Hypothesis Space / Underfitting / Overfitting / Bias / Variance
Hypothesis Space
What exactly is a hypothesis space in the context of Machine Learning?:
Lets say you have an unknown target function $f:X \to Y$ that you are trying to capture by learning. In order to capture the target function you have to come up with some hypotheses $h_1, \dots, h_n$ where $h_i \in H$. Here, $H$ is your hypothesis space or set.
考虑一个 linear regression 的例子,我们要 learn 的是一个 $f = w_1 x_1 + w_2 x_2 + \dots + w_n x_n$。一组 $\mathbf{w}_i = (w_1, w_2, \dots, w_n)$ 可以看作一个 vector,那么 hypothesis space 就可以看作是一个 vector space!
所以 learning 的过程就可以看作:在一个 vector space 中 search 符合条件的最佳的一个 vector。
考虑到 liner regression 的一个最常见的 regularization 就是 $\| \mathbf{w} \|^2 < s$,理由是:如果 $w_i$ 很大,那么 $x_i$ 上很小的变动都可能会引起 predcition 的大变动,容易引起 overfitting。你仔细看一下这个 regularization,不就是相当于把 searching 的空间限定在了 $\| \mathbf{w} \|^2 < s$ 这个圆(2D space)或者球体(3D space)里么?
有了 $\| \mathbf{w} \|^2 < s$ 这个 constraint 之后,我们 searching 的条件就从 optimization 变成了 constrained optimization,然后就可以把 object 写成 lagrangian 形式:$\min \operatorname{cost\_function}(X, Y, \mathbf{w}) - \theta \cdot \operatorname{constraint}(\mathbf{w})$。我们常见的 Ridge Regression (i.e. Regression with $\ell^2$ Regularization)、Lasso Regression (i.e. Regression with $\ell^1$ Regularization) 就是这么来的。
ISL 有图:
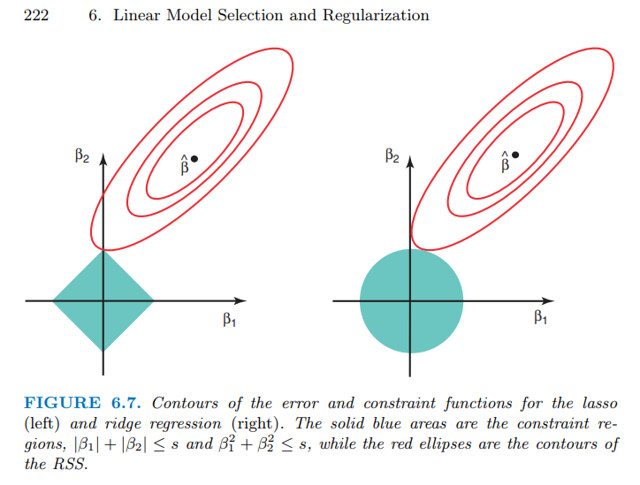
介绍 Hypothesis Space 的最主要的用意是:把 learning 解释成在 vector space 中 search 一个最佳 vector 的过程,这样非常有助于理解 bias 和 variance
Bias / Variance
最直白的还是这张 What are the concise meaning and interpretation of bias and variance in machine learning and statistics? 里的图:
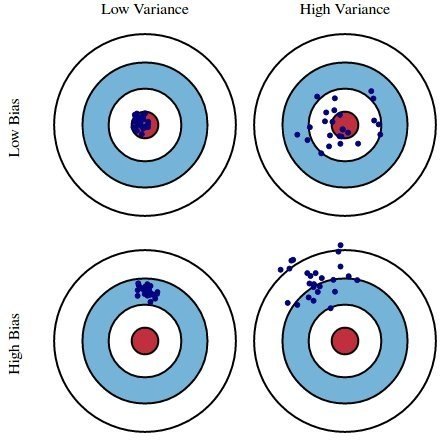
一个蓝色的点表示在一个 dataset 上 learn 到的 $\mathbf{w}$ (注意在这张图里,我们没有必要讨论这是在 training data 还是 test data 上得到结果),红心是真正能反映这个 dataset 规律的 optimum $\mathbf{w’}$。
Bias - Bias means how far off our predictions are from real values.
Variance - Change in predictions across different data sets.
简单说,bias 就是看你 search 的 constraint、也就是 hypothesis space 定得偏不偏颇:hypothesis space 小,发挥的空间就小,如果 hypothesis space 还定偏了,那么不管你怎么换 dataset 都达不到 optimum。
而 variance 就是你 learning algorithm 的稳定性;它是受 hypothesis space 的大小控制的。
打个比方:hypothesis space 太小,learning algorithm 就偏 conservative,不管你怎么换 dataset,它的输出都不够激进、不够多元化,得到的 $\mathbf{w}$ 都很接近,有可能大家都很接近 optimum,也可能都不接近(个体差异小,集体有 bias);hypothesis space 太大,learning algorithm 就偏 liberal,输入不同的 dataset,输出的结果会五花八门,好的好,孬的孬(个体差异大)。
Underfitting / Overfitting
Machine Learning: Overfitting, underfitting:
If your algorithm works well with points in your data set, but not on new points, then the algorithm overfit the data set. And if your algorithm works poorly even with points in your data set, then the algorithm underfit the data set.
注意:到了讨论 Underfitting / Overfitting 的时候,我们必须要区分 training data 和 test data。一般来说,training data 和 test data 的 optimum 很可能是不一样的。假设我们 training data 的 optimum 在上面 Bias / Variance 的那张图的红心,那么很有可能 test data 的 optimum 在红心平移后的某处(想象成做了一个 affine transformation!)。我们假设:
- Algorithm $A$ 在 training dataset $D_{train}$ 上 learn 到的 hypothesis 为 $\mathbf{w}$
- $D_{train}$ 上的 optimum hypothesis 为 $\mathbf{w’}$
- $D_{test}$ 上的 optimum hypothesis 为 $\mathbf{w’’}$
那么:
- Overfitting: $\mathbf{w}$ 接近 $\mathbf{w’}$;但 $\mathbf{w}$ 远离 $\mathbf{w’’}$
- Underfitting: $\mathbf{w}$ 远离 $\mathbf{w’}$;通常情况下 $\mathbf{w}$ 同样远离 $\mathbf{w’’}$
Underfitting is also known as high bias
这句话不够准确。因为 underfitting 是 algorithm 在单个 dataset 上的表现,你是不可能推测出 algorithm 在不同 dataset 上的整体表现的。但是反过来,如果 algorithm 是 high bias 且 low variance 的,那么对它输入不同的 dataset,最终结果都会是 underfitting
Overfitting is also known as high variance
同理,你不能用 algorithm 在单个 dataset 上的表现去推测 algorithm 在不同 dataset 上的整体表现。反过来讲,如果 algorithm 是 high variance 且 low bias 的,你的 $\mathbf{w}$ 虽然很接近 $\mathbf{w’}$,但可能并不是最接近的 $\mathbf{w’’}$ 的那个 (high variance 提供了找到更好的 $\mathbf{w}$ 的可能性)。
类似的结论其实非常误导人。在此,我想引用 Konstantin Tretyakov 在 Quora: Why do overfit models have high variance but low bias? 的答案:
A simple way to “fix” your understanding would be to say that, “linguistically”, the underfitting models are biased “away” from training data.
It might be better, however, to rely on a slightly deeper understanding than plain linguistic intuition here, so bear with me for a couple of paragraphs.
The terms “bias” and “variance” do not describe a single trained model. Instead, they are meant to describe the space of possible models among which you will be picking your fit, as well as the method you will use to select this best fit.
No matter what space and method you choose, the model that you find as a result of training is most often not the “true” model that generated your data. The “bias” and “variance” are the names of two important factors, which contribute to your error.
- Firstly, your space of models / fitting method may be initially biased. That is, the “true” model may not be part of your model space at all. And even if it were, you may be using a fitting method which deliberately misses the correct answer on average, thus introducing the “bias error”
- Secondly, your space of models may be so large that you will have a hard time finding that particular “true” model within your space. This factor is known as the “variance error”
Consequently, when you are dealing with “narrow” model spaces, you are in a situation when the true model is most probably not within your space (“high bias”), however, you have little problem finding the best possible model within that narrow space (“low variance”). On the other hand, when you fit a model from a “large” space, even though the true model may be part of it (“low bias”), there will be millions of confusingly similar models for you to pick from, and hence a very low chance to stumble upon the correct one (“high variance”).
最后注意 feature 的增减对 hypothesis space 的影响:
- 引入新的 feature $x_j$,也就会引入新的 parameter $w_j$,所以 $\mathbf{w}$ 会加一维,hypothesis space 变大(缓解 underfitting)
- 去掉 feature $x_i$,也就会去掉相应的 parameter $w_i$,所以 $\mathbf{w}$ 会减一维,hypothesis space 变小(缓解 overfitting)
留下评论