safe
- public non-final immutable
objobj不可变,但可以指向不同的对象。过于 open
- public final mutable
objobj可变,但不能指向另一个对象。过于 open,且 non-thread-safe
- public final immutale
objobj不可变,且不能指向另一个对象。OK, and it’s coomon to use as static constant
按理来说,任何的 public 域都是不允许的,都是过于 open 的。public static final immutable 也不意外。但是,public static final immutable 过于 open 没有什么关系,而且,可以说它就是需要过于 open 才好被拿来用的。所以,除了 public static final immutable 外,public class 不应该有其他的 public 字段。
注意:
- “过于 open” 是 item 14. Use getter/setter in public class 的内容
- 基本类型和
String是 immutable 的 - 没有限定长度的数组引用是 mutable 的
item 14. Use getter/setter in public class
如果是包级私有类,或是私有嵌套类,你用 public 字段不用 getter/setter 是无所谓的。
如果是 public class,应该用 getter/setter,原因有:
- field access can’t be proxied
- you may want to have some event notification
- you may want to guard against race conditions
- expression languages support setters and getters
- theoretically, direct access breaks encapsulation. (If we are pedantic, setter and getter for all fields also breaks encapsulation though)
- you may want to perform some extra logic inside the setter or getter, but that is rarely advisable, since consumers expect this to follow the convention - i.e. being a simple getter/setter.
- you can specify only a setter or only a getter, thus achieving read-only, or write-only access.
item 16. 组合优于继承
对普通的具体类(concrete class)进行跨 package 的 extends 是十分危险的:
- 超类的实现可能会随着新发行版的推出而变化,破坏子类的实现。
- 超类可能会添加新的方法,破坏子类的语义。比如我子类是对超类的安全升级版,超类加了一个不经过安全检查的方法,子类也顺带不安全了。
考虑一个需求:我想知道一个 Set 中一共 add 过多少个元素。
- 可以直接
extends HashSet<E>,然后加一个计数器addCount- 每次调用
add(E e)就addCount++ - 每次调用
addAll(Collection<? extends E> c)就addCount += c.size()
- 每次调用
看着很正确是不?其实 HashSet 的 addAll() 实际调用了 add(),所以你 addCount += c.size() 的时候就加了两遍。
你大呼坑爹然后改了实现,结果下一版 HashSet 的 addAll 又不调用 add 了,你不是欲哭无泪?
为了解决这个问题,我们可以引入一个 forwarding class, who forwards Set<E>’s feature:
public class ForwardingSet<E> implements Set<E> {
private final Set<E> forwardedSet;
public ForwardingSet(Set<E> forwardedSet) {
this.forwardedSet = forwardedSet;
}
public void clear() { forwardedSet.clear(); }
public boolean contains(Object o) { return forwardedSet.contains(o); }
// ......
public boolean add(E e) { return forwardedSet.add(e); }
public boolean addAll(E eCollection<? extends E> c) { return forwardedSet.addAll(c); }
// .....
}
这么一来就屏蔽了 HashSet 的内部实现细节,我们 extends ForwardingSet,就不用关心 HashSet 的内部实现细节了,上面计数器的实现逻辑就不会随着 HashSet 的实现细节而发生变化了。
这个 extends ForwardingSet 的类我们又称为 wrapper class,而且是一个非常经典的 Decorator 模式 实现, who wrapped Set<E> and decorate it with addCount feature。
严格来说 forwarding class 不算是委托(delegation)(唔……a simple delegation example),真正意义上的 delegation 应该是这样的(参 Delegates - find out what constitutes true delegation):
Think of true delegation this way: Something sends a request to object1. object1 then forwards the request and itself to object2 – the delegate. object2 processes the request and does some work.
感觉像是这样的:
public class ForwardingClass {
private final ForwardedObject forwardedObject;
public void xxx() { forwardedObject.zzz(this); }
True Delegation 有被运用在 State Pattern 里。
模拟多重继承
假设我们有一个接口 Inf,一个骨架类 AbstractImp,一般我们会 Impl extends AbstractImp,如果不想用继承的话,可以 Impl implements Inf,一个骨架类,然后把接口的实现转发到一个内部类实例上,由这个内部类来 extends AbstractImpl。这么一来就可以把 “继承多个骨架类” 转移成 “实现多个接口”,称为 “模拟多重继承”。
其实质还是组合代替继承。
item 20. 类层次优于标签类
比如一个 Class Shape,有一个 String type,type == "circle" 时表示 Shape 是圆形,type == "rectangle" 时表示 Shape 是长方形。这样的类就是标签类(tagged class)。
标签类过于冗长,容易出错,效率低下。还是以上面的 Shape 为例,它必须要有 radius/length/width 三个 field 才能支持圆形和长方形这两种可能性,但圆形只会用到 radius 而长方形只用 length 和 width。这三个 field 也不能都标为 final,否则构造器要一次性把这三个 field 都初始化掉,这明显是不合逻辑的。
item 21. 使用函数对象表示策略
有点类似于函数指针,我们的 util 类也可以近似于一种函数对象,可以作为上层接口的参数,比如 sort(String, String, Comparator) 这样的。
这其实就是策略模式:策略模式定义了一系列的算法,将每一种算法封装起来并可以相互替换使用;策略模式让算法独立于使用它的客户应用而独立变化。
用函数对象表示策略的一般做法是:
- 声明一个接口表示策略
- 一个具体的策略实现对应一个实现类
- 如果这个策略类只被使用一次,host class 可以把策略类写成匿名内部类
- 如果这个策略类会被多次使用,host class 可以把策略类写成 private static 内部类,然后用一个 static final field 把这个策略类对象暴露出来
item 22. 优先考虑静态内部类
静态内部类的一个常见的用法是作为辅助类,把它放在内部是为了说明 “这个辅助类仅在与其外部类一起使用时才有意义”,比如 Map.Entry 和 Calculator.Operation (可以设计成内部 enum) 都是很好的例子。
非静态内部类的一个常见的用法是定义一个 Adapter。
我有一个 client 需要某个 Inf 的功能,然后恰巧有一个 OtherImpl 实现了类似的功能(这个 OtherImpl 不一定 implements Inf)但是不能直接拿来用(比如可能方法名与 Inf 定义的不同,或者参数顺序不对,或者方法返回的结果需要稍微调整一下),这时我们写一个 OtherAdapter implements Inf,然后让 OtherAdapter 去调用并修正 OtherImpl 的结果。这样 client 就只和 OtherAdapter 打交道。
而根据 OtherAdapter 与 OtherImpl 是继承还是组合,又可以分成两种 adapter pattern:
- if
OtherAdapterhasOtherImplas a member,这是 object adapter pattern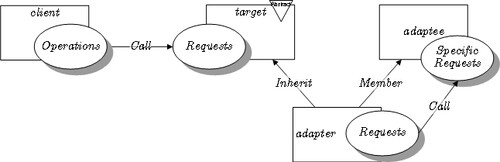
- if
OtherAdapter extends OtherImpl,这是 class adapter pattern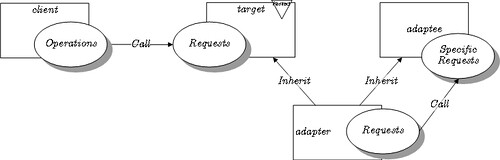
用非静态内部类来实现 adapter 的一个例子是:
public class MySet<E> extends AbstractSet<E> {
public Iterator<E> getMyIterator() {
return new MyIterator();
}
private class MyIterator implements Iterator<E> {
// 调整原有 Iterator 的功能
}
}
这里 client 是 MySet,Inf 是 Iterator<E>(target),OtherImpl 是原有的 iterator 实现(adaptee),adapter 是 MyInterator,这是个有点隐晦的 class adapter pattern,因为 MyIterator 可以通过 .this 访问到父类的 iterator。
题外话:如果可能的话,用静态内部类会更好(但这里 iterator 明显不能用静态内部类)。这是因为非静态内部类的每个实例都有一个 .this,消耗更大,而且会导致外围类在符合 GC 条件时仍然得以保留。
所以:
- 如果每个内部类实例都需要访问外围类,设计成非静态内部类
- 否则就做成静态的
另,如果内部类是在方法的内部:
- 已经有接口或是抽象类来约束它的行为(i.e. 这个内部类一定是要继承或者实现 xxx 的,我们称它的行为是被约束的),同时你只需要在一个地方创建内部类实例,设计成匿名内部类
- 否则设计成局部内部类
chapter 5. Generics
item 23. 泛型与泛型的 raw type、wildcard type
raw type
List<E> 是泛型,对应的 List 就是 List<E> 的 raw type。raw type 不做类型检查,所以是很危险的,保留它们只是为了提供移植兼容性(Migration Compatibility)。
List<Object> 虽然和 List 一样,可以 add 任意类型的对象进来,但是:
List<String> listS = new ArrayList<String>();
List list = listS; // OK, listS is a subtype of list
List<Object> listO = listS; // Type Mismatch; and actually List<Object> is not a supertype of all kinds of lists
wildcard type
List<?> 是 unbounded wildcard type;List<? extends Number> 是 bounded wildcard type。
对于 List<?> 可以这么理解:
List<Object>相当于/,根路径List<?>相当于**,可以匹配任意路径,但没有任何路径 ==**
前面有说 List<Object> is not a supertype of all kinds of lists, but List<?> is,所以 List<?> listQ = listS; 是可行的。
Wildcards 有说:
When the actual type parameter is
?, it stands for some unknown type. Any parameter we pass to add would have to be a subtype of this unknown type. Since we don’t know what type that is, we cannot pass anything in. The sole exception is null, which is a member of every type.
On the other hand, given aList<?>, we can callget()and make use of the result. The result type is an unknown type, but we always know that it is an object. It is therefore safe to assign the result ofget()to a variable of typeObjector pass it as a parameter where the typeObjectis expected.
class literal
List.class // OK
List<?>.class // error
List<String>.class // error
instanceof
listS instanceof List<?> // OK, but not necessary
listS instanceof List // OK, and then the cast "listS = (List<?>)ListS" is also OK
listS instanceof List<String> // error
item 25. 泛型优于数组
covariant and invariant
数组是 covariant(协变的),即:如果 Sub 是 Super 的子类型,那么 Sub[] 就是 Super[] 的子类型。
泛型是 invariant(不可变的),即 List<Sub> 和 List<Super> 没有任何继承关系。
Type Erasure and Reifiable Types
Type erasure is a mapping from types (possibly including parameterized types and type variables) to types (that are never parameterized types or type variables). We write
|T|for the erasure of typeT. The erasure mapping is defined as follows.
- The erasure of a parameterized type
G<T1, ... ,Tn>is|G|.- The erasure of a nested type
T.Cis|T|.C.- The erasure of an array type
T[]is|T|[].- The erasure of a type variable is the erasure of its leftmost bound.
- The erasure of every other type is the type itself.
The erasure of a method signature s is a signature consisting of the same name as s, and the erasures of all the formal parameter types given in s.
Because some type information is erased during compilation, not all types are available at run time. Types that are completely available at run time are known as reifiable types. A type is reifiable if and only if one of the following holds:
- It refers to a non-generic type declaration.
- It is a parameterized type in which all type arguments are unbounded wildcards.
- It is a raw type.
- It is a primitive type.
- It is an array type whose component type is reifiable.
注意下这个逻辑,因为泛型是 “some type information is erased during compilation”,所以为了确保能正确的 erase,compilation 会做严格的类型检查。而 Array 是 reified,所以是到 runtime 才类型检查,下面看个例子:
Object[] objectArray = new Long[1]; // covariant
objectArray[0] = "I don't fit in"; // 编译通过,运行时抛出 ArrayStoreException
List<Object> objectList = new ArrayList<Long>(); // invariant; 编译直接不通过,Type Mismatch
因为两者的 type 有本质区别,所以泛型数组是不允许的,比如 List<Object>[]、List<E>[] 这样都是不合法的,唯一的例外是 List<?>[],因为 List<?> 是 Reifiable Types。
注意:E[] 是合法的,但是 E[] elements = new E[5] 是非法的,需要 cast 一下 E[] elements = new (E[]) new Object[5]。
还有一个很好的例子请看书。
chapter 6. Enums and Annotations
item 30. 用 enum 代替 static final int
好处不言而喻,另高级用法有以下三点:
enum 可以包方法
初级写法:
public enum Operation {
PLUS, MINUS, TIMES, DIVIDE;
double apply(double x, double y) {
switch (this) {
case PLUS: return x + y;
case MINUS: return x - y;
case TIMES: return x * y;
case DIVIDE : return x / y;
default : throw new AssertionError("Unknown op: " + this);
}
}
public static void main(String[] args) {
double x = 3.0;
double y = 2.0;
System.out.println(PLUS.apply(x, y));
}
}
好,这时我要加一个 power 运算,你要改 switch;下次我要加一个 log 运算,你又要改 switch。而且除了 null,不可能有其他值去触发 default,这个 exception 你在外围是处理还是不处理呢?等等这些问题,都可以解决,因为其实可以把 enum 和方法直接联系起来。高级写法:
public enum Operation {
PLUS {
double apply(double x, double y) { return x + y; }
},
MINUS {
double apply(double x, double y) { return x - y; }
},
TIMES {
double apply(double x, double y) { return x * y; }
},
DIVIDE {
double apply(double x, double y) { return x / y; }
};
abstract double apply(double x, double y); // 必须写在 enum 常量声明完之后
public static void main(String[] args) {
double x = 3.0;
double y = 2.0;
System.out.println(PLUS.apply(x, y));
}
}
同时附带上 field 也可以:
public enum Operation {
PLUS("+") {
double apply(double x, double y) { return x + y; }
},
MINUS("-") {
double apply(double x, double y) { return x - y; }
},
TIMES("*") {
double apply(double x, double y) { return x * y; }
},
DIVIDE("/") {
double apply(double x, double y) { return x / y; }
};
private final String symbol;
private Operation(String symbol) {
this.symbol = symbol;
}
abstract double apply(double x, double y);
public static void main(String[] args) {
double x = 3.0;
double y = 2.0;
System.out.println(PLUS.apply(x, y));
}
}
正确的 fromString() 的写法
public enum Operation {
PLUS("+") {
double apply(double x, double y) { return x + y; }
},
MINUS("-") {
double apply(double x, double y) { return x - y; }
},
TIMES("*") {
double apply(double x, double y) { return x * y; }
},
DIVIDE("/") {
double apply(double x, double y) { return x / y; }
};
private final String symbol;
private Operation(String symbol) {
this.symbol = symbol;
}
abstract double apply(double x, double y);
private static final Map<String, Operation> symbolMap = new HashMap<String, Operation>();
static {
for (Operation op : Operation.values()) {
symbolMap.put(op.getSymbol(), op);
}
}
public Operation fromString(String symbol) {
return symbolMap.get(symbol);
}
public String getSymbol() {
return symbol;
}
public static void main(String[] args) {
double x = 3.0;
double y = 2.0;
System.out.println(PLUS.apply(x, y));
}
}
避免了 switch-case 和土鳖的 String.equals()。
嵌套策略枚举
其实把 enum 和方法绑定就已经形成了策略,嵌套的策略枚举是为了给 enum 再分类,将一个绑定方法的 type-enum 传给高层的 enum 的构造器,即标志了高层 enum 的 type,也赋予了高层 enum 一种策略
chapter 7. Methods
item 39. Defensive Copy
本节与 item 19 有关联。
考虑这么一个类:
public class Period {
private final Date start;
private final Date end;
}
如果我们 Date start = new Date(); Date end = new Date(); Period p = new Period(start, end); 然后 end.setYear(78),这样就破坏了 p。
这时我们可以使用 Defensive Copy:
public class Period {
private final Date start;
private final Date end;
public Period(Date start, Date end) {
this.start = new Date(start);
this.end = new Date(end);
}
}
但是 p.getEnd().setYear(78); 也可以破坏 p,我们对 getter 也可以用 Defensive Copy:
public class Period {
private final Date start;
private final Date end;
public Period(Date start, Date end) {
this.start = new Date(start);
this.end = new Date(end);
}
public Date getEnd() {
return new Date(end);
}
}
chapter 9. Exceptions
item 58. 如何区别使用 checked exception / runtime exception / error
Throwable:
- checked exception
- unchecked exception:
- runtime exception
- error
Error 常常被 JVM 保留用于表示资源不足、约束失败或者恰使程序无法继续执行的条件,所以对程序员而言,能抛出的 unchecked exception 基本就等同于 RuntimeException 了。
如果你的 API 决定抛出 checked exception,那么就表示:调用者在遇到 exception 时还是有机会恢复程序的,或是可以返回一些错误视图。
如果你的 API 决定抛出 unchecked exception,那么就表示:如果调用者真的触发了这个 unchecked exception,说明调用者违反了 API 规范(比如数组下标越界),违反了底线,程序继续执行下去有害无益,不如干脆直接给你停掉。
另外,你其实可以自己定义一个 Throwable,它可以不是 Exception、RuntimeException 或是 Error 的子类。但 JLS 指出:这样的 throwable 行为上会等同于 Exception 的子类。所以没有必要去这么做。
item 59. 如果不确定是否该用 checked exception,或许使用 unchecked exception 会更好,以及如何改写成 unchecked exception
注:感觉在实际工作中,很少抛 RuntimeException,其实主要是为了返回错误视图(很多情况下不好直接 404),不然闭着眼睛都知道 RuntimeException 要好一些,因为可以不用 try-catch 啊……不过是否该用 checked exception 这个问题还是值得考虑的,因为自己常常既是 API 提供者又是 API 使用者,让自己爽一点总是不错的。
假设原有的结构是:
try {
obj.action(args);
} catch (CheckedException e) {
// handle exception
}
如果不确定是否该用 checked exception,可以把 obj.action(args) 改成抛出 RuntimeException,然后改成下面的结构:
if (obj.actionPermitted(args)) {
obj.action(args);
} else {
// handle exceptional conditions
}
这里的 obj.actionPermitted(args) 和 obj.action(args) 就很像 iterator.hasNext() 和 iterator.next() 了。但是要注意:
- 在并发条件下,
obj.actionPermitted(args)执行后可能其他的线程会改变obj的状态,可能刚好变得 not permitted 了,所以这一段在并发条件下应该需要同步控制 - 如果
obj.actionPermitted(args)的代价非常大,比如会重复obj.action(args)的工作,那么这个重构就不值得做
item 64. 努力使对象成为 failure atomic
如果某对象的方法抛出了 exception,而对象仍然保持在一个正确的状态,则称这个对象是 failure atomic。
有以下手段可以使对象成为 failure atomic:
- 设计成不可变类,从根源上保证状态不可变
- 检查方法参数,尽量减小错误参数在方法执行过程中对对象状态的影响
- 调整代码顺序,使可能失败的计算过程在对象状态修改前执行
- 使用回滚机制(不光指 DB 层次;可以设计一段代码在 exception 发生后修正对象状态)
- 可能抛出 exception 的操作不直接作用于对象本身,而是作用在对象的一份临时 copy 上,比如
Collection.sort()会用到一个临时数组
chapter 10. Concurrency
Observer 模式
Observer 模式通常被用在 Event Handling 方面。
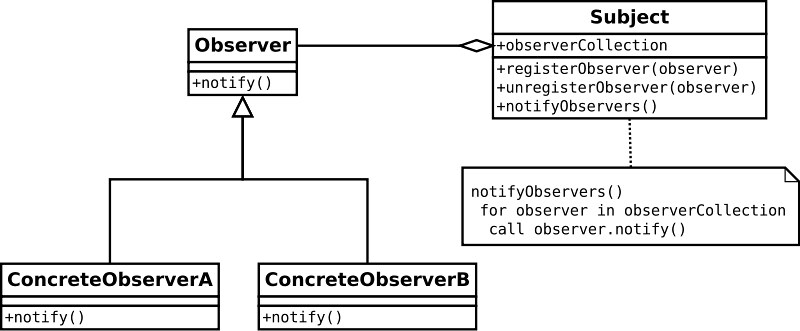
注意:
- 我觉得
Subject的方法叫notifyObservers()是 OK 的 - 但是
Observer对应的方法也叫notify()我觉得不太行,主动被动还是要分一下的吧?我宁愿麻烦一点叫receive_notification()
2014.06.16 补充:
Observer 模式还有 push 和 pull 两种模式,这是从 Subject 的角度来看的:
- push 模式:
Subject调用的是observer.receive_notification(xxx),其中xxx代表一个 message (甚至可以是Subject对象自身)- 这就相当于是
Subjectpush 一个消息给 observer;
- pull 模式:
Subject调用的是observer.receive_notification(),没有任何参数- 则 observer 需要自己去查找有哪些内容被修改的,可能要去查询
Subject的状态,这可以看做是 observer 从Subjectpull 消息。
push 模式的优缺点:
- 实现可能会复杂 (可能有多个 message 类型,每个类型都要写一个对应的方法)
- 消息精确,利于控制
pull 模式的优缺点:
- 实现简单
- 可能有并发问题 (比如多个 observer 同时去查询
Subject的状态,并做出相应的修改)
item 71. 谨慎使用 lazy initialization
首先,在大多数情况下,正常的初始化都要好于 lazy initialization。
如果出于性能考虑,要对 static field 使用 lazy initialization 的话,请使用 initialize-on-demand holder class idiom:
private static class FieldHolder {
static final FieldType field = computeFieldValue();
}
static FieldType getField() {
return FieldHolder.field;
}
当 getField() 被调用时,会引起 FieldHolder 的加载,从而开始初始化。
如果要对 non-static field 使用 lazy initialization 的话,可以使用 double-check idiom:
private volatile FieldType field;
FieldType getField() {
FieldType result = field;
if (result == null) {
synchonized(this) {
result = field;
if (result = field) {
result = field = computeFieldValue();
}
}
}
return result;
}
如果不怕多线程下可能造成的多次初始化,使用 single-check idiom 也是足够用的:
private volatile FieldType field;
FieldType getField() {
FieldType result = field;
if (result == null) {
result = field = computeFieldValue();
}
return result;
}
如果 FieldType 是 primitive 且不是 long 或者 double(即 FieldType 的读写是 atomic 的),你不用 volatile 也可以,这样就是 racy (原始的) single-check idiom。
留下评论