LL/SC, LA/SR, Memory Consistency, and Cache Coherence
前言 1:Memory Models 让人头秃
我真的只是想了解下 LL/SC 和 LA/SR,但没想到它们背后的知识是茫茫多。
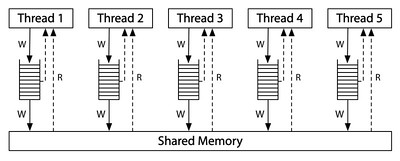
一般会提到 memory models. 它 truely 说的是 physical 的 CPU 的 memory architecture,不是纯研究用的理论模型。比如 x86-TSO (Total Store Order) 的 store buffer 结构:
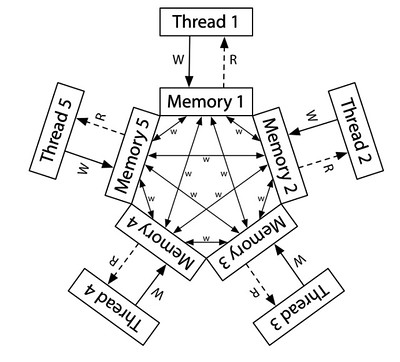
比如 ARM/POWER 的 Relaxed Memory Model:
1.1 要区分 hardware 的物理特性 🆚 guarantee
比如 TSO 中,你 thread_1 write 的内容会先到 store buffer 中,在被 flush 到 shared memory 之前,其他的 thread 看不到这个 write,但 thread_1 自己能看到 (因为它 read 时会先 read store buffer)。这就属于 hardware 的物理特性。
又比如 DRF-SC,它是某些 CPU 提供的 guarantee,它就很难从物理上看出来,但是某些 CPU 就是有这个性质。
1.2 不要用 memory ordering 去总结所有的特性 / 使用 Litmus Test 更准确
比如有人讲:
- SC = enforces all orderings
#LoadLoad✅#LoadStore✅#StoreLoad✅#StoreStore✅
- TSO = enforces 3 orderings but allows
#StoreLoadreordering#LoadLoad✅#LoadStore✅#StoreLoad❌#StoreStore✅
我觉得某种程度上这么说 ok,但我顺着这个思路想:会不会 weak memory models 就是 allows all reorderings? 答案是 nope!比如 ARM/POWER 其实有 coherence 特性:
Litmus Test: Coherence
Can this program see r1 = 1, r2 = 2, r3 = 2, r4 = 1?
(Can Thread 3 see x = 1 before x = 2 while Thread 4 sees the reverse?)
// Thread 1 // Thread 2 // Thread 3 // Thread 4
x = 1 x = 2 r1 = x r3 = x
r2 = x r4 = x
On sequentially consistent hardware: no.
On x86 (or other TSO): no.
On ARM/POWER: no.
如果 allowing all reorderings,我们完全可以排出这么一个 execution:
// Thread 1 // Thread 2 // Thread 3 // Thread 4
x = 1
r1 = x
r4 = x
x = 2
r2 = x
r3 = x
但 coherence 不允许这样的 execution,因为:
… even on ARM/POWER: threads in the system must agree about a total order for the writes to a single memory location. That is, threads must agree which writes overwrite other writes. This property is called called coherence.
所以 Litmus Test 更能反映出 CPU/Memory Model 的特性。你可以把它理解成是一种 CPU/Memory Model 的 Unit Test; 缺点是没法形成大一统的理解,但同时我们也要理解大一统的难度。
1.3 暂时还不能信 AI
我发现 AI 有时候会胡扯:比如我的 ChatGPT 会把 DRF0 和 DRF-SC 都认为是 memory models 并做横向比较,但前者是 (theoretical) synchronization model,后者是 CPU/memory model 的 guarantee。
1.4 要会动态调整抽象的粒度
以下我们用 HW (hardware) 指 CPU/Core/Multi-process,用 SW (software) 指 Language/Compiler/Multi-thread.
HW 是真的有 memory architecture,所以有 memory consistency 特性的研究。SW 没有 physical 的 memory model,但如果你抽象出 load、write、location、variable、const 这些概念,SW 一样也有 memory consistency 的问题。
HW 有 caches,所以有 cache coherence 特性的研究。但后面我们能看到用 memory consistency 类似的方式来定义 cache coherence,理论上可以不依赖于 cache 结构。
鉴于 memory consistency 和 cache coherence 逐渐成为了通用的研究课题,A Primer on Memory Consistency and Cache Coherence 大胆开麦:
- Consistency == Memory Consistency == Memory Consistency Model == Memory Model
- Coherence == Cache Coherence
如果你选择一个高度抽象的角度,特别是有了 DRF-SC (as a contract between HW and SW) 之后,HW 和 SW 的 memory models 似乎可以统一:
- 如果你是个 C++/Java programmer,你这么理解 ok
- 但如果你是个 assembly programmer、或者 compiler engineer,这么理解给你的收益并不大
1.5 读新不读旧
让我很意外的是:consistency 和 coherence 的研究从 90 年代开始,formalization 到最近才有点眉目。以前的某些 CPU 可能会有一些很 frustrating 的 non-consistent/non-coherent 的行为,甚至都没有 documentation,它就可以上市了。我都有点同情之前搞 concurrent computing 的研究者。
鉴于这是个还在进化中的课题,我们明显要读新不读旧,因为旧的理解很有可能已经被取代,新的概念可能更全面、更好懂。
我这里推荐:
- Russ Cox 的 Memory Models 系列 (great introduction)
- A Primer on Memory Consistency and Cache Coherence (for precise definition)
- DRFx: A Simple and Efficient Memory Model for Concurrent Programming Languages (for precise definition, and if you want to create a memory model you own)
我不推荐:
- Herb Sutter 的
atomic<>Weapons (explorative, but has errors, may be confusing)
前言 2:怎么会有这么多 DRF?
2.1 首先要区分 Data Race 和 Race Condition
Herb Sutter 的 atomic<> Weapons 有:
Race condition: A memory location (variable) can be simultaneously accessed by two threads, and at least one thread is a writer.
- Memory location == non-bitfield variable, or sequence of non-zero-length bitfield variables.
- Simultaneously == without happens-before ordering.
但他这个其实是 Data Race 的定义。我更倾向于 HolyBlackCat 的观点:
Race condition is not a synonym (to data race), it’s just a loose word for an intermittent bug that depends on how fast the threads happen to execute. (The buggy program may or may not also have a data race.)
他引用的是 Baris Kasikci & legends2k:
A data race occurs when 2 instructions from different threads access the same memory location, at least one of these accesses is a write and there is no synchronization that is mandating any particular order among these accesses.
A race condition is a semantic error. It is a flaw that occurs in the timing or the ordering of events that leads to erroneous program behavior. Many race conditions can be caused by data races, but this is not necessary.
Baris Kasikci & legends2k 还有一个例子:
Thread 1 Thread 2 lock(l) lock(l) x=1 x=2 unlock(l) unlock(l)
- 这构成一个 Race Condition,因为 program 的结果完全依赖于 “how fast the threads happen to execute”
- 这不构成一个 Data Race,因为
lock(l)保证了不会有 simultaneously access
2.2 DRF 是 program (& execution) 的 property
我个人比较喜欢 DRFx: A Simple and Efficient Memory Model for Concurrent Programming Languages 中的定义:
Definition 1: Two memory accesses conflict if they access the same location and at least one of them is a write.
Definition 2: A program state is racy if two different threads are about to execute conflicting memory accesses from that state.
Definition 3: A program contains a data race (or simply a race) if it has a sequentially consistent execution that reaches a racy state.
把 program state 换成 execution,我们可以重写一下 Definition 3: Given a program $P$, if $\exists$ an SC execution $E$ of $P$ that is racy $\implies$ $P$ has a data race
考虑逆否命题:Program $P$ is DRF (data-race-free) $\implies$ all its SC executions are DRF
考虑到我们这里是 definition,所以上面的 $\implies$ 应该可以换成 $\iff$
DRFx: A Simple and Efficient Memory Model for Concurrent Programming Languages 的这个 venn diagram 很说明问题:
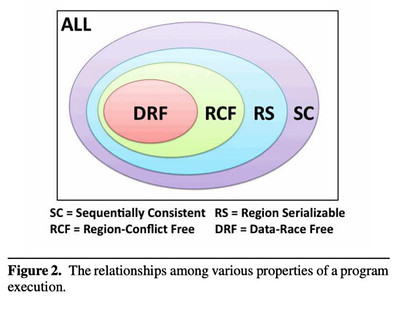
- $\text{SC}$ represents the set of all executions that are sequentially consistent w.r.t. a program $P$.
- $\text{DRF}$ is the set of executions that are data-race free
- If program $P$ is DRF, then $\text{SC} = \text{DRF}$
- but $P$ could have non-SC executions even so
2.3 SC 是 execution 的 pattern / 同时 SC 也是一种 (strong 的) consistency model
可以这样理解:
- (less formally) “sequentially consistent execution” 是一种 multi-core 或者 multi-thread 的 execution pattern
- Sequential Consistency 是一个很 strong 的 memory (consistency) model
- 使用 SC model 的 HW 或者 SW 会 SC-ly 地去 execute program
2.3.1 SC Execution
SC execution 是这样一种 multi-core 的 execution (by Leslie Lamport):
… the result of any execution is the same as if the operations of all processors (cores) were executed in some sequential order, and the operations of each individual processor (core) appear in this sequence in the order specified by its program.
这句话其实非常不好理解。我们假设 program $P$ 可能有多种 execution $E_1, E_2, \dots, E_n$,单个 execution $E_i$ 能看成一个 instruction sequence $\overline{s_1^{(i)}, s_2^{(i)}, \dots, s_k^{(i)}}$:
- 首先它说 “any execution is the same as if …. in some sequential order”,这里是 “some” 不是说所有的 execution 都要 as if 同一个 sequential order,而是 $\exists$ 一个 sequential order 就行
- 比如说 $E_1$ as if $\overline{s_1^{(1)}, s_2^{(1)}, \dots, s_k^{(1)}}$
- $E_2$ as if $\overline{s_1^{(2)}, s_2^{(2)}, \dots, s_k^{(2)}}$
- 但没有要求说 $\overline{s_1^{(1)}, s_2^{(1)}, \dots, s_k^{(1)}}$ 和 $\overline{s_1^{(2)}, s_2^{(2)}, \dots, s_k^{(2)}}$ 是同一个 sequence
- 也就是说 $E_1$ 和 $E_2$ 是可以有不同的结果的 (不管是 side effects 层面还是 program states 层面)
- 然后这句 “and the operations … appear in this sequence in the order …. “ 纯粹是语法问题:
- “in the order specified by its program” 修饰的既不是 “operations” 也不是 “sequence”
- 它修饰的是 “appear in” 这个动作
- 即 “operations” 按照这个 order 去 appear in the sequence
- 那这句具体啥意思?其实蛮简单,就是你任意一个 thread 都只能按照 program order 去执行;你多个 threads (的 instructions) 在 sequence $\overline{s_1^{(i)}, s_2^{(i)}, \dots, s_k^{(i)}}$ 中如何穿插,我不管
- 假设
thread_1的 instruction (按 program order) 是 $\overline{\pi_1, \pi_2}$ - 假设
thread_2的 instruction (按 program order) 是 $\overline{\rho_1, \rho_2}$ - 我不管你的 execution 是 $\overline{\pi_1, \rho_1, \pi_2, \rho_2}$ 还是 $\overline{\rho_1, \pi_1, \pi_2, \rho_2}$ 还是什么其他的 sequence,你必须给我保证 $\pi_1 < \pi_2$ (i.e. $\pi_1$ 在 $\pi_2$ 前面) 且 $\rho_1 < \rho_2$
- 一个具体的例子可以参考 Malloc
- 这里还有一个细节问题:
thread_1.start(); thread_2.start();这样的代码算不算 program order? 我个人觉得这应该算是一个特殊情况,因为实际应用中thread_2是有可能先于thread_1执行,所以这个 program order 你不应该去考虑。- 我们要考虑应该只是
thread_1和thread_2的 worker function 的 program order
- 我们要考虑应该只是
- 假设
- 最后我们来看下 “is the same as if” 的这个 “as if” 是啥意思。amon 有一个很妙的解读:
The behaviour of all processes was as if they had been executed in a particular order, although this agreed-upon order was different from the actual temporal order. We don’t care about when a write is observed, only about the order between writes.
- 这里涉及了 strict consistency 和 atomicity,我们后面会详述
2.3.2 SC Consistency Model
按 A Primer on Memory Consistency and Cache Coherence 的定义,假设:
- $L(a)$ is a
loadto address $a$ - $S(a)$ is a
storeto address $a$ - $<^{p}$ is the program memory order, more precisely, a per-core order in which each core logically (sequentially) executes memory operations
- $<^{m}$ is the global memory order, more precisely, a total order on the memory operations of all cores
An SC Execution requires:
- All cores insert their
loads andstores into the order $<^{m}$ respecting their $<^{p}$, regardless of whether they are to the same or different addresses (i.e., $a=b$ or $a \neq b$). There are 4 cases:- If $L(a) <^{p} L(b) \Rightarrow L(a) <^{m} L(b)$ (
#LoadLoad) - If $L(a) <^{p} S(b) \Rightarrow L(a) <^{m} S(b)$ (
#LoadStore) - If $S(a) <^{p} S(b) \Rightarrow S(a) <^{m} S(b)$ (
#StoreStore) - If $S(a) <^{p} L(b) \Rightarrow S(a) <^{m} L(b)$ (
#StoreLoad)
- If $L(a) <^{p} L(b) \Rightarrow L(a) <^{m} L(b)$ (
- Every
loadgets its value from the laststorebefore it (in $<^{m}$ order) to the same address, i.e. $\vert L(a) \vert = \vert \max_{<^{m}} \lbrace S(a) \mid S(a) <^{m} L(a) \rbrace \vert$ where $\max_{<^{m}}$ denotes “latest in memory order”
An SC implementation permits only SC executions.
2.4 DRF-SC (or SC-for-DRF) 是使用 weaker-than-SC model 的 HW 提供的一个 guarantee
Jeff Preshing 给 memory models 分了 4 大类:
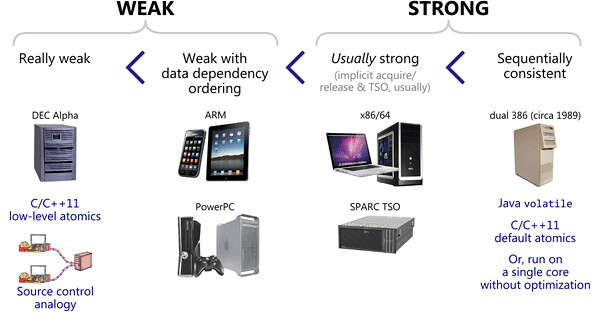
当然 consistency model 有比 SC 更 stong 的,只是实际应用中 HW 和 SW 都用不上。实际应用中,HW 用 SC 的都很少,主要是因为 SC 的约束太强,weaker consistency model 允许的 CPU 优化的空间更大。
按 A Primer on Memory Consistency and Cache Coherence 的定义:
Definition: A memory consistency model supports “SC for DRF programs” if all executions of all DRF programs are SC executions. (This support usually requires some special actions for synchronization operations.) $\blacksquare$
可以这样理解:
- DRF program 需要 SC execution,否则 DRF 没有意义
- 如果 HW 是 SC model,那么大家相安无事,DRF program 在这样的 HW 上一定是只有 SC execution,所以它一定 DRF
- 此时 HW 不需要额外的 DRF-SC
- 如果 HW 是 weaker-than-SC model,那么 DRF program 仍然可能有 non-SC execution
- 如果我给使用 weaker-than-SC model 的 HW 加上 DRF-SC 这个 buff,那么 HW 可以保证对 DRF program 只有 SC execution
- 简单说就是:
- DRF-SC 是使用 weaker-than-SC model 的 HW 对 DRF program guarantee 的一个 100% SC 的 execution 模式
- DRF-SC 使得 DRF program 在 weaker-than-SC 的 HW 上只能 SC execution
你可能要问:”DRF program 仍然可能有 non-SC execution” 有什么问题么?它又不影响 program 的性质?
的确是这样,按照 DRF 的定义,DRF program 是可以有 non-SC execution 的。但我们提出 DRF 是为了 reasoning:
- 想象你在 debugging,你已经判断出 program 是 DRF 的,但 HW 却仍然允许 program 出现 data race,那我这个程序就没法写了
- 从另一个角度来说,你要 non-SC 的 execution 也做到 data race free 似乎也太难了一点,我都想象不出要怎么弄
2.5 Question: 使用 Weaker Model + DRF-SC 的 HW,与使用 SC 的 HW 相比,在 performance 上有什么优势?
尤其考虑到一个 DRF 的 program:它在 weaker-than-SC 但是 DRF-SC 的 HW 上也是 SC 执行的,那么这样和 SC model 的 HW 有什么分别?
这属于 optimization 的问题,最浅显的一个例子:TSO 的 store buffer 就是一种 optimization. 再进一步减弱到 Relaxed Model,optimization 的方便程度会更大 (因为 SC 太严格)。
而且实际应用中,某些 optimization 是可以违反我们这里谈到的 definition/principle 的,比如 A Primer on Memory Consistency and Cache Coherence 的 5.1.2 OPPORTUNITIES TO EXPLOIT REORDERING 介绍的 “opening the coherence box”:
We previously advocated decoupling consistency and coherence to manage intellectual complexity. Alternatively, relaxed models can provide better performance than strong models by “opening the coherence box.” For example, an implementation might allow a subset of cores to load the new value from a store even as the rest of the cores can still load the old value, temporarily breaking coherence’s single-writer–multiple-reader invariant. This situation can occur, for example, when two thread contexts logically share a per-core write buffer or when two cores share an L1 data cache. However, “opening the coherence box” incurs considerable intellectual and verification complexity, bringing to mind the Greek myth about Pandora’s box. As we will discuss in Section 5.6.2, IBM Power permits the above optimizations.
这个 optimization 的手段都可以打破 coherence 的约束 (当然是在某些特定的情况下),所以 optimization 的方法论你可以认为是非常 wild 的。
综上,这个问题你可以这样泛泛地理解:
- 理论模型永远是理论模型,现实总会有点出入
- optimization 属于 “现实” 那一 part,且手段可能很 wild
- 所以一个 relaxed model + DRF-SC 能允许的 optimization 应该要比 SC model 能允许的更强力,所以 performance 上会更好
2.6 DRF0 是一个 sychronization model (and you probably don’t have to study it too much)
很多论文会追溯到 Weak ordering - a new definition 这篇 1990 年的论文。它提出了 DRF0 as a sychronization model:
Definition: A program obeys the synchronization model Data-Race-Free-0 (DRF0), if and only if
- all synchronization operations are recognizable by the hardware and each accesses exactly one memory location, and
- for any execution on the idealized system (where all memory accesses are executed atomically and in program order), all conflicting accesses are ordered by the happens-before relation correspouding to the execution.
我的观点还是 “读新不读旧”。
前言 3:Coherence 与 Consistency 的区别与联系
不怎么严谨地说:
- consistency 关注的是 multi-thread/core 在 shared memory 上的 operation ordering
- coherence 关注的是 “如果
core_1有一个 write,我怎么 make this write visible tocore_2?”- 它 (从 HW 结构上来讲) 不涉及 shared memory
- 你可以简单理解成 “CPU 要如何实现一个
store?”,细节问题包括:- 我要如何刷新所有 core 的 cache?
- 我是等刷新结束后才允许
storereturn,还是先让storereturn 再刷新? - etc.
按 A Primer on Memory Consistency and Cache Coherence 的图示:
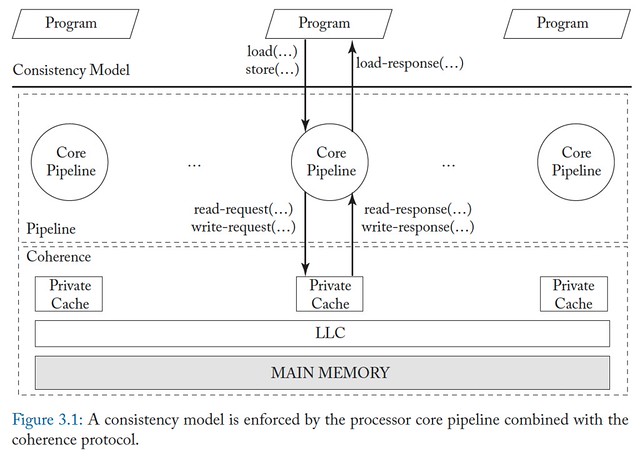
- 我们说 cache consistency 的 cache 其实指的是 core 内部的 private cache,每个 core 都有一个
- LLC == Last-Level Cache, which is shared by all cores
- Despite being on the CPU chip, LLC is logically a “memory-side” cache
- Cores and LLC communicate with each other over an interconnection network
一个具体的 coherence 方案或者实现,我们可以称为 coherence protocol 或者 interface (比如图中的 read-request() 这些)。
我们可以把 coherence protocol 分成两大类:
- Consistency-Agnostic Coherence
- a write is made visible to all other cores before returning (i.e. synchronously propagated)
- 等价于 一个 atomic memory system (with no caches)
- 意味着 core pipeline 可以 assume it is interacting with an atomic memory system with no caches present (i.e. an illusion of atomic memory)
- Consistency-Directed Coherence
- proposed more recently, to support throughput-based GP-GPUs (general-purpose graphics processing units)
- a write can return before it has been made visible to all processors (i.e. asynchronously propagated)
- must ensure that the order in which writes are eventually made visible adheres to the ordering rules mandated by the consistency model
我们这里只讨论 Consistency-Agnostic Coherence.
3.1 Define Consistency-Agnostic Coherence from an Implementation Perspective
Consistency-Agnostic Coherence protocal 必须要满足两个 invariants:
- Single-Writer, Multiple-Read (SWMR) Invariant. $\forall$ memory location $a$, at any given time, $\exists$ only a single core that may write to $a$ (and can also read it), or some number of cores that may only read $a$.
- Data-Value (DV) Invariant. Suppose the value of memory location $a$ is $\vert a \vert$. $\vert a \vert$ at the start of an epoch is the same as $\vert a \vert$ at the end of the its last read-write epoch.
- I.e. once you read a value, you can’t go back and read an older value
3.2 Define Consistency-Agnostic Coherence from a Programmer’s Perspective (i.e. Consistency-like Definition)
学界有多种定义,A Primer on Memory Consistency and Cache Coherence 就列出了 3 种。
Definition 1: A coherent system must appear to execute all threads’ loads and stores to a single memory location in a total order that respects the program order of each thread.
这个定义的好处是说明了:
- coherence is specified on a per-memory location basis
- whereas consistency is specified w.r.t. to all memory locations
A Primer on Memory Consistency and Cache Coherence 还讲:
It is worth noting that any coherence protocol that satisfies the SWMR and DV invariants (combined with a pipeline that does not reorder accesses to any specific location) is also guaranteed to satisfy this consistency-like definition of coherence. (However, the converse is not necessarily true.)
Definition 2: Coherence must implement 2 invariants:
- every write is eventually made visible to all cores
- writes to the same memory location are serialized (i.e., observed in the same order by all cores).
这个定义的特点:
- Invariant 1 is a liveness invariant (good things must eventually happen)
- Invariant 2 is a safety invariant (bad things must not happen)
- Invariant 2 is equivalent to Definition 1
Definition 3: Coherence must implement 3 invariants:
- a
loadto memory location $a$ by a core obtains the value of the previous store to $a$ by that core, unless another core has stored to $a$ in between - a
load$L$ to memory location $a$ obtains the value of astore$S$ to $a$ by another core if $S$ and $L$ “are sufficiently separated in time” and if no otherstoreoccurred between $S$ and $L$ stores to the same memory location are serialized (same as Invariant 2 in the previous definition)
3.3 “Writes are Serialized” 这类的描述很有帮助
以下三种说法其实是一个意思:
- Writes are serialized
- All cores observed (all) the writes in the same order
- All cores agreed on the order of (all) the writes
前面提到的 amon 讲的例子可以帮助我们理解。他说:
- Strict Consistency requires that writes take effect in the order they were executed. This would require atomic writes that propagate immediately to all other processes.
- Sequential Consistency is weaker than Strict Consistency, and it does not require that writes take effect immediately/atomically, but merely that all processes observe writes in the same order, i.e. that they agree on a total order of operations.
假设:
- 我们用
W(x)a表示 “write to memory locationxwith valuea” - 我们用
R(x)a表示 “read memory locationxand get valuea” - 有以下 4 个 processes/threads
W(x)aW(x)bR(x)_; R(x)_;R(x)_; R(x)_;
- 在 $<^{p}$ (program order) 和 $<^{m}$ (global memory order) 的基础上再增加一个 $<^{t}$ (temporal order)
A Strict Consistent Execution is like:
-------------------------------> time
1: W(x)a
2: W(x)b
3: R(x)b R(x)b
4: R(x)b R(x)b
总结这个 Strict Consistent Execution:
- If
W(x)a$<^{t}$W(x)b$\Rightarrow$W(x)a$<^{m}$W(x)b(因为是 atomically write and immediately propagate) - If
W(x)a$<^{m}$W(x)b$\Rightarrow$thread_3和thread_4不可能有R(x)b; R(x)a;这样的结果- 取决于 ordering,
thread_3和thread_4可能的结果有很多,我们这里仅针对我们的例子来说明 - 这也说明 “observe writes in the same order” 的这个 “observe” 并不是 “read” 的意思,更好的理解是:
- “writes become visible to all cores in the same order”
- “all cores witness the writes in the same order”
- 取决于 ordering,
A Sequential Consistent Execution is like:
-------------------------------> time
1: W(x)a
2: W(x)b
3: R(x)b R(x)a
4: R(x)b R(x)a
总结这个 Sequential Consistent Execution:
W(x)a$<^{t}$W(x)b并不能保证W(x)a$<^{m}$W(x)b(可能因为不是 atomically write,也可能因为没有 immediately propagate) (考虑 TSO 的 store buffer)- 这里我们实际有
W(x)b$<^{m}$W(x)a,而且thread_3和thread_4得到的R(x)b; R(x)a;结果是 ok 的- 此时就不可能有
R(x)a; R(x)b;的结果
- 此时就不可能有
amon 用这个例子解释了 SC model 的 “as if”:
The behaviour of all processes was as if they had been executed in a particular order, although this agreed-upon order was different from the actual temporal order. We don’t care about when a write is observed, only about the order between writes.
这个例子本质和 1.2 Litmus Test: Coherence 的例子是一致的:
Litmus Test: Coherence
Can this program see r1 = 1, r2 = 2, r3 = 2, r4 = 1?
(Can Thread 3 see x = 1 before x = 2 while Thread 4 sees the reverse?)
// Thread 1 // Thread 2 // Thread 3 // Thread 4
x = 1 x = 2 r1 = x r3 = x
r2 = x r4 = x
On sequentially consistent hardware: no.
On x86 (or other TSO): no.
On ARM/POWER: no.
-------------------------------> time
1: W(x)1
2: W(x)2
3: R(x)? R(x)?
4: R(x)? R(x)?
不严谨地讲:Coherence can be seen as sequential consistency per memory location
从功能上说:
- Consistency model is visible to the programmer; coherence is not directly visible to the programmer
- Consistency model can use coherence protocol as a black box
- It can be seen that process pipeline and coherence protocol jointly enforce consistency model
4. LL/SC
LL/SC 的全称存在两种写法:
- Load-Link/Store-Conditional
- Load-Linked/Store-Conditional
就蛮无语的。它的本意就是 LL 与 SC 这两个 operations 的 combo.
LL/SC 可以实现对单个 address 的 atomic read-modify-write operation. 存在对 multiple addresses 的版本 LLX/SCX.
4.0 为什么需要 atomic operation?
atomic 是一种技术手段,前面的 Strict Consistency 和 Consistency-Agnostic Coherence 都需要 atomic operations.
4.1 Link 的含义
link 这个名字起得也是蛮奇怪的:
- 首先这里的 link 和 linker 没有关系
- link 是一种 resource marker,但也没到 lock 的程度 (too strong)
- link 更像是 to monitor/watch/reserve 的意思
所以:
- Load-Link 可以理解成:I (as a process/thread) load-and-link a resource
- Load-Linked 可以理解成:I (as a process/thread) load a linked resource
4.2 Conditional 的含义
这里 condition on 的其实就是 linked or not 的状态;Store-Conditional 的意思就是:I (as a process/thread) store a value, but the operation is conditional (on the link).
而且 Store-Conditional 操作成功后会清除掉 link.
4.3 Python 伪码示意
link 在 ARMv8 中是用 Exclusive Monitor 实现的:”link 了一个 address” 在 ARMv8 中就等价于 “把 address 放入 exclusive monitor”.
我们可以考虑最简单的 Local Exclusive Monitor 的情况:
import threading
# This monitor is local to the CPU processor/core
# Note that there is also a Global Exclusive Monitor for all CPU processors/cores
processor_local_exclusive_monitor = dict() # expect <memory_address, list_of_thread_ids> pairs
class Memory:
def __init__(self, address, value):
self.address = address
self.value = value
class Register:
def __init__(self, name):
self.name = name
self.value = None
def load_link(register, memory):
thread_id = threading.get_native_id()
processor_local_exclusive_monitor.setdefault(memory.address, []).append(thread_id) # Make a link
register.value = memory.value
return register.value
def store_conditional(register, memory):
thread_id = threading.get_native_id()
linked_threads = processor_local_exclusive_monitor.get(memory.address, [])
# first link, first serve
if linked_threads and (linked_threads[0] == thread_id):
memory.value = register.value
del processor_local_exclusive_monitor[memory.address] # Clear all links
return True
return False
def atomic_increment(register, memory):
while True:
load_link(register, memory)
register.value += 1
if store_conditional(register, memory):
return
memory = Memory(address="[x0]", value=100)
register = Register(name="w1")
atomic_increment(register, memory)
注意我们这里有点倒反天罡,你肯定不是要用 python 去实现 assembly level 的 LL/SC,这里只是示意。
4.4 ARMv8 Assembly Instructions
上述 Python 伪代码就是下面这段 assembly 的逻辑:
// Using regular LDXR/STXR
// This version guarantee atomicity
// This version doesn't guarantee memory ordering
retry:
ldxr w1, [x0] // Load exclusive - read current value
add w1, w1, #1 // Increment
stxr w2, w1, [x0] // Store exclusive - try to write back
cbnz w2, retry // If store failed (w2 != 0), retry
ret
LDXR: LoaD eXclusive RegisterSTXR: STore eXclusive RegisterCLREX: CLeaR EXclusive (monitor),会被STXR自动调用
更多可以参考 Cliff Fan - ARM64 exclusive Load/Store
4.5 要会动态调整 atomicity 的粒度
考虑 “increment” 这么一个操作,例如 i++。一般 assembly 会需要 3 条 instructions:
- load the value of
ifrom memory into a register - register value
+1 - store the register value to memory
这种情况很容易出现 data race,但如果你的 “increment” 操作整体是 atomic 的,就可以避免 data race.
除了 LL/SC 以外,要注意 assembly 可能本身就有 atomic 的 instruction,比如 ARM v8.1 对比 v8,新增了对下列运算的 single instruction:
- addition
- subtraction
- bitwise operations
比如 addition 就有:
STADD x0, [x1]$\Rightarrow$ atomically add and store as[x1] <- x0 + [x1]STADDL x0, [x1]$\Rightarrow$STADDwith release semantics
4.6 Atomicity + Synchronzation
实际应用时,atomic variable/operations 常常附带 synchronization 功效。
Russ Cox 在 Programming Language Memory Models 中说:
As an aside, these atomic variables or atomic operations would more properly be called “synchronizing atomics.” It’s true that the operations are atomic in the database sense, allowing simultaneous reads and writes which behave as if run sequentially in some order: what would be a race on ordinary variables is not a race when using atomics. But it’s even more important that the atomics synchronize the rest of the program, providing a way to eliminate races on the non-atomic data. The standard terminology is plain “atomic”, though, so that’s what this post uses. Just remember to read “atomic” as “synchronizing atomic” unless noted otherwise.
而且他总结 C++ 有三种 atomics:
- strong synchronization (“sequentially consistent”) atomics
- weak synchronization (“acquire/release”, coherence-only) atomics
- no synchronization (“relaxed”, for hiding races) atomics
我们到后面 C++ 的部分再详述.
5. LA/SR
Load-Acquire/Store-Release 是两个 non-standalone barriers.
5.0 为什么需要 barrier (a.k.a. fence)?
一句话:帮助 weaker-than-SC model 实现 DRF-SC.
考虑一个 weaker-than-SC model. 首先它可能只有 coherence,那么仿照 2.3.2 SC Consistency Model 的定义,这个 model 可能只要求了:
- All cores insert their
loads andstores to the same address into the order $<^{m}$ respecting their $<^{p}$:- If $L(a) <^{p} L’(a) \Rightarrow L(a) <^{m} L(a)$ (
#LoadLoadto same address) - If $L(a) <^{p} S(a) \Rightarrow L(a) <^{m} S(a)$ (
#LoadStoreto same address) - If $S(a) <^{p} S’(a) \Rightarrow S(a) <^{m} S’(a)$ (
#StoreStoreto same address) - If $S(a) <^{p} L(a) \Rightarrow S(a) <^{m} L(a)$ (
#StoreLoadto same address)
- If $L(a) <^{p} L’(a) \Rightarrow L(a) <^{m} L(a)$ (
SC model 的 “regardless of whether they are to the same or different addresses (i.e., $a=b$ or $a \neq b$)” 我这个 weaker-than-SC model 实现不了,那问题来了:我怎么实现 DRF-SC?或者说我怎么能实现类似 $L(a) <^{p} L(b) \Rightarrow L(a) <^{m} L(b)$?
思路是引入 barrier/fence. 若我们能实现:
- If $L(a) <^{p} \operatorname{FENCE} \Rightarrow L(a) <^{m} \operatorname{FENCE}$ (
#LoadFence) where $\operatorname{FENCE}$ is a barrier/fence instruction - If $\operatorname{FENCE} <^{p} L(b) \Rightarrow \operatorname{FENCE} <^{m} L(b)$ (
#FenceLoad)
那我们综合起来就有 $L(a) <^{p} \operatorname{FENCE} <^{p} L(b) \Rightarrow L(a) <^{m} \operatorname{FENCE} <^{m} L(b)$
A Primer on Memory Consistency and Cache Coherence 定义了这么一个 weaker-than-SC model (just as an example, not a standard):
- All cores insert their
loads,stores, andfences into the order $<^{m}$ respecting:- If $L(a) <^{p} \operatorname{FENCE} \Rightarrow L(a) <^{m} \operatorname{FENCE}$ (
#LoadFence) - If $S(a) <^{p} \operatorname{FENCE} \Rightarrow S(a) <^{m} \operatorname{FENCE}$ (
#StoreFence) - If $\operatorname{FENCE} <^{p} \operatorname{FENCE}’ \Rightarrow \operatorname{FENCE} <^{m} \operatorname{FENCE}’$ (
#FenceFence) - If $\operatorname{FENCE} <^{p} L(a) \Rightarrow \operatorname{FENCE} <^{m} L(a)$ (
#FenceLoad) - If $\operatorname{FENCE} <^{p} S(a) \Rightarrow \operatorname{FENCE} <^{m} S(a)$ (
#FenceStore)
- If $L(a) <^{p} \operatorname{FENCE} \Rightarrow L(a) <^{m} \operatorname{FENCE}$ (
- All cores insert their
loads andstores to the same address into the order $<^{m}$ respecting their $<^{p}$- 参上文
- (TSO-style) Every
loadgets its value from the laststorebefore it to the same address, i.e. $\vert L(a) \vert = \vert \max_{<} \lbrace S(a) \mid S(a) <^{m} L(a) \text{ or } S(a) <^{p} L(a) \rbrace \vert$ where $\max_{<}$ denotes “latest in order”
5.1 什么是 Release/Acquire?
来自 Release Consistency (RC),它的主要观点是:(4-way) $\operatorname{FENCE}$ is an overkill,可以改用两个 one-way:
- a synchronization
acquireneeds only a succeeding $\operatorname{FENCE}$ - a synchronization
releaseneeds only a preceding $\operatorname{FENCE}$
formally 有 RC requires that:
- Speicial ordering between
acquire/releaseandload/store- If $\operatorname{ACQ} <^{p} L(a) \Rightarrow \operatorname{ACQ} <^{m} L(a)$ (
#AcquireLoad) - If $\operatorname{ACQ} <^{p} S(a) \Rightarrow \operatorname{ACQ} <^{m} S(a)$ (
#AcquireStore) - If $L(a) <^{p} \operatorname{REL} \Rightarrow L(a) <^{m} \operatorname{REL}$ (
#LoadRelease) - If $S(a) <^{p} \operatorname{REL} \Rightarrow S(a) <^{m} \operatorname{REL}$ (
#StoreRelease)
- If $\operatorname{ACQ} <^{p} L(a) \Rightarrow \operatorname{ACQ} <^{m} L(a)$ (
- SC ordering of
acquires andreleases:#AcquireAcquire#AcquireRelease#ReleaseAcquire#ReleaseRelease
注意 RC 并没有 require 下列类似 #LoadAcquire 的 ordering:
- $L(a) <^{p} \operatorname{ACQ} \not\Rightarrow L(a) <^{m} \operatorname{ACQ}$
- $S(a) <^{p} \operatorname{ACQ} \not\Rightarrow S(a) <^{m} \operatorname{ACQ}$
- $\operatorname{REL} <^{p} L(a) \not\Rightarrow \operatorname{REL} <^{m} L(a)$
- $\operatorname{REL} <^{p} S(a) \not\Rightarrow \operatorname{REL} <^{m} S(a)$
5.2 什么是 non-standard barrier?
barrier (instruction) 可以分两类:
- standalone barrier: 指 instruction 只有 barrier 的作用,比如 ARMv8 的:
DMB(Data Memory Barrier)DSB(Data Synchronization Barrier)ISB(Instruction Synchronization Barrier)
- non-standalone barrier: 指 instruction 是一个组合技,它包括了 barrier 的功能,比如 ARMv8 的:
LDAR(Load-Acquire)STLR(Store-Release)LDAXR(Exclusive Load-Acquire)STLXR(Exclusive Store-Release)
5.3 Load-Acquire/Store-Release
Load-Acquire/Store-Release 是两个 non-standalone barriers,且它们也常常一起作为组合技使用。
- Load-Acquire $\operatorname{LA}(a)$ 可以简单理解成一个 atomic 的 $\overline{L(a); \, \operatorname{ACQ}};$ operation
- Store-Release $\operatorname{SR}(a)$ 可以简单理解成一个 atomic 的 $\overline{\operatorname{REL}; \, S(a);}$ operation
=====================
| LOAD x1, [x0] |
| --- ACQUIRE --- | => #AcquireLoad + #AcquireStore
=====================
=====================
| --- RELEASE --- | => #LoadRelease + #StoreRelease
| STORE x1, [x0] |
=====================
于是有:
- If $\operatorname{LA}(a) <^{p} L(b) \Rightarrow \operatorname{LA}(a) <^{m} L(b)$ (类似
#LoadLoad的效果) - If $\operatorname{LA}(a) <^{p} S(b) \Rightarrow \operatorname{LA}(a) <^{m} S(b)$ (类似
#LoadStore的效果) - If $L(a) <^{p} \operatorname{SR}(b) \Rightarrow L(a) <^{m} \operatorname{SR}(b)$ (类似
#LoadStore的效果) - If $S(a) <^{p} \operatorname{SR}(b) \Rightarrow S(a) <^{m} \operatorname{SR}(b)$ (类似
#StoreStore的效果)
5.4 Problem: (纯使用) Release/Acquire 或者 LA/SR 没法实现 SC
我们在开头 5.0 为什么需要 barrier (a.k.a. fence)? 说 barrier (fence) 的作用是 “帮助 weaker-than-SC model 实现 DRF-SC”,但如果只使用 Release/Acquire 或者 LA/SR 是没法实现 SC 的 ($\operatorname{FENCE}$ 是可以的).
Russ Cox 在 Programming Language Memory Models - Acquire/release atomics 举了一个例子:
Litmus Test: Store Buffering
Can this program see r1 = 0, r2 = 0?
// Thread 1 // Thread 2
x = 1 y = 1
r1 = y r2 = x
On sequentially consistent hardware: no.
On x86 (or other TSO): yes!
On ARM/POWER: yes!
On Java (using volatiles): no.
On C++11 (sequentially consistent atomics): no.
On C++11 (acquire/release atomics): yes!
如果这里我们只有 LA/SR 可以用,那么这个 Litmus Test 的代码就是:
// Thread 1 // Thread 2
x.store(1, REL) y.store(1, REL)
r1 = y.load(ACQ) r2 = x.load(ACQ)
可以更直白地示意为:
// Thread 1 // Thread 2
----- REL ----- ----- REL -----
x.store(1) y.store(1)
r1 = y.load() r2 = x.load()
----- ACQ ----- ----- ACQ -----
这里的 problem 在于:
thread_1的x.store(1)和y.load()可以有 reorderingthread_2的y.store(1)和x.load()可以有 reordering- 除非你这里
----- REL -----和----- ACQ -----围起来的部分只有 “针对 same memory location 的读写”,换言之,这里只有 coherence 能保证对 same memory location 的 SC
Russ Cox 在 Programming Language Memory Models - Acquire/release atomics 是这样总结的:
Recall that the sequentially consistent atomics required the behavior of all the atomics in the program to be consistent with some global interleaving – a total order – of the execution. Acquire/release atomics do not. They only require a sequentially consistent interleaving of the operations on a single memory location. That is, they only require coherence. The result is that a program using acquire/release atomics with more than one memory location may observe executions that cannot be explained by a sequentially consistent interleaving of all the acquire/release atomics in the program, arguably a violation of DRF-SC!
注意他这里说的 “Acquire/release atomics” 指的是 LA/SR,但你上升到 general 的 Release/Acquire 也是一样的,都无法保证 fully SC, 只有 coherence 带来的 same memory location 的 SC. 因为你这里需要一个 #StoreLoad 来保证 x.store(1) 和 y.load()、以及 y.store(1) 和 x.load() 的 order,但 Release/Acquire 很尴尬地恰好没有 #StoreLoad:

(图片来源:Acquire and Release Semantics)
我觉得我们这里需要理解:Release Consistency (RC) 毕竟是 1990 年的作品,理论还在发展中。
5.5 C++ Atomics 中的 LA/SR
基本的 load/store 可以这样写:
#include <atomic>
std::atomic<int> x{0};
std::atomic<int> y{0};
y = atomic_load(&x);
// EQUIVALENT TO
y = x.load();
atomic_store(&x, 1);
// EQUIVALENT TO
x.store(1);
也可以指定你的 consistency model. C++ 的 <atomic> 有定义:
enum memory_order
{
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
所以可以有:
#include <atomic>
std::atomic<int> x{0};
std::atomic<int> y{0};
/* Load-Acquire */
y = atomic_load_explicit(&x, std::memory_order_acquire);
// EQUIVALENT TO
y = x.load(std::memory_order_acquire);
/* Store-Release */
atomic_store_explicit(&x, 1, std::memory_order_release);
// EQUIVALENT TO
x.store(1, std::memory_order_release);
留下评论