Digest of ggplot2
第一章 - 简介
1.1 Welcome to ggplot2
… it has a deep underlying grammar. This grammar, based on the Grammar of Graphics (Wilkinson, 2005), is composed of a set of independent components that can be composed in many different ways. This makes ggplot2 very powerful, because you are not limited to a set of pre-specified graphics, but you can create new graphics that are precisely tailored for your problem.
ggplot2 is designed to work in a layered fashion, starting with a layer showing the raw data then adding layers of annotations and statistical summaries. It allows you to produce graphics using the same structured thinking that you use to design an analysis, reducing the distance between a plot in your head and one on the page.
1.3 What is the grammar of graphics?
In brief, the grammar tells us that a statistical graphic is a mapping from data to aesthetic attributes (colour, shape, size) of geometric objects (points, lines, bars).
The first description of the components follows below:
- geoms: Geometric objects
- 其实是指图像类型 (scatterplot, smooth, histogram, boxplot, etc.)
- data: What you want to visualise
- facet: how to break up the data into subsets and how to display those subsets as small multiples.
- a.k.a conditioning or latticing/trellising.
- facet: [ˈfæsɪt]
- [verb] to cut facets on
- [noun] one of the small, polished plane surfaces of a cut gem
- stats: Statistical transformations, which summarise data in many useful ways.
- E.g. binning and counting observations to create a histogram
- E.g. summarising a 2d relationship with a linear model
- Stats are optional, but very useful.
- facet: how to break up the data into subsets and how to display those subsets as small multiples.
- aesthetic mappings: describles how variables in the data are mapped to aesthetic attributes that you can perceive.
- 具体的执行是靠 scales
- 比如我们常用的
colour=?是一个 scale,size=?是一个 scale,shape=?也是一个 scalex=?和y=?其实也是 scale
- scale 可以做两个方向的 mapping:
- $f$: data space $\rightarrow$ aesthetic space
- 比如给 dot 上颜色
- $f^{-1}$ (inverse): aesthetic space $\rightarrow$ data space
- 比如画颜色的 legend
- $f$: data space $\rightarrow$ aesthetic space
- 比如我们常用的
- 具体的执行是靠 scales
- coord: A coordinate system, describes how data coordinates are mapped to the plane of the graphic.
- We normally use a Cartesian coordinate system, but a number of others are available, including polar coordinates and map projections.
It is also important to talk about what the grammar doesn’t do:
- It doesn’t suggest what graphics you should use to answer the questions you are interested in.
- Ironically, the grammar doesn’t specify what a graphic should look like. The finer points of display, for example, font size or background colour, are not specified by the grammar. In practice, a useful plotting system will need to describe these, as
ggplot2does with its theming system. - It does not describe interaction: the grammar of graphics describes only static graphics.
1.4 How does ggplot2 fit in with other R graphics?
- Base graphics has a pen-on-paper model: you can only draw on top of the plot, you cannot modify or delete existing content.
- Grid graphics have a system of viewports (each containing its own coordinate system) that makes it easier to lay out complex graphics.
- The
latticepackage uses grid graphics to implement the trellis graphics system and is a considerable improvement over base graphics.- However, lattice graphics lacks a formal model, which can make it hard to extend.
ggplot2is an attempt to take the good things about base and lattice graphics and improve on them with a strong underlying model which supports the production of any kind of statistical graphic.- Like
lattice,ggplot2uses grid to draw the graphics, which means you can exercise much low-level control over the appearance of the plot.
- Like
第二章 - 从 qplot 入门
2.2 diamonds / dsmall 数据集
> library(ggplot2)
>
> head(diamonds)
carat cut color clarity depth table price x y z
1 0.23 Ideal E SI2 61.5 55 326 3.95 3.98 2.43
2 0.21 Premium E SI1 59.8 61 326 3.89 3.84 2.31
3 0.23 Good E VS1 56.9 65 327 4.05 4.07 2.31
4 0.29 Premium I VS2 62.4 58 334 4.20 4.23 2.63
5 0.31 Good J SI2 63.3 58 335 4.34 4.35 2.75
6 0.24 Very Good J VVS2 62.8 57 336 3.94 3.96 2.48
>
> set.seed(1410) # Make the sample reproducible
> dsmall <- diamonds[sample(nrow(diamonds), 100), ]
2.3 基本用法
Simple xy-scatterplots:
qplot(x = carat, y = price, data = diamonds)
## OR equivalently ##
qplot(x = diamonds$carat, y = diamonds$price)
Using the data argument is recommended: it’s a good idea to keep related data in a single data frame.
Because qplot() accepts functions of variables as arguments, we can plot log(price) vs. log(carat):
qplot(log(carat), log(price), data = diamonds)
Arguments can also be combinations of existing variables:
qplot(carat, x * y * z, data = diamonds)
2.4 图形属性 (aesthetic attributes, e.g. color, size and shape)
With plot, it’s your responsibility to convert a categorical variable in your data (e.g., “apples”, “bananas”, “pears”) into something that plot knows how to use (e.g., “red”, “yellow”, “green”). qplot can do this for you automatically, and it will automatically provide a legend that maps the displayed attributes to the data values.
qplot(carat, price, data = dsmall, colour = color) # or `color = color`
qplot(carat, price, data = dsmall, shape = cut)
qplot(carat, price, data = dsmall, size = x * y * z)
colour, size and shape are all examples of aesthetic attributes, visual properties that affect the way observations are displayed.
For every aesthetic attribute, there is a function, called a scale, which maps data values to valid values for that aesthetic. It is this scale that controls the appearance of the points and associated legend. For example, in the above plots, the colour scale maps J to purple and F to green.
scale 有默认实现。You can also manually set the aesthetics using I(), e.g., colour = I("red") or size = I(2).
注意:这里 I(x) 的作用是 “to inhibit interpretation or conversion of x“,也可以描述为 “indicate that x should be treated as-is”。具体是实现是 "AsIs" <- attr(x, "class")。那么不用 I() 会导致什么后果呢?比较下面两句:
qplot(carat, price, data = dsmall, colour = I("blue")) # (1)
qplot(carat, price, data = dsmall, colour = "blue") # (2)
- (1) 句的
"blue"没有被 interpret,所以所有的 data point 都是蓝色 - (2) 句的
"blue"有被 interpret,所以所有的 data point 显示出来的是……浅红色- 这个浅红色其实是
colour = color的 legend 的第一个颜色
- 这个浅红色其实是
For large datasets, like the diamonds data, semi-transparent points are often useful to alleviate some of the overplotting. To make a semi-transparent colour you can use the alpha aesthetic, which takes a value between 0 (completely transparent) and 1 (complete opaque). It’s often useful to specify the transparency as a fraction, e.g., 1/10 or 1/20, as the denominator specifies the number of points that must overplot to get a completely opaque colour.
qplot(carat, price, data = diamonds, alpha = I(1/10))
qplot(carat, price, data = diamonds, alpha = I(1/100))
qplot(carat, price, data = diamonds, alpha = I(1/200))
Different types of aesthetic attributes work better with different types of variables:
colourandshapework well with categorical variables,- while
sizeworks better with continuous variables.
The amount of data also makes a difference:
- If there is a lot of data, it can be hard to distinguish the different groups.
- An alternative solution is to use faceting.
2.5 几何对象 (geom)
qplot is not limited to scatterplots, but can produce almost any kind of plot by varying the geom.
For 2d data $(X, Y)$:
geom = "point": scatterplot. This is the default when you doqplot(x=?, y=?).geom = "smooth": fits a smoother to the data and displays the smooth and its standard error.geom = "boxplot": box-and-whisker plot.geom = "path"orgeom = "line": draw lines between the data points.- Traditionally used for time series data.
- A line is constrained to travel from left to right, while paths can go in any direction.
For 1d data $X$:
- For continuous variables:
geom = "histogram": histogram, the default when you doqplot(x=?).geom = "freqpoly": frequency polygon. 类似 histogram,不过是曲线geom = "density": density plot
- For discrete variables:
geom = "bar": bar chart.- histogram 是先分 bin,然后统计落到每个 bin 的数量。所以 histogram 用于 continuous variable
- discrete variable 不需要分 bin,直接统计每一个具体值的数量就可以了。所以在形状上这两个图有点类似。
2.5.1 添加 smooth 曲线
qplot(carat, price, data = dsmall, geom = c("point", "smooth"))
qplot(carat, price, data = diamonds, geom = c("point", "smooth"))
If you want to turn the confidence interval off, use se = FALSE.
There are many different smoothers you can choose between by using the method argument:
method = "loess": local regression, the default for small $n$.- More details about the algorithm used can be found in
?loess. - The wiggliness of the line is controlled by the
spanparameter, which ranges from 0 (exceedingly wiggly) to 1 (not so wiggly). - Loess does not work well for large datasets (it’s $O(n^2)$ in memory), and so alternatively
method = "gam"is used when $n$ is greater than 1,000.
- More details about the algorithm used can be found in
qplot(carat, price, data = dsmall, geom = c("point", "smooth"), span = 0.2)
qplot(carat, price, data = dsmall, geom = c("point", "smooth"), span = 1)
method = "gam"- You need to load
mgcv(Mixed GAM Computation Vehicle) library first to import formulasfor the common usagemethod = "gam", formula = y ~ s(x).- This is similar to using a spline with
lm, but the degree of smoothness is estimated from the data.
- This is similar to using a spline with
- For large data, use the formula
y ~ s(x, bs = "cs"). This is the extact default behavior for $n > 1000$.bs = "cs"specifies a shrinkage version ofbs = "cr", the cubic regression.
- You need to load
## Obsolete ##
# library(mgcv)
# qplot(carat, price, data = dsmall, geom = c("point", "smooth"), method = "gam", formula = y ~ s(x))
# qplot(carat, price, data = dsmall, geom = c("point", "smooth"), method = "gam", formula = y ~ s(x, bs = "cs"))
method = "lm"- default: straight line
formula = y ~ poly(x, 2): degree 2 polynomiallibrary(splines); formula = y ~ ns(x, 2): natural spline.2is the degrees of freedom: a higher number will create a wigglier curve.- etc.
## Obsolete ##
# library(splines)
# qplot(carat, price, data = dsmall, geom = c("point", "smooth"), method = "lm")
# qplot(carat, price, data = dsmall, geom = c("point", "smooth"), method = "lm", formula = y ~ ns(x,5))
method = "rlm"- In
MASSpackage. - Robust in that outliers don’t affect the fit as much.
- In
注:method 和 formula 已经不再是 qplot() 的参数了,如果要画出上述几个 smooth,可以用 stat_smooth
p <- ggplot(dsmall, aes(x = carat, y = price)) + geom_point()
p + stat_smooth(method = "loess", formula = y ~ x, size = 1)
p + stat_smooth(method = "lm", formula = y ~ x, size = 1)
p + stat_smooth(method = "lm", formula = y ~ x + I(x^2), size = 1)
p + stat_smooth(method = "lm", formula = y ~ poly(x, 2), size = 1)
require(mgcv)
p + stat_smooth(method = "gam", formula = y ~ s(x), size = 1)
p + stat_smooth(method = "gam", formula = y ~ s(x, k = 3), size = 1)
更多内容可以参考 How can I explore different smooths in ggplot2?。
2.5.2 jitter plot 与 boxplot
When a set of data includes a categorical variable and one or more continuous variables, you will probably be interested to know how the values of the continuous variables vary with the levels of the categorical variable. Boxplots and jittered points offer two ways to do this.
也就是,将 data point 按 categorical variable 分类:
- $x$-axis 是分类
- $y$-axis 是 continuous variable 的值
geom = "jitter": jitteringgeom = "boxplot": box-and-whisker plot
qplot(color, price / carat, data = diamonds, geom = "jitter", alpha = I(1 / 5))
qplot(color, price / carat, data = diamonds, geom = "jitter", alpha = I(1 / 50))
qplot(color, price / carat, data = diamonds, geom = "jitter", alpha = I(1 / 200))
Another way to look at conditional distributions is to use faceting to plot a separate histogram or density plot for each value of the categorical variable.
2.5.3 histogram 与 density plot
Histogram and density plots show the distribution of a single variable.
qplot(carat, data = diamonds, geom = "histogram")
qplot(carat, data = diamonds, geom = "density")
- For the density plot, the
adjustargument controls the degree of smoothness (high values ofadjustproduce smoother plots). - For the histogram, the
binwidthargument controls the amount of smoothing by setting the bin size.- Break points can also be specified explicitly, using the
breaksargument.
- Break points can also be specified explicitly, using the
qplot(carat, data = diamonds, geom = "histogram", binwidth = 1, xlim = c(0,3))
qplot(carat, data = diamonds, geom = "histogram", binwidth = 0.1, xlim = c(0,3))
qplot(carat, data = diamonds, geom = "histogram", binwidth = 0.01, xlim = c(0,3))
另外注意 histogram 的 $y$-axis 默认是 count,可以改成 density:
# histogram 默认情况是用 stat_bin 的 ..count.. 输出
qplot(x = carat, y = ..count.., data = diamonds, geom = "histogram")
## OR equivalently ##
qplot(carat, ..count.., data = diamonds, geom = "histogram")
# 可以改用 stat_bin 的 ..density.. 输出
qplot(carat, ..density.., data = diamonds, geom = "histogram")
2.5.4 Bar charts
- 基本用法:对每一个 $x_i$,计算 $y_i = nrow(df[X == x_i,])$
- 扩展用法:对每一个 $x_i$,计算 $y_i = sum(df[X == x_i,]\$foo)$
- 这里
foo通过weight = foo来指定
- 这里
qplot(color, data = diamonds, geom = "bar")
qplot(color, data = diamonds, geom = "bar", weight = carat) + scale_y_continuous("carat") # 按 color 分组,统计各组的 carat 之和
qplot(color, data = diamonds, geom = "bar", weight = x*y*z) + scale_y_continuous("volumn") # 按 color 分组,统计各组的 x*y*z 之和
scale_y_continuous 表示 “我需要一个 continuous 的 $y$-axis”.
2.5.5 Time series with line and path plots
其实这两个图不一定非要用于 time series。简单来说,这两个图的画法就是:在 scatterplot $n$ 个 data point $p_1,\dots,p_n$ 的过程中,将 $p_1 \rightarrow p_2 \rightarrow \dots \rightarrow p_n$ 在坐标系内按顺序连起来。区别在于:
- line plot 会将 data point 按 $x$ 排序。如果 $x$-axis 是时间,那就正好反映了 how $y$ has changed over time
- path plot 不会排序,完全按照 appear in dataset 的顺序来,所以它反映的是 how $x$ and $y$ have simultaneously changed
qplot(carat, price, data = dsmall, geom = c("point", "line"))
## Time Series using `ecnomics` dataset ##
qplot(date, unemploy / pop, data = economics, geom = "line") # unemploy / pop = unemployment rate
qplot(date, uempmed, data = economics, geom = "line") # uempmed = median number of weeks unemployed
year <- function(x) as.POSIXlt(x)$year + 1900
qplot(unemploy / pop, uempmed, data = economics, geom = c("point", "path"))
qplot(unemploy / pop, uempmed, data = economics, geom = "path", colour = year(date)) + scale_area()
2.6 分面 (facet)
Faceting creates tables of graphics by splitting the data into subsets and displaying the same graph for each subset in an arrangement that facilitates comparison.
The default faceting method in qplot() creates plots arranged on a grid specified by a faceting formula which looks like row_var ~ col_var. 简单说,
x ~ y的意思就是把dfgroup bydf$xanddf$yx + y ~ z的意思就是把dfgroup bydf$x,df$yanddf$z
所有出现在 formula 里的 column name 都是 group by 的标准,出现在 ~ 左边或是右边的区别在于,以 x ~ y 为例:
- 最终的 grid plot 按
~左边的 column name,i.e.df$x的值排列 row - 最终的 grid plot 按
~右边的 column name,i.e.df$y的值排列 column
而 . 是一个 place holder,表示 “我没有 column name 需要指定在 formula 的这一边”,也就是 “我只要 1 row 或者 1 column”。比较下面两句:
qplot(carat, data = diamonds, facets = color ~ ., geom = "histogram", binwidth = 0.1, xlim = c(0, 3)) # Grid Plot 1
qplot(carat, data = diamonds, facets = . ~ color, geom = "histogram", binwidth = 0.1, xlim = c(0, 3)) # Grid Plot 2
这两句的逻辑是:
- 把
diamonds按diamonds$color分成 7 个 subset (因为 color 有 7 种取值) - 对每一个 subset 画
diamonds$carat的 histogram - 然后我把这 7 个 histogram 放到一个 grid plot 里
- Grid Plot 1 是 $7 \times 1$ 排列
- Grid Plot 2 是 $1 \times 7$ 排列
2.7 Other options for qplot
xlim = c(a,b): 必须是一个 length 2 vector,表示 “$x$-axis 只要画[a,b]这一段就好了”,如果[a,b]范围之外还有点或者线,直接截掉。一般是先在草图里确定了 $x$-axis 的有效范围后再指定ylim = c(a,b): 同上
log = "y": 表示 “$y$-axis 的 scale 换成 $\log_{10}$ 值,但是 axis mark 不变”- 你比较一下这两句就明白了:
qplot(x = c(1,2,3), y = log10(c(10,100,1000)))qplot(x = c(1,2,3), y = c(10,100,1000), log="y")
log = "x": 同上log = "xy": $x$-axis 和 $y$-axis 都做这个处理,尼玛这个语法我是万万没想到……
- 你比较一下这两句就明白了:
main = "plot title": 例子已经说明一切main = expression(beta[1] == 1)给出的 plot title 是 “$\beta_1 = 1$”,注意一定要是==- See
?plotmathfor more
xlab = "x-axis label": 例子已经说明一切- 同
main一样,也可以用 expression ylab同上
- 同
几个综合运用的例子:
qplot(carat, price, data = dsmall, xlab = "Price ($)", ylab = "Weight (carats)", main = "Price-weight relationship")
qplot(carat, price/carat, data = dsmall, xlab = "Weight (carats)", ylab = expression(frac(price,carat)), main="Small diamonds", xlim = c(.2,1))
qplot(carat, price, data = dsmall, log = "xy")
第三章 - 语法突破
3.2 mpg 数据集
这一章我们使用 mpg 这个 dataset:
> library(ggplot2)
> head(mpg)
manufacturer model displ year cyl trans drv cty hwy fl class
1 audi a4 1.8 1999 4 auto(l5) f 18 29 p compact
2 audi a4 1.8 1999 4 manual(m5) f 21 29 p compact
3 audi a4 2.0 2008 4 manual(m6) f 20 31 p compact
4 audi a4 2.0 2008 4 auto(av) f 21 30 p compact
5 audi a4 2.8 1999 6 auto(l5) f 16 26 p compact
6 audi a4 2.8 1999 6 manual(m5) f 18 26 p compact
displ: the engine displacement in litres, 排量fl: fuele: E85, 85% ethanol ([ˈɛθəˌnɔl], 乙醇) + 15% gasolined: diesel ([ˈdizəl], 柴油)r: regularp: premiumc: CNG, Compressed Natural Gas
3.3 散点图绘制的详细过程
qplot(displ, hwy, data = mpg, colour = factor(cyl))
But what is going on underneath the surface? How does ggplot2 draw this plot?
- Mapping aesthetics to data
- 上图我们没有指定 size 和 shape,我们说 “Size and shape are not mapped to variables, but remain at their default values.”
- 这个 mapping 相当创建了一个 mapped dataframe,在我们的例子中,它有三列:
mdf$x:=mpg$displmdf$y:=mpg$hwymdf$color:=factor(mpg$cyl)
- Scaling
- Convert the mapped dataframe from data units to physical units (e.g. pixels and colors) that computer can display.
- 我们说:”we have three aesthetics that need to be scaled: horizontal position (
x), vertical position (y) andcolour.” - 负责完成这项工作的对象我们称为
scales- A scale is a function, and its inverse.
- function 负责转换
- inverse 负责 axis marks 和 legends
- A scale is a function, and its inverse.
- 我们说:”we have three aesthetics that need to be scaled: horizontal position (
- Scaling position is easy in this example because we are using the default linear scales.
- We need only a linear mapping from the range of the data to [0, 1], 这是
ggplot2的底层 drawing system,grid, 要求的
- We need only a linear mapping from the range of the data to [0, 1], 这是
- Convert the mapped dataframe from data units to physical units (e.g. pixels and colors) that computer can display.
- 有了 scaled mapped dataframe,现在就可以开始画了:
- Coordinate system,
coord, 负责:- 确定每个 scaled $(x,y)$ 在画出来的图中的位置;
- 画 axes
- In most cases this will be Cartesian coordinates, but it might be polar coordinates, or a spherical projection used for a map.
- 画 legends
- 最后添加 plot annotation,包括 background、title、axis labels 等等
- Coordinate system,
3.4 更复杂的图形示例
qplot(displ, hwy, data=mpg, facets = . ~ year) + geom_smooth()
3.5 图层 (layer) 的组件
The layered grammar defines a plot as the combination of:
- Data
- Mappings from variables to aesthetics
- One or more layers, each composed of
- a
geom, - a
stat, - a
positionadjustment (See 4.8), - and optionally (因为一般可以继承自原有的,所以不需要特别指定,比如我们的
geom_smooth()就没有指定,但它还是知道哪个是x哪个是y),- Data
- Mappings from variables to aesthetics
- a
- One
scalefor each aesthetic mapping. - A coordinate system (
coord) - Faceting specification
举个例子:
ggplot(mpg, aes(hwy, cty)) + # data and mapping
geom_point(aes(color = cyl)) + # layer
geom_smooth(method ="lm") + # layer
coord_cartesian() + # coord
scale_color_gradient() + # scale
theme_bw() # additional elements
你可以简单认为每个 geom_*() 或者 stat_*() 函数都是一个 layer。
我们接下来的章节:
- Chapter 4: properties of layers
- Chapter 5: how layers are used to visulize data
- Chapter 6: scales
- Chapter 7: coordinate system + faceting
- Chapter 8: plot-specific theme options
3.6 ggplot 对象
A ggplot object is a list with components data, mapping (the default aesthetic mappings), layers, scales (functions carrying out mapping), coordinates, facet and options.
> p <- qplot(displ, hwy, data = mpg, colour = factor(cyl))
>
> p # 隐式 render to screen
> print(p) # 显式 render to screen
>
> summary(p)
data: manufacturer, model, displ, year, cyl, trans, drv, cty, hwy, fl,
class [234x11]
mapping: colour = factor(cyl), x = displ, y = hwy
faceting: facet_null()
-----------------------------------
geom_point:
stat_identity:
position_identity: (width = NULL, height = NULL)
>
> save(p, file = "plot.rdata") # Save object to disk
>
> load("plot.rdata") # Load object from disk
>
> ggsave("plot.png", width = 5, height = 5) # Save png to disk
第四章 - 用图层构建图像
+ <<<<< 2018-11-29 补充:
R for Data Science 提到:
ggplot(data = <DATA>, mapping = aes(<MAPPINGS>)) + <GEOM_FUNCTION>(data = <DATA>, mapping = aes(<MAPPINGS>))
ggplot里的data和mapping是 plot-global 的,geom里的data和mapping是 geom-local 的,你不写就默认全盘使用 global;写了就是在geom范围内用 local 覆盖掉 global 相应的部分。这样在有多个geom时就可以灵活组合。比如:
ggplot(data = mpg, mapping = aes(x = displ, y = hwy)) + geom_point(mapping = aes(color = class)) + geom_smooth(data = filter(mpg, class == "subcompact"), se = FALSE)
+ 补充结束 >>>>>
4.2 创建 ggplot 对象
When we used qplot(), it did a lot of things for us: it created a ggplot object, added layers, and displayed the result, using many default values along the way.
To create the ggplot object ourselves, we use ggplot(). It has two arguments: data and aesthetic mapping
- These 2 arguments set up defaults for the plot and can be omitted if you specify data and aesthetics when adding layers later.
p <- ggplot(diamonds, aes(carat, price, colour = cut))
This ggplot object cannot be displayed until we add a layer: there is nothing to see!
4.3 添加图层 (layer)
A minimal scatterplot layer:
p <- p + layer(geom = "point")
Now it can be rendered!
A more fully specified layer can take any or all of these arguments:
layer(geom, geom_params, stat, stat_params, data, mapping, position)
Here is what a more complicated call looks like. It produces a histogram coloured “steelblue” with a bin width of 2:
p <- ggplot(diamonds, aes(x = carat))
p <- p + layer(
geom = "bar",
geom_params = list(fill = "steelblue"),
stat = "bin",
stat_params = list(binwidth = 2)
)
p
This layer specification is precise but verbose. We can simplify it by using shortcuts:
p <- ggplot(diamonds, aes(x = carat))
p <- p + geom_histogram(binwidth = 2, fill = "steelblue")
p
qplot object 也可以添加 layer:
qplot(sleep_rem / sleep_total, awake, data = msleep, geom = c("point", "smooth"))
## OR equivalently ##
qplot(sleep_rem / sleep_total, awake, data = msleep) + geom_smooth()
## OR equivalently ##
ggplot(msleep, aes(sleep_rem / sleep_total, awake)) + geom_point() + geom_smooth()
Layers are regular R objects and so can be stored as variables, making it easy to write clean code that reduces duplication:
bestfit <- geom_smooth(method = "lm", se = F, colour = alpha("steelblue", 0.5), size = 2)
qplot(sleep_rem, sleep_total, data = msleep) + bestfit
qplot(awake, brainwt, data = msleep, log = "y") + bestfit
qplot(bodywt, brainwt, data = msleep, log = "xy") + bestfit
4.4 ggplot(data=?) 参数设置
The data parameter must be a data frame and this is the only restriction.
This restriction also makes it very easy to produce the same plot for different data: you can update your current data frame and pass it to your ggplot object via %+% operator:
p <- ggplot(mtcars, aes(mpg, wt, colour = cyl)) + geom_point()
p
mtcars <- transform(mtcars, mpg = mpg ^ 2)
p %+% mtcars
Any change of values or dimensions is legitimate. However, if a variable changes from discrete to continuous (or vice versa), you will need to change the default scales.
It is not necessary to specify a default dataset except when using faceting; faceting is a global operation (i.e., it works on all layers).
The data data frame is stored in the ggplot object as a copy, not a reference. This has two important consequences:
- if your data changes, the plot will not;
- and ggplot2 objects are entirely self-contained so that they can be
save()d to disk and laterload()ed and plotted without needing anything else from that session.
4.5 ggplot(mapping=aes(...)) 参数设置
The aes function takes a list of aesthetic-variable pairs like these:
aes(x = weight, y = height, colour = age)
Note that functions of variables can be used:
aes(x = weight, y = height, colour = sqrt(age))
4.5.1 aes 的扩展、覆盖、移除
The default aesthetic mappings can be set when the plot is initialised or modified later using +:
p <- ggplot(mtcars)
p <- p + aes(wt, hp)
The default mappings in the plot p can be extended, overridden or removed in the layers:
p + geom_point(aes(colour = factor(cyl))) # extend
p + geom_point(aes(y = disp)) # override
p + geom_point(aes(y = NULL)) # remove
4.5.2 图形属性:设定 (setting) 与映射 (mapping) 的区别
注意 aes 是 “map an aesthetic to a variable”,不用 aes 的时候我们可以 “set an aesthetic to a constant”:
p <- ggplot(mtcars, aes(mpg, wt))
p + geom_point(colour = "darkblue") # OK
p + geom_point(aes(colour = "darkblue")) # Wrong!
后面一句的错误在于:它是 maps (not sets) the colour to the value “darkblue”. This effectively creates a new variable containing only the value “darkblue” and then maps colour to that new variable. Because this value is discrete, the default colour scale uses evenly spaced colours on the colour wheel, and since there is only one value, this colour is pinkish.
qplot 里我们可以用 I() 来 set:
qplot(mpg, wt, data = mtcars, colour = I("darkblue"))
但是 we CANNOT use aes(colour = I("darkblue"))。
4.5.3 分组: aes(group=?)
We use Oxboys dataset in nlme library here for demostration. It records the heights (height) and centered ages (age) of 26 boys (Subject), measured on nine occasions (Occasion).
> library(nlme)
> head(Oxboys, n=18)
Subject age height Occasion
1 1 -1.0000 140.5 1
2 1 -0.7479 143.4 2
3 1 -0.4630 144.8 3
4 1 -0.1643 147.1 4
5 1 -0.0027 147.7 5
6 1 0.2466 150.2 6
7 1 0.5562 151.7 7
8 1 0.7781 153.3 8
9 1 0.9945 155.8 9
10 2 -1.0000 136.9 1
11 2 -0.7479 139.1 2
12 2 -0.4630 140.1 3
13 2 -0.1643 142.6 4
14 2 -0.0027 143.2 5
15 2 0.2466 144.0 6
16 2 0.5562 145.8 7
17 2 0.7781 146.8 8
18 2 0.9945 148.3 9
给每个 boy 画一条 age-height 的连线图 (由 9 个点连接而成):
p <- ggplot(Oxboys, aes(age, height, group = Subject)) + geom_line()
注意这会产生 26 条曲线,而且是画在同一个坐标轴里的。而 facet = . ~ Subject 是分成了 26 个坐标轴,每个坐标轴里只有一条曲线,注意区别。
默认情况下,没有分组时相当于 aes(group = 1)。
在这 26 条曲线的基础上,再加一条整个数据集的 smooth:
p + geom_smooth(aes(group = 1), method="lm", size = 2, se = F)
注意,要画整个数据集的 smooth,我们要覆盖掉之前的 group 设定。这从另外一个角度说明,我们对不同的 layer,可以有不同的 group 设定。
4.5.4 匹配图形属性与图形对象
Stacked bar chart:
p <- ggplot(diamonds, aes(x = color, color=cut, fill=cut)) + geom_bar()
4.6 几何对象 (geom)
geom 列表:
| geom_* | Description | 描述 |
|---|---|---|
| abline | Line, specified by slope and intercept | 斜线 |
| area | Area plots | 面积图(联系微积分) |
| bar | Bars, rectangles with bases on y-axis | 条形图 |
| bin2d | 2d heat map | 二维热图 |
| blank | Blank, draws nothing | |
| boxplot | Box-and-whisker plot | 箱线图 |
| contour | Display contours of a 3d surface in 2d | 等高线图 |
| crossbar | Hollow bar with middle indicated by horizontal line | 带有水平中心线的盒子图(类似只有 box 的 boxplot) |
| density | Display a smooth density estimate | 光滑密度曲线图 |
| density2d | Contours from a 2d density estimate 二维密度等高线图 | |
| errorbar | Error bars | 误差棒(类似只有 box 顶和底的 boxplot) |
| histogram | Histogram | 直方图 |
| hline | Line, horizontal | 水平线 |
| interval | Base for all interval (range) geoms | |
| jitter | Points, jittered to reduce overplotting | 本质是个 scatterplot,dots 被添加扰动,减少重叠 |
| line | Connect observations, in order of $x$ value | 按 $x$-axis 的顺序连接各个点 |
| linerange | An interval represented by a vertical line | 一条竖线,表示 $y$-axis 的一个区间 |
| path | Connect observations, in original order | 与 line 不同,path 是按数据的原始 $x$ 顺序连接各个点 |
| point | Points, as for a scatterplot | 散点图 |
| pointrange | An interval represented by a vertical line, with a point in the middle | 在 linerange 的基础上,在中点处添加一个 dot |
| polygon | Polygon, a filled path | 多边形,相当于一个有填充的 path |
| quantile | Add quantile lines from a quantile regression | 分位数回归线 |
| ribbon | Ribbons, $y$ range with continuous $x$ values | 色带图 |
| rug | rug plots in the margins | 边界地毯图 |
| segment | Single line segments | 线段(可带箭头) |
| smooth | Add a smoothed condition mean | 光滑的条件均值线 |
| step | Connect observations by stairs | 类似方波信号图 |
| text | Textual annotations | |
| tile | geom_rect and geom_tile do the same thing (其实都是 heat map), but are parameterised differently geom_rect uses the locations of the four corners (xmin, xmax, ymin and ymax), while geom_tile uses the center of the tile and its size (x, y, width, height) |
瓦片图 |
| vline | Line, vertical | 垂直线 |
geom aes 参数:
| Name | Default Stat | Required Aesthetics | Optional Aesthetics |
|---|---|---|---|
| abline | abline | colour, linetype, size | |
| area | identity | x, y | colour, fill, linetype, size |
| bar | bin | x | colour, fill, linetype, size, weight |
| bin2d | bin2d | xmax, xmin, ymax, ymin | colour, fill, linetype, size, weight |
| blank | identity | ||
| boxplot | boxplot | lower, middle, upper, ymax, ymin | colour, fill, size, weight, x |
| contour | contour | x, y | colour, linetype, size, weight |
| crossbar | identity | x, y, ymax, ymin | colour, fill, linetype, size |
| density | density | x, y | colour, fill, linetype, size, weight |
| density2d | density2d | x, y | colour, linetype, size, weight |
| errorbar | identity | x, ymax, ymin | colour, linetype, size, width |
| freqpoly | bin | colour, linetype, size | |
| hex | binhex | x, y | colour, fill, size |
| histogram | bin | x | colour, fill, linetype, size, weight |
| hline | hline | colour, linetype, size | |
| jitter | identity | x, y | colour, fill, shape, size |
| line | identity | x, y | colour, linetype, size |
| linerange | identity | x, ymax, ymin | colour, linetype, size |
| path | identity | x, y | colour, linetype, size |
| point | identity | x, y | colour, fill, shape, size |
| pointrange | identity | x, y, ymax, ymin | colour, fill, linetype, shape, size |
| polygon | identity | x, y | colour, fill, linetype, size |
| quantile | quantile | x, y | colour, linetype, size, weight |
| rect | identity | xmax, xmin, ymax, ymin | colour, fill, linetype, size |
| ribbon | identity | x, ymax, ymin | colour, fill, linetype, size |
| rug | identity | colour, linetype, size | |
| segment | identity | x, xend, y, yend | colour, linetype, size, |
| smooth | smooth | x, y | alpha, colour, fill, linetype, size, weight |
| step | identity | x, y | colour, linetype, size |
| text | identity | label, x, y | angle, colour, hjust, size, vjust |
| tile | identity | x, y | colour, fill, linetype, size |
| vline | vline | colour, linetype, size |
4.7 统计变换 (stat)
Every geom has a default stat, and every stat a default geom.
| stat_* | Description | 描述 |
|---|---|---|
| bin | Bin data | 分 bin |
| boxplot | Calculate components of box-and-whisker plot | |
| contour | Contours of 3d data | |
| density | Density estimation, 1d | |
| density2d | Density estimation, 2d | |
| function | Superimpose a function | 自定义 stat 变换 |
| identity | No transformation | |
| Calculation for quantile-quantile plot | ||
| quantile | Continuous quantiles | 计算连续的分位数 |
| smooth | Add a smoother | |
| spoke | Convert angle and radius to xend and yend |
|
| step | Create stair steps | |
| sum | Sum unique values. Useful for overplotting on scatterplots | |
| summary | Summarise y values at every unique x |
|
| unique | Remove duplicates |
A stat takes a dataset as input and returns a dataset as output, and so a stat can add new variables to the original dataset. It is possible to map aesthetics to these new variables. For example, stat_bin produces the following variables:
count, the number of observations in each bindensity, the density of observations in each bin (percentage of total / bar width)x, the centre of the bin
These generated variables can be used instead of the variables present in the original dataset. E.g.
ggplot(diamonds, aes(carat)) +
+ geom_histogram(aes(y = ..density..), binwidth = 0.1)
The names of generated variables must be surrounded with .. when used.
4.8 geom_xxx(position=?) 或 stat_xxx(position=?) 参数设置
| Position | Description | 描述 |
|---|---|---|
| dodge | Dodging overlaps to the side | 避免重叠,并排放置 |
| fill | Stack overlapping objects and standardise them to have equal height | 堆叠元素并将高度标准化为 1 |
| identity | No position adjustment | |
| jitter | Jitter points to avoid overplotting | 给 dots 添加扰动避免重合 |
| stack | Stack overlapping objects on top of one another | 堆叠元素 |
4.9 整合
4.9.1 灵活使用 geom 与 stat
A number of the geoms available in ggplot2 were derived from other geoms.
| Alias | Equivalence |
|---|---|
geom_area |
geom_ribbon(aes(min = 0, max = y), position = "stack") |
geom_density |
geom_area(stat = "density") |
geom_freqpoly |
geom_line(stat = "bin") |
geom_histogram |
geom_bar(stat = "bin") |
geom_jitter |
geom_point(position = "jitter") |
geom_quantile |
geom_line(stat = "quantile") |
geom_smooth |
geom_ribbon(stat = "smooth") |
4.9.2 统计量复用: stat_identity()
如果你已经有变换过的数据,并且想再次使用,可以用 stat_identity(geom=?) 将原有的变化过的数据画到新的图层里。
4.9.3 不同图层可以使用不同的 data=?和 mapping=aes(...) 设置
略
第五章 - ggplot2 工具箱
5.2 图层的分类
略
5.3 基本的 geom
略
5.4 展示数据分布的 geom
略
5.5 处理遮盖 (overplotting)
略
5.6 如何绘制曲面图
略
5.7 如何绘制地图
略
5.8 如何展示 uncertainty
| 变量 $X$ 类型 | 仅展示区间 | 同时展现区间和中间值 |
|---|---|---|
| 连续型 | geom_ribbon |
geom_smooth(stat = "identity") |
| 离散型 | geom_errorbar |
geom_crossbar |
geom_linerange |
geom_pointrange |
5.9 统计摘要: stat_summary()
参考:
Summary functions from the Hmisc package that have special wrappers to make them easy to use with stat_summary():
| Function | Hmisc original |
Middle | Range |
|---|---|---|---|
mean_cl_normal() |
smean.cl.boot() |
Mean | Standard error from normal approximation |
mean_cl_boot() |
smean.cl.boot() |
Mean | Standard error from bootstrap |
mean_sdl() |
smean.sdl() |
Mean | Multiple of standard deviation |
median_hilow() |
smedian.hilow() |
Median | Outer quantiles with equal tail areas |
5.10 如何添加图形注解 (label, text, etc.)
略。图例精彩,可参考。
5.11 如何体现数据的 weight
略
第六章 - Scale, axis and legend
6.2 scale 的工作原理
略
6.3 scale 的用法
See Reference - Scales.
All scale constructors have a common naming scheme. They start with scale_, followed by the name of the aesthetic (e.g., colour_, shape_ or x_), and finally by the name of the scale (e.g., gradient, hue or manual)
To change the default scales, use set_default_scale().
6.4 scale 详解
6.4.1 scale_*_*(name=?) 与 labs()
设置 axis (比如 scale_x_*) 或者 legend (比如 scale_color_*) 上出现的标签。
注意标签可以使用 latex,具体参考 ?plotmath。
因为修改 labels 这个操作经常用到,所以设计了 labs() 以及衍生的一些函数来简化操作:
xlab("Foo") == labs(x = "Foo")ylab("Bar") == labs(y = "Bar")ggtitle(label = "Foo", subtitle = "bar") == labs(title = "Foo", subtitle = "bar")
而且,比如说你用了 colour 的 scale,就可以用 labs(colour = "Foo") 来设置 legend 上方的 label:
p <- ggplot(mtcars, aes(mpg, wt, colour = cyl)) + geom_point()
p + labs(colour = "Cylinders")
p + labs(x = "New x label")
p + labs(title = "New plot title")
p + labs(caption = "(based on data from ...)") # 加在 plot 的右下方
6.4.2 scale_x_*(limits=?, breaks=?, labels=?) 与 formatter
以 $x$-axis 为例:
limits指 $x$-axis 的范围- 对 continuous 的 $X$ 而言,
limits = c(a, b)就设置了 $x$-axis 在[a, b]区间上 - 对 discrete 的 $X$ 而言,
limits实际的作用相当于breaks,而且 $x$-axis 上 breaks 的顺序和limits的一致。- 比如说
limits = c("#3", "#2", "#1"),你 $x$-axis 上就是#3、#2、#1的顺序
- 比如说
- 类似
xlab与ylab,有xlim与ylim来简化操作
- 对 continuous 的 $X$ 而言,
breaks指刻度线- 比如
limits = c(0, 1), breaks = c(0, 0.5, 1)就是 3 个刻度0、0.5、1
- 比如
labels指自定义的刻度显示- 比如
breaks = c(0, 0.5, 1), labels = c("zero", "half", "whole")就是在0刻度显示zero、在0.5刻度显示half、在1刻度显示whole
- 比如
此外,还可以指定 labels = formatter 而不是具体的值:
library(scales)
# Format labels as percents
p + scale_x_continuous(labels = percent)
# Format labels as scientific
p + scale_x_continuous(labels = scientific)
- 对 continuous 的 $X$ 而言,可用的 formatter 有:
commapercentdollarscientific
- 对 discrete 的 $X$ 而言,可用的 formatter 有:
abbreviate
另外对 continuous 的 $X$ 而言,scale_x_log10() == scale_x_continuous(trans = "log10")。类似的 trans 还可以设置为:
| Name | Function $\operatorname f(x)$ |
|---|---|
| asn | $\operatorname{tanh}^{−1}(x)$ |
| exp | $e^x$ |
| identity | $x$ |
| log | $\log(x)$ |
| log10 | $\log_{10}(x)$ |
| log2 | $\log_{2}(x)$ |
| logit | $\log(\frac{1−x}{x})$ |
| pow10 | $10^x$ |
| probit | $\phi(x)$ |
| recip | $x^{−1}$ |
| reverse | $−x$ |
| sqrt | $\sqrt{x}$ |
注意 trans = "log10" 只会 plot log10(y) ~ log10(x),并不会修改 limits、breaks 和 labels;如果你是直接 ggplot(log10(x), log10(y), data),图形和 trans = "log10" 是一样的,但是 limits、breaks 和 labels 都会变成 log10。具体可以试验:
qplot(carat, price, data = diamonds) + scale_x_log10() + scale_y_log10()
qplot(log10(carat), log10(price), data = diamonds)
6.4.3 scale_colour_* 与 scale_fill_*
连续型:颜色梯度,即渐变色
scale_*_gradient(low, high):双色梯度scale_*_gradient2(low, mid, high):三色梯度scale_*_gradientn():自定义 $n$ 色梯度
离散型:
scale_*_hue:延着 hcl (hue 色相 / chroma 彩度 / luminance 明度) 色轮选取均匀分布的色相来生成颜色- 生成 $\leq 8$ 种颜色时,区分度较高
scale_*_brewer():使用 ColorBrewer 配色方案:- 比如
scale_colour_brewer(pal = "Set1")palfor “palette”
- 使用
RColorBrewer::display.brewer.all()查看所有配色方案
- 比如
scale_*_manual(values = ?):手动设置颜色- 比如
unique(mpg$drv) == c("f", "4", "r"),如果是aes(x = drv, data = mpg),那么可以设置:scale_fill_manual(values = c("red", "yellow", "green"))或者scale_fill_manual(values = c(f = "red", "1" = "yellow", r = "green"))
- 比如
6.4.4 scale_*_manual
注意书上这个例子不错:
huron <- data.frame(year = 1875:1972, level = LakeHuron)
# 没有 legend
ggplot(huron, aes(year))
+ geom_line(aes(y = level - 5), colour = "blue")
+ geom_line(aes(y = level + 5), colour = "red")
# 有 legend 但是 label 和颜色都不对
ggplot(huron, aes(year))
+ geom_line(aes(y = level - 5, colour = "below"))
+ geom_line(aes(y = level + 5, colour = "above"))
# 有正确的 legend 和颜色
ggplot(huron, aes(year))
+ geom_line(aes(y = level - 5, colour = "below")) +
+ geom_line(aes(y = level + 5, colour = "above")) +
+ scale_colour_manual("Direction", c("below" = "blue", "above" = "red"))
注意最后这个例子里,color 是在 aes 里面的,所以第一条 line 的颜色是映射到常量 "below" 的,然后 "below" 在 scale 中映射到颜色 "blue"。这里明显不能用 I("below")。
6.4.5 scale_*_identity
略
6.5 legend and axis
The theme settings axis.* and legend.* control the visual appearance of axes and legends. See Section 8.1.
调整 legend 的位置:
# get rid of the legend
p + theme(legend.position = 'none')
# Put legend outside the plotting area
# On left, right, top or bottom margin
p + theme(legend.position = 'left')
# Put legend inside the plotting area
# 放到左下角
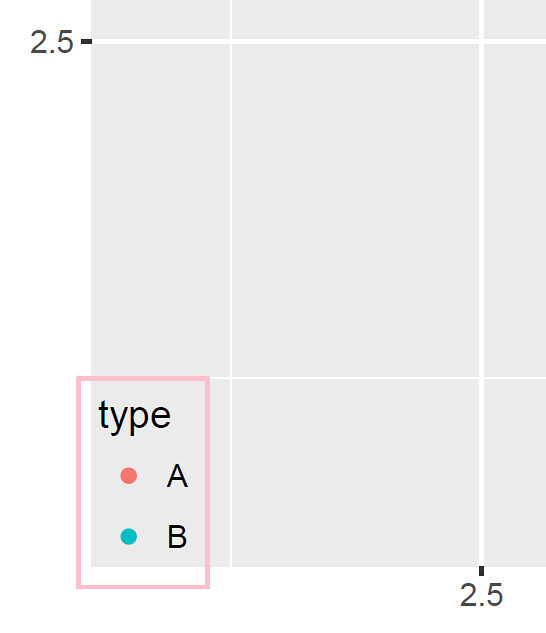
p + theme(legend.justification = c(0, 0), legend.position = c(0, 0))
- 注意在
legend.justification和legend.position中:c(0, 0)指左下角c(0, 1)指左上角c(1, 1)指右上角c(1, 0)指右下角
legend.justification指 legend 本身这个 rectangle 中的一个锚点,这个锚点会与legend.position指定的点重合,这就形成了 legend 在图中的位置legend.position是 legend 锚点要对齐的点。注意legend.position = c(0, 0)并不是指坐标轴 $(0, 0)$ 这个点,而是整个画图区域(默认灰色背景方格区域)的左下角- 同时指定
legend.justification = c(0, 0)和legend.position = c(0, 0)的意思就是:“把 legend rectangle 的左下角与画图区域的左下角重合” - 默认情况下,
legend.justification == "center" == c(0.5, 0.5),此外还可以指定:legend.justification = "left" = c(0, 0.5)legend.justification = "right" = c(1, 0.5)
举例:
library(ggplot2)
xy <- data.frame(x=1:10, y=10:1, type = rep(LETTERS[1:2], each=5))
plot <- ggplot(data = xy) + geom_point(aes(x = x, y = y, color=type))
plot + theme(legend.justification = c(.1, .1), legend.position = c(0, 0),
legend.background= element_rect(colour = "pink", fill = "transparent"),
legend.key = element_rect(colour = "transparent", fill = "transparent"))
第七章 - Facet and coord system
7.2 分面 (facet)
两种分面方式:
facet_grid:如果 formula 是x ~ y且 $\vert X \vert = m, \vert Y \vert = n$,则最终结果是 $m \times n$ 的 grid- 这个 grid 中的一个子图,或者说一个 cell,我们称为一个 “panel”
facet_wrap:不管你有多少个 panel,统一按参数nrow = m或者ncol = n排成 $m$ 行或者 $n$ 列
默认不使用分面的效果是 facet_null()。
7.2.1 facet_grid
formula 参 2.6
另外可以使用 facet_grid(margins=TRUE) 来添加 marginal 统计列和统计行
7.2.2 facet_wrap
formula 是 ~ x (没有 . placeholder) 或者 ~ x + y + ...。
比如 ~ x + y 且 $\vert X \vert = m, \vert Y \vert = n$,则一共有 $m \times n$ 个 panel,然后按 nrow 或者 ncol 排列
7.2.3 facet_*(scales=?, space=?) 参数设置
对于 facet_wrap:
- 每个 panel 都可以拥有单独的 scale
对于 facet_grid:
- All panels in a column must share the same
xscale - All panels in a row must share the same
yscale
scales 参数:
scales = "fixed":xandyscales are fixed across all panels.scales = "free":xandyscales vary across panels.scales = "free_x": thexscale can vary, and theyscale is fixed.scales = "free_y": theyscale can vary, and thexscale is fixed.
space 参数的设置同上。
When the space can vary freely, each column (or row) will have width (or height) proportional to the range of the scale for that column (or row)
这俩参数的效果非常微妙,实践中自己尝试即可。一个例子:
mpg2 <- subset(mpg, cyl != 5 & drv %in% c("4", "f"))
mpg3 <- within(mpg2, {
model <- reorder(model, cty)
manufacturer <- reorder(manufacturer, -cty)
})
models <- qplot(cty, model, data = mpg3)
models
models + facet_grid(manufacturer ~ ., scales = "free", space = "free")
models + facet_grid(manufacturer ~ ., scales = "free", space = "free")
+ theme(strip.text.y = element_text(angle=0)) # 右侧的 facet label (mpg3$manufacturer),默认是竖排的,改成横排
7.2.4 如果某个图层的 data 没有 formula 指定的变量
略
7.2.5 aes(group=?) vs faceting
When using aes(group=?), the groups are close together and may overlap, but small differences are easier to see.
略
7.2.6 geom_*(position="dodge") vs faceting
Faceting is more useful as we can control whether the splitting is local (scales = "free_x", space = "free") or global (scales = "fixed").
略
7.2.7 如何处理连续型的 facet variable
cut_interval(x, n = 10): 将 $x$ 分入 $n$ 个 bin,每个 bin 的长度都是 $\frac{\operatorname{max}(x) - \operatorname{min}(x)}{n}$cut_interval(x, length = 1): 将 $x$ 分入若干个 bin,每个 bin 的长度都是 1cut_number(x, n = 10): 将 $x$ 分入若干个 bin,每个 bin 内都有 10 个元素
> mpg2 <- subset(mpg, cyl != 5 & drv %in% c("4", "f"))
> cut_interval(mpg2$displ, n = 6)
[1] [1.6,2.42] [1.6,2.42] [1.6,2.42]
[4] [1.6,2.42] (2.42,3.23] (2.42,3.23]
......
[205] (3.23,4.05]
> cut_interval(mpg2$displ, length = 1)
[1] [1,2] [1,2] [1,2] [1,2] (2,3] (2,3] (3,4]
[8] [1,2] [1,2] [1,2] [1,2] (2,3] (2,3] (3,4]
......
[204] (2,3] (3,4]
> cut_number(mpg2$displ, n = 6)
[1] [1.6,2] [1.6,2] [1.6,2] [1.6,2]
[5] (2.5,3] (2.5,3] (3,3.8] [1.6,2]
......
[205] (3,3.8]
mpg2$disp_ww <- cut_interval(mpg2$displ, length = 1)
mpg2$disp_wn <- cut_interval(mpg2$displ, n = 6)
mpg2$disp_nn <- cut_number(mpg2$displ, n = 6)
plot <- qplot(cty, hwy, data = mpg2) + labs(x = NULL, y = NULL)
plot + facet_wrap(~ disp_ww, nrow = 1)
plot + facet_wrap(~ disp_wn, nrow = 1)
plot + facet_wrap(~ disp_nn, nrow = 1)
7.3 Coord system
7.3.1 坐标系变换
略
7.3.2 stat 依赖于坐标系
略
7.3.3 Cartesian 坐标系
There are 4 Cartesian-based coordinate systems:
coord_cartesiancoord_fixedcoord_flipcoord_trans
coord_cartesian 也有 xlim 和 ylim 参数。
coord_cartesian(xlim = ?, ylim = ?) 与 lims(x = ?, y = ?) 的区别:
- 首先
xlim(...) == lims(x = ...);ylim同理 lims可以设置所有 scale 的 limits。比如你有aes(colour = df$x),然后df$x取值是 2、4、6、8,我可以p + lims(colour = c(2, 4))只显示其中两种颜色,另外两种颜色的 point 根本就不会出现在图上- 同理,如果设置了
lims(x = ?, y = ?),范围之外的 point 也不会出现在图上 (相当于找不到映射关系,数据无法映射到一个点上)- 如果此时你画 smooth,和整体数据的 smooth 曲线是不一样的
coord_cartesian(xlim = ?, ylim = ?)不会排除任何一个 point,永远是使用全部的数据。它的作用相当于是 zoom-in (设置为小范围) 或是 zoom-out (设置为大范围)- smooth 永远是整体数据的 smooth,只是不同的范围你会看到 smooth 曲线不同的段
更多内容参考书上。
7.3.4 Non-Cartesian 坐标系
略
第八章 - Polishing your plots for publication
8.1 主题 (theme)
8.1.1 内置主题
theme_gray():默认主题。淡灰色背景 + 白色网格线theme_bw():白色背景 + 深灰色网格线
更多内置主题参考 Complete themes。
修改全局主题:
previous_theme <- theme_set(theme_bw()) # 以后所有的 plotting 都使用 theme_bw()
......
theme_set(previous_theme) # 恢复原有主题
另外使用 theme_get() 可以获取当前主题
修改单次作图主题:
p + theme_bw()
注:第三方的主题可以用 ggthemr package;参考 The ggthemr package – Theme and colour your ggplot figures
8.1.2 主题元素的设置
参 Modify components of a theme。
另外 theme_update() 可以修改当前主题的单个元素。
注意主题是样式的修改,不涉及内容的修改。比如 element_text 就只能修改 label 的样式 (比如 font、size 之类),而无法设置 label 的内容 (你必须用 labs())。
8.2 自定义 scale 和 geom
略
8.3 保存作图到文件
往大了说,图片有两种存储类型:
- raster: 光栅图
- Raster graphics are stored as an array of pixels and have a fixed optimal viewing size.
- vector: 矢量图
- Vector graphics are essentially “infinitely” zoomable; there is no loss of detail.
保存图像有两种方式:
ggsave(),参考 ggsave: Save a ggplot (or other grid object) with sensible defaultsscale参数指的是一个 ratio。比如scale = 2意味着实际打印出来的 size 是屏幕显示的 size 的 2 倍dpi即分辨率,针对 raster 而言
- 打开磁盘的图形设备 (比如
png()或者pdf()),然后打印图形 (print(p)),最后关闭图形设备 (dev.off())
qplot(mpg, wt, data = mtcars)
ggsave(file = "output.pdf") # 默认参数:plot = last_plot()
pdf(file = "output2.pdf", width = 6, height = 6)
print(qplot(mpg, wt, data = mtcars))
print(qplot(wt, mpg, data = mtcars))
dev.off()
Recommended graphics device:
- latex: ps
- pdflatex: pdf, png (600 dpi)
- web: png (72 dpi)
8.4 多图排列
略。需要的时候再查。
另外可以参考:
第九章 - Data Manipulation
略
第十章 - 减少重复性的工作
只说一点:如果是设计一个函数去包括一系列的绘图操作,且允许用户输入变量名时,可以用 aes_string 代替 aes,他们本质是一样,只是 aes_string 接收的是字符串:
aes_string("cty", colour = "hwy")
# is equivalent to
aes(cty, colour = hwy)
其余略。
留下评论