Ensemble Methods in Machine Learning
总结自 Ensemble Methods in Machine Learning
Abstract
Ensemble methods are learning algorithms that construct a set of classifier and then classify new data point by taking a (weighted) vote of their predictions. The original ensemble methods is Bayesian averaging, but more recent algorithms include error-correcting output coding, Bagging, and boosting. This paper reviews these methods and explains why ensembles can often perform better than any single classifier. Some previous studies comparing ensemble methods are reviewed, and some new experiments are presented to uncover the reasons that Adaboost does not overfit rapidly.
1. Introduction
We will consider only classification here rather than regression.
An ensemble of classifiers is a set of classifiers whose individual decisions are combined in some way (typically by weighted or unweighted voting) to classify new examples.
A necessary and sufficient condition for an ensemble of classifiers to be more accurate than any of its individual members is if the classifiers are accurate and diverse.
- By accurate we mean that a classifier has an error rate better than random guessing on new $x$ values.
- i.e. $p > 0.5$
- The probability that the majority vote will be wrong actually follow a binomial distribution.
- By diverse we mean that two classifiers make different errors on new data points.
- If classifiers ${h_1,h_2,h_3}$ are identical (i.e. not diverse), when $h_1(x)$ is wrong, $h_2(x)$ and $h_3(x)$ will also be wrong
It is often possible to construct very good ensembles. There are three fundamental reason for this.
Given
- search space or hypothesis space $\mathcal{H}$
- $h_n$, the hypothesis (function) provided by the $n^{th}$ classifier
- $f$, the true hypothesis (function)
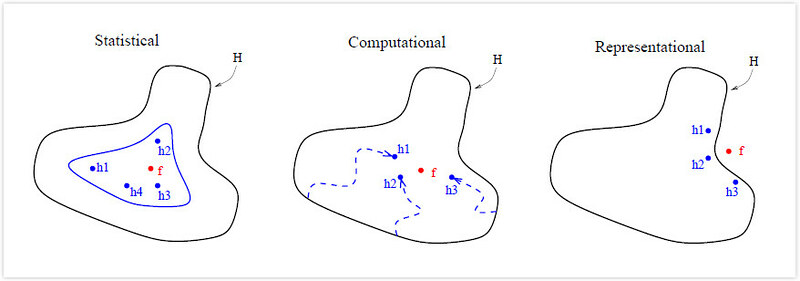
- Statistical reason: An ensemble can “average” their votes and reduce the risk of choosing the wrong classifier.
- The inner blue curve denotes the set of hypotheses that all give good accuracy on the training data.
- Computational reason: An ensemble constructed by running the local search from many different starting points may provide a better approximation to the true unknown function.
- Representational reason: In most application of machine learning, the true function $ f $ cannot be represented by any of the hypotheses in $\mathcal{H}$. By forming weighted sums of hypotheses drawn from $\mathcal{H}$, it may be possible to expand the space of representable function.
2. Methods for Constructing Ensembles
2.1 Bayesian Voting: Enumerating the Hypotheses
In a Bayesian probabilistic setting, each hypothesis $h$ defines a conditional probability distribution: $h(x) = P(y = f(x) \vert x,h)$.
- $f(x)$ is the true value
- $y$ is the predicted value (according to the value of $ h(x) $)
Given a new data point $x$ and a training sample $S$, the problem of predicting the value of $f(x)$ can be viewed as the problem of computing $P(y = f(x) \vert S,x)$.
We can rewrite this as weighted sum over all hypotheses in $\mathcal{H}$:
\[\begin{equation} P(y = f(x) \vert S,x) = \sum_{h \in \mathcal{H}}{h(x)P(h \vert S)} \end{equation}\]We can view this as an ensemble method in which the ensemble consists of all the hypotheses in $\mathcal{H}$, each weighted by its posterior probability $P(h \vert S)$.
- When the training sample is small, many $h$ will have significantly large posterior probability.
- When the training sample is large, typically only one $h$ has substantial posterior probability.
In some learning problems, it is possible to completely enumerate each $h \in \mathcal{H}$, computer $P(S \vert h)$ and $P(h)$, and evaluate $P(y = f(x) \vert S,x)$ with Bayes’ rule. The ensembles constructed in this way are called Bayesian Committees.
In complex problem where $\mathcal{H}$ cannot be enumerated, it is sometimes possible to approximate Bayesian voting by drawing a random sample of hypotheses distributed according to $P(h \vert S)$. E.g. Markov chain Monte Carlo methods.
The most idealized aspect of the Bayesian analysis is the prior belief $P(h)$. In practice, it is often very difficult to construct a space $\mathcal{H}$ and assign a prior $P(h)$ that captures our prior knowledge adequately. Indeed, often $\mathcal{H}$ and $P(h)$ are chosen for computational convenience, and they are known to be inadequate. In such cases, the Bayesian voting ensemble is not optimal. In particular, the Bayesian approach does not address the computational and representational problems in any significant way.
2.2 Manipulating the Training Examples to Generate Multiple Hypotheses
The second method for constructing ensembles is to run the learning algorithm several times, each time with a different subset of the training examples, to generate multiple hypotheses.
This technique works especially well for unstable learning algorithms–algorithms whose output classifier undergoes major changes in response to small changes in the training data.
- Decision trees, neural networks, and rule learning algorithms are all unstable.
- Linear regression, nearest neighbor, and linear threshold algorithms are generally very stable.
Here we introduce 3 detailed methods of manipulating the training data.
- Bagging: Bagging run a learning algorithm several times, each time with $m$ training examples drawn randomly with replacement from the original training set of $m$ items. Such a training set is called a bootstrap replicate of the original training set, and the technique is called bootstrap aggregation, Bagging for short. Each bootstrap replicate contains, on the average, 63.2% of the original training set.
- N-fold running: E.g. the training set can be randomly divided into 10 disjoint (不相交的) subset. Then 10 overlapping training set can be constructed by dropping out a different one of the 10 subsets. Ensembles constructed in this way are sometimes called Cross-validated Committees.
- AdaBoost: AdaBoost maintains a set of weights over the training examples. In each iteration $ \ell $, the learning algorithm is invoked to minimize the weighted error on the training set, and it returns an hypothesis $h_{\ell}$. The weighted error of $h_{\ell}$ is computed and applied to update the weights on the training examples. The effect of the change in weights is to place more weight on misclassified examples and less weight on correctly classified one. At last, a classifier weight $w_{\ell}$ is computed according to $h_{\ell}$’s accuracy, and the final classifier $h_f(x) = \sum_{\ell}{w_{\ell} h_{\ell}}$.
- AdaBoost can be viewed related to margin. See the paper for detail.
2.3 Manipulating the Input Features
For example, in a project to identify volcanoes on Venus, Cherkauer (1996) trained an ensemble of 32 neural networks, based on 8 different subsets of the 119 available input features and 4 different network sizes. The input features subsets were selected (by hand) to group together features that were based on different image processing operations (such as principle component analysis and fast Fourier transform).
Obviously, this technique only works when the input features are highly redundant.
2.4 Manipulating the Output Targets
Dietterich & Bakiri (1995) describe a technique called Error-Correcting Output Coding (ECOC). Suppose that the number of classes, $K$, is large. We randomly partitioned the $K$ classes into two subsets $A_{\ell}$ and $B_{\ell}$. Then any input data that belong to class $k \in A_{\ell}$ are relabeled 0, and others that belong to class $k’ \in B_{\ell}$ are relabeled 1. Then we can train a 0-1 classifier $h_{\ell}$ on the relabeled training data.
By repeating this process $L$ times (generating different $A_{\ell}$ and $B_{\ell}$), we obtain an ensemble of $L$ 0-1 classifiers $h_1,\cdots,h_L$.
Now given a new data point $x$. If $h_{\ell}(x) = 0$, then each class in $A_{\ell}$ receives a vote; otherwise each class in $B_{\ell}$ receives a vote. After each of the $L$ classifiers has voted, the class with the highest votes is selected as the prediction.
这个方法也可以用 encoding 的方式来解读,具体见 paper.
2.5 Injecting Randomness
这个很好理解,需要人工选择的地方,全部用随机就好了。
3. Comparing Different Ensemble Methods
前面讲了 ensemble 比 individual 好的原因有 Statistical、Computational 和 Representational 三个方面,换个说法就是 ensemble 相比 individual 解决了 Statistical、Computational 和 Representational 这三个方面的问题。在比较 ensemble 的时候可以用这个观点来阐述,因为有的 ensemble 只解决了一个问题,有的解决了两个 etc.
overfitting 也和这几个问题有关。
还有些比较的结果是由于算法自身的其他性质造成的。
具体见 papar。
4. Conclusions
Omitted here.
留下评论