Digest of Fluent Python: Part II - Data Structures (sequence types, dicts, sets, strings, bytes, unicode)
Chapter 2 - An array of Sequences
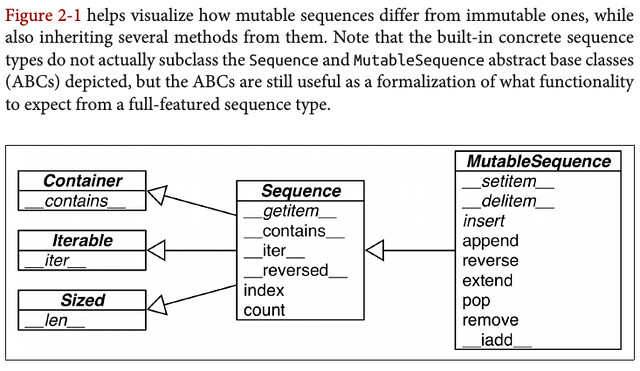
2.1 Overview of Built-In Sequences
Python inherited from ABC the uniform handling of sequences. Strings, lists, byte sequences, arrays, XML elements, and database results share a rich set of common operations including iteration, slicing, sorting, and concatenation.
Group sequence types by element types:
- Container Sequences (can hold items of different types):
listtuplecollections.deque
- Flat Sequences (hold items of one type):
strbytesbytearraymemoryviewarray.array
Container sequences hold references to the objects they contain, which may be of any type, while flat sequences physically store the value of each item within its own memory space, and not as distinct objects. Thus, flat sequences are more compact, but they are limited to holding primitive values like characters, bytes, and numbers.
Group sequence types by mutability:
- Mutable Sequences
listbytearrayarray.arraycollections.dequememoryview
- Immutable Sequences
tuplestrbytes
2.2 listcomps / genexps
my_list = [x**2 for x in range(0, 10)] # list comprehension
my_tuple = tuple(x**2 for x in range(0, 10)) # generator expression
import array
# Both OK; "I" for unsigned int. See https://docs.python.org/3/library/array.html
my_array_1 = array.array("I", (i**2 for i in range(0, 10))) # generator expression
my_array_2 = array.array("I", [i**2 for i in range(0, 10)]) # list comprehension
N.B. my_tuple above is NOT a good example of generator because actually (x**2 for x in range(0, 10)) is indeed a generator expression and returns a generator. The code of my_tuple above is NOT equal to:
my_gen = (x**2 for x in range(0, 10)) # OK. my_gen is a generator object
my_tuple = tuple(my_gen) # OK, but my_tuple == ()
my_tuple = tuple(*my_gen) # Syntax Error
so tuple(x**2 for x in range(0, 10)) is actually a special constructor of tuple. You cannot construct a tuple from a generator object manually.
To better understand generators, please read:
- nvie: Iterables vs. Iterators vs. Generators
- PEP 255 - Simple Generators
- stack overflow: Understanding Generators in Python
2.3 Tuples Are Not Just Immutable Lists
2.3.1 Tuples as Records
point_a = (-1, 1)
point_b = (2, 3)
2.3.2 Tuple Unpacking
point_a = (-1, 1)
x_a, y_a = point_a
print(x_a) # -1
print(y_a) # 1
An elegant application of tuple unpacking is swapping the values of variables without using a temporary variable:
b, a = a, b
2.3.3 Nested Tuple Unpacking
top_left, top_right, bottom_left, bottom_right = (0, 1), (1, 1), (0, 0), (1, 0)
square = (top_left, top_right, bottom_left, bottom_right)
(top_left_x, top_left_y), (top_right_x, top_right_y) = square[0:2]
Note that: square[0:2] == ((0, 1), (1, 1)) while square[0] == (0, 1) not ((0, 1)). In fact, python will evaluate ((0, 1)) as (0, 1).
2.3.4 namedtuple
The collections.namedtuple(typename, field_names) is a factory function that produces subclasses of tuple named typename and enhanced with accessibility via field_names. 一般的用法是:
import collections
Point = namedtuple('Point', ['x', 'y'])
p_a = Point(0, 1)
print(p_a.x) # 0
print(p_a[1]) # 1
为啥要 typename = namedtuple(typename, ...)?这是因为这个 “subclasses of tuple named typename” 是在它 constructor 内部的一个临时 namespace 创建的 (通过 exec),然后这个 subclass typename 的实体会被 constructor 返回,但是它的 name — 也就也是 typename — 并不会随着 return 被带到 constructor 所在的 namespace。我们在外部再赋值一下,主要是为了保持一致,使得这个 subclass 的 name 不管是在它创建的临时 namespace 里还是当前的 namespace 里都叫 typename,避免产生不必要的误解。当然,你写成 Bar = namedtuple('Foo', ...) 是合法的,是没有问题的。
更多内容可以参见:
- How namedtuple works in Python 2.7
- Breakdown: collections.namedtuple
- Be careful with exec and eval in Python
- Python collections source code
2.4 Slicing
在 2.1 我们讲过,所有的 sequence type 都支持 “iteration, slicing, sorting, and concatenation”.
To evaluate the expression seq[start:stop:step], Python calls seq[slice(start, stop, step)] then seq.__getitem__(slice(start, stop, step)). (因为 1. 里有讲 __getitem__ method delegates to [] operator)
start 默认是 0;stop 默认是 len(seq) (exclusively);step 默认是 1,而且它是连冒号也可以省略的。E.g.
s = 'bicycle's[:2] == s[0:2] == s[:2:] == s[0:2:] == s[:2:1] == s[0:2:1] == 'bi's[2:] == ... == 'cycle's[::2] == bcce
Instead of filling your code with hardcoded slices, you can name them. 比如一个固定格式的 invoice 字符串,它的 price、description 什么的都是定长的,我们可以这样:
price = slice(start1, stop1, [step1])
desc = slice(start2, stop2, [step2])
for invoice in invoice_list:
print(invoice[price], invoice[desc])
对于取下来的 sequence slice,我们可以直接用赋值来修改这个 sequence slice 进而直接修改 sequence 的值。这进一步说明:sequence slice 其实是 reference. E.g.
>>> l = list(range(10))
>>> l
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
>>> l[2:5] = [20, 30]
>>> l
[0, 1, 20, 30, 5, 6, 7, 8, 9]
>>> del l[5:7]
>>> l
[0, 1, 20, 30, 5, 8, 9]
>>> l[3::2] = [11, 22]
>>> l
[0, 1, 20, 11, 5, 22, 9]
>>> l[2:5] = 100
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: can only assign an iterable
>>> l[2:5] = [100]
>>> l
[0, 1, 100, 22, 9]
When the target of the assignment is a slice, the right side must be an iterable object, even if it has just one item.
The [] operator can also take multiple indexes or slices separated by commas. This is used, for instance, in the external NumPy package, where items of a two-dimensional numpy.ndarray can be fetched using the syntax a[i, j] and a two-dimensional slice obtained with an expression like a[m:n, k:l]. 实现上,它们的 __getitem__() 和 __setitem__() 是接收 tuple 的,比如:to evaluate a[i, j], Python calls a.__getitem__((i, j)).
The Ellipsis object — written as three full stops ... — is the single instance of the ellipsis class. NumPy uses ... as a shortcut when slicing arrays of many dimensions; for example, if x is a fourdimensional array, x[i, ...] is a shortcut for x[i, :, :, :,].
2.5 Using + and * with Sequences
Beware of expressions like a * n when a is a sequence containing mutable items. E.g. my_list = [[]] * 3 will result in a list with three references to the same inner list.
创建一个预分配长度为 5 的 list 我们可以用 lst = [None] * 5。那么现在我要一个 [lst, lst, lst] 的 list of lists 该怎么办?
llst = [[None] * 5 for _ in range(3)] # OK
lref = [[None] * 5] * 3 # Legal but this is a list of 3 references to one list of 5
鉴定是 list of lists 还是 list of references 可以用 id() 方法,类似 java 的 hashcode。
In [3]: for lst in llst:
...: print(id(lst))
...:
2343147973832
2343148089224
2343148087880
In [5]: for lst in lref:
...: print(id(lst))
...:
2343148276680
2343148276680
2343148276680
2.6 lst.sort() vs sorted(lst)
lst.sort()sorts in place—that is, without making a copy oflst.- A drawback: cannot cascade calls to other methods.
sorted(lst)creates a new list and returns it.lstdoes not change.
这两个方法的参数都是一样的:
reverse: booleankey: the function that will be applied to items to generate the sorting key.- 默认是 identity function,相当于是
key = lambda x:x,直接比较 item 本身 - 比如
key = str.lowermeans sorting case-insensitively - 比如
key = lenmeans sorting by the length of each item - 比如
key = intmeans sorting by values ofint(item)
- 默认是 identity function,相当于是
2.7 Managing Ordered Sequences with bisect Module
bisection 中文意思就是 “二分法”。
bisect.bisect(haystack, needle) does a binary search for needle in haystack — which must be a sorted sequence — and returns the index where needle can be inserted while maintaining haystack in ascending order.
You could use the result of bisect.bisect(haystack, needle) as the index argument to haystack.insert(index, needle) — however, using bisect.insort(haystack, needle) does both steps, and is faster.
See Python: Binary Search / Bisection / Binary Search Tree (BST).
2.8 When a List Is Not the Answer
2.8.1 array.array
If the list will only contain numbers, an array.array is more efficient than a list.
When creating an array.array, you provide a typecode, a letter to determine the underlying C type used to store each item in the array.
- For example,
'b'is the typecode for signed char. If you create anarray('b'), then each item will be stored in a single byte and interpreted as an integer from $–128$ to $127$. - For large sequences of numbers, this saves a lot of memory.
- E.g. an
array('f')does not holdfloatobjects but only the bytes representing the values.
- E.g. an
- And Python will not let you put any number that does not match the type for the array.
2.8.2 memoryview(array)
一个 array 可以有多种表示,比如二进制、八进制。memoryview 就是用来显示这些不同的表示的。如果修改 memoryview 自然会修改到底层的 array 的值。这进一步说明:sequence 是 mutable 的。
>>> numbers = array.array('h', [-2, -1, 0, 1, 2]) # 'h' for signed short
>>> memv = memoryview(numbers)
>>> memv_oct = memv.cast('B') # 'B' for unsigned char
>>> memv_oct.tolist()
[254, 255, 255, 255, 0, 0, 1, 0, 2, 0]
2.8.3 collections.deque and Other Queues
collections.deque is a thread-safe double-ended queue designed for fast inserting and removing from both ends.
Chapter 3 - Dictionaries and Sets
Digress: What Is Hashable?
An object is hashable if it has a hash value which never changes during its lifetime (it needs a __hash__() method), and can be compared to other objects (it needs an __eq__() method). Hashable objects which compare equal must have the same hash value.
- The atomic immutable types (str, bytes, numeric types) are all hashable.
- A
frozensetis always hashable, because its elements must be hashable by definition. - A
tupleis hashable only if all its items are hashable.- At the time of this writing, the Python Glossary states: “All of Python’s immutable built-in objects are hashable” but that is inaccurate because a tuple is immutable, yet it may contain references to unhashable objects.
>>> tt = (1, 2, (30, 40))
>>> hash(tt)
8027212646858338501
>>> tl = (1, 2, [30, 40])
>>> hash(tl)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> tf = (1, 2, frozenset([30, 40]))
>>> hash(tf)
-4118419923444501110
User-defined types are hashable by default because their hash value is their id() and they all compare not equal.
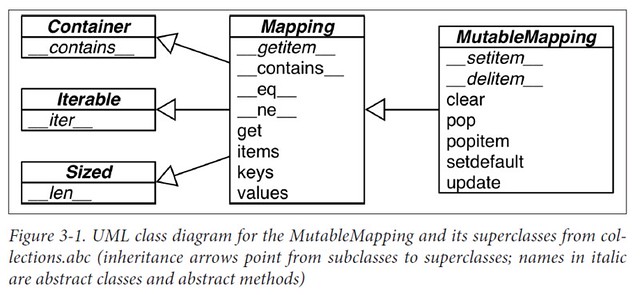
3.1 Generic Mapping Types
In [6]: from collections import abc
In [7]: isinstance({}, abc.MutableMapping)
Out[7]: True
All mapping types in the standard library use the basic dict in their implementation, so they share the limitation that the keys must be hashable.
3.2 dictcomp
创建 dict 的语法真是多种多样……
>>> a = dict(one=1, two=2, three=3)
>>> b = {'one': 1, 'two': 2, 'three': 3}
>>> c = dict(zip(['one', 'two', 'three'], [1, 2, 3]))
>>> d = dict([('two', 2), ('one', 1), ('three', 3)])
>>> e = dict({'three': 3, 'one': 1, 'two': 2})
>>> a == b == c == d == e
True
In addition to the literal syntax and the flexible dict constructor, we can use dict comprehensions to build dictionaries.
>>> DIAL_CODES = [
... (86, 'China'),
... (91, 'India'),
... (1, 'United States'),
... (62, 'Indonesia'),
... (55, 'Brazil'),
... (92, 'Pakistan'),
... (880, 'Bangladesh'),
... (234, 'Nigeria'),
... (7, 'Russia'),
... (81, 'Japan'),
... ]
>>> country_code = {country: code for code, country in DIAL_CODES}
>>> country_code
{'China': 86, 'India': 91, 'Bangladesh': 880, 'United States': 1,
'Pakistan': 92, 'Japan': 81, 'Russia': 7, 'Brazil': 55, 'Nigeria':
234, 'Indonesia': 62}
>>> {code: country.upper() for country, code in country_code.items() if code < 66}
{1: 'UNITED STATES', 55: 'BRAZIL', 62: 'INDONESIA', 7: 'RUSSIA'}
3.3 Handling Missing Keys with dict.setdefault()
d.get(k, default) is an alternative to d[k] whenever a default value is more convenient than handling KeyError.
setdefault(key[, default]):
- If
keyis ind, returnd[key]. - If not, insert
d[key] = defaultand returndefault. defaultdefaults toNone.
与 [] 可以组合成这么一个 combo:
d.setdefault(key, []).append(new_value)
- 如果
d[key]存在,就 append - 如果
d[key]不存在,就创建一个[]然后 append
3.4 Handling Missing Keys with collections.defaultdict or __missing__()
defaultdict(default_factory):
default_factoryis a callable that is used to produce a default value whenever__getitem__(key)is called with a nonexistentkey.- N.B only for
__getitem__()calls. Therefore ifddis adefaultdictandkeyis a missing key:dd[key]will return the default value created bydefault_factory()dd.get(k)will returnNone
Another way to handle missing keys is to extend a dict and implement the __missing__() method.
__missing__()is just called by__getitem__()
3.5 Variations of dict
collections.OrderedDict: Maintains keys in insertion order.collections.ChainMap(dict1, dict2):- 先在
dict1里查,有就 return;没有就继续去dict2里查。 dict1和dict2可以有相同的 key。- 查找的顺序只和构造器的参数顺序有关。
- 先在
collections.Counter: A mapping that holds an integer count for each key. Updating an existing key adds to its count.
3.6 Subclassing UserDict
UserDict is designed to be subclassed. It’s almost always easier to create a new mapping type by extending UserDict rather than dict.
Note that UserDict does not inherit from dict, but has an internal dict instance, called data, which holds the actual items.
- 组合优于继承 again!
- 所以
UserDict既不是一个 interface 也不是一个 abstract class,它是一个 Mixin
3.7 Immutable Mappings
The mapping types provided by the standard library are all mutable, but you may need to guarantee that a user cannot change a mapping by mistake.
Since Python 3.3, the types module provides a wrapper class called MappingProxyType, which, given a mapping, returns a mappingproxy instance that is a read-only but dynamic view of the original mapping. This means that updates to the original mapping can be seen in the instance, but changes cannot be made through it.
>>> from types import MappingProxyType
>>> d = {1: 'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({1: 'A'})
>>> d_proxy[1]
'A'
>>> d_proxy[2] = 'x'
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'mappingproxy' object does not support item assignment
>>> d[2] = 'B'
>>> d_proxy
mappingproxy({1: 'A', 2: 'B'})
>>> d_proxy[2]
'B'
3.8 set
setelements must be hashable.setitself is not hashable.frozensetis hashable, so you can havefrozensetinside aset
3.8.1 set Literals
s = {1, 2, 3}
- To create an empty set, you should use the constructor without an argument:
s = set(). - If you write
s = {}, you’re creating an emptydict.
3.8.2 setcomp
>>> from unicodedata import name
>>> {chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i), '')}
{'§', '=', '¢', '#', '¤', '<', '¥', 'μ', '×', '$', '¶', '£', '©',
'°', '+', '÷', '±', '>', '¬', '®', '%'}
3.8.3 Set Operations
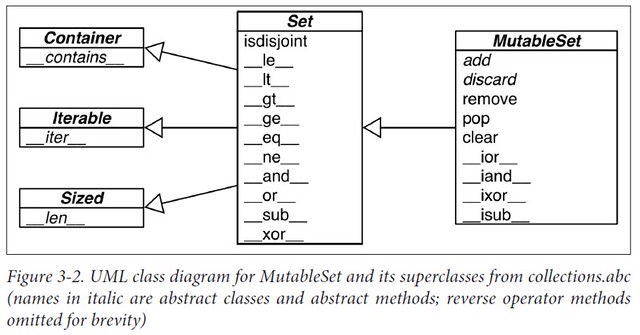
Given two sets a and b and an element e:
a & b: the intersection;a | b: the union;a - b: the difference!a < b: isaa proper subset ofb?a <= b: isaa subset ofb?a > b: isaa proper superset ofb?a >= b: isaa superset ofb?a.discard(e): removeefromaif it is presenta.remove(e): removeefroma, raisingKeyErrorifenot ina
3.9 dict and set Under the Hood
A hash table is a sparse array (i.e., an array that always has empty cells). In standard data structure texts, the cells in a hash table are often called “buckets.” In a dict hash table, there is a bucket for each item, and it contains two fields: a reference to the key and a reference to the value of the item. Because all buckets have the same size, access to an individual bucket is done by offset.
The hash() built-in function works directly with built-in types and falls back to calling __hash__() for user-defined types. If two objects compare equal, their hash values must also be equal. For example, because 1 == 1.0 is true, hash(1) == hash(1.0) must also be true, even though the internal representation of an int and a float are very different.
To fetch the value at my_dict[search_key], Python calls hash(search_key) to obtain the hash value of search_key and uses the least significant bits of that number as an offset to look up a bucket in the hash table (the number of bits used depends on the current size of the table). If the found bucket is empty, KeyError is raised. Otherwise, the found bucket has an item—a found_key:found_value pair—and then Python checks whether search_key == found_key. If they match, that was the item sought: found_value is returned.
However, if search_key and found_key do not match, this is a hash collision. In order to resolve the collision, the algorithm then takes different bits in the hash, massages them in a particular way, and uses the result as an offset to look up a different bucket. If that is empty, KeyError is raised; if not, either the keys match and the item value is returned, or the collision resolution process is repeated.
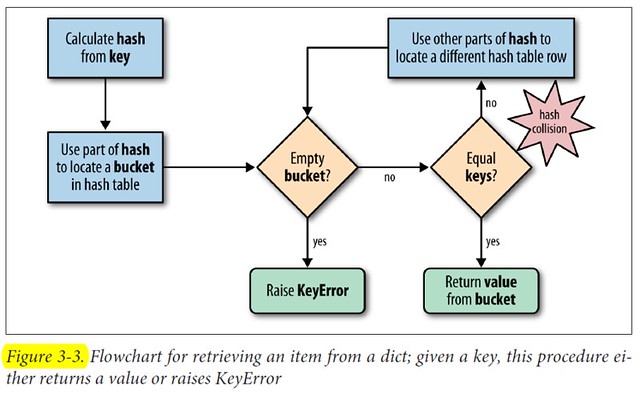
The process to insert or update an item is the same, except that when an empty bucket is located, the new item is put there, and when a bucket with a matching key is found, the value in that bucket is overwritten with the new value.
Additionally, when inserting items, Python may determine that the hash table is too crowded and rebuild it to a new location with more room. As the hash table grows, so does the number of hash bits used as bucket offsets, and this keeps the rate of collisions low.
dicts have significant memory overhead
Because a dict uses a hash table internally, and hash tables must be sparse to work, they are not space efficient. For example, if you are handling a large quantity of records, it makes sense to store them in a list of tuples or named tuples instead.
But remember:
Optimization is the altar where maintainability is sacrificed.
Key search is very fast
The dict implementation is an example of trading space for time: dictionaries have significant memory overhead, but they provide fast access regardless of the size of the dictionary — as long as it fits in memory.
Adding items to a dict may change the order of existing keys
Whenever you add a new item to a dict, the Python interpreter may decide that the hash table of that dictionary needs to grow. This entails building a new, bigger hash table, and adding all current items to the new table. During this process, new (but different) hash collisions may happen, with the result that the keys are likely to be ordered differently in the new hash table. All of this is implementation-dependent, so you cannot reliably predict when it will happen. If you are iterating over the dictionary keys and changing them at the same time, your loop may not scan all the items as expected.
This is why modifying the contents of a dict while iterating through it is a bad idea. If you need to scan and add items to a dictionary, do it in two steps: read the dict from start to finish and collect the needed additions in a second dict. Then update the first one with it.
How Sets Work
The set and frozenset types are also implemented with a hash table, except that each bucket holds only a reference to the element.
The underlying hash table determines the behavior of a dict applies to a set. Without repeating the previous section, we can summarize it for sets with just a few words:
setelements must be hashable objects.sets have a significant memory overhead.- Membership testing is very efficient.
- Adding elements to a
setmay change the order of other elements.
Chapter 4 - Text vs Bytes
4.1 Character Issues
The Unicode standard explicitly separates the identity of characters from specific byte representations. 我们来学习一下相关的词汇:
- code point: the identity of a character. 也就是我们所谓的 “Unicode 编码”,比如 “A” 的 code point 就是 “U+0041”
- code points $\rightarrow$ bytes 的过程我们称为 encoding;
- bytes $\rightarrow$ code points 的过程我们称为 decoding;
- encode 可以理解为 “编成机器码”,byte 也是一种码嘛~
- 但同时 encoding 这个词也可以表示这一套编解码的规则:An encoding is an algorithm that converts code points to byte sequences and vice versa.
- codec 是 coder-decoder 的简称,co(der)-dec(oder)
- 我们也可以理解为一套 encoding 规则对应一个 codec
- code page 则是一张 $\operatorname{f}: \text{code point} \rightarrow \text{byte}$ 的 lookup table
>>> s = 'café'
>>> b = s.encode('utf8') # Encode `str` to `bytes` using UTF-8 encoding.
>>> b
b'caf\xc3\xa9' # `bytes` literals start with a `b` prefix.
>>> b.decode('utf8') # Decode `bytes` to `str` using UTF-8 encoding.
'café'
Digress: BOM
BOM stands for Byte-Order Mark.
The UTF-8 BOM is a sequence of bytes that allows the reader to identify a file as being encoded in UTF-8.
Normally, the BOM is used to signal the endianness of an encoding, but since endianness is irrelevant to UTF-8, the BOM is unnecessary.
| BOM Bytes | Encoding Form |
|---|---|
| “00 00 FE FF” | UTF-32, big-endian |
| “FF FE 00 00” | UTF-32, little-endian |
| “FE FF” | UTF-16, big-endian |
| “FF FE” | UTF-16, little-endian |
| “EF BB BF” | UTF-8 |
4.2 Byte Essentials
The new binary sequence types are unlike the Python 2 str in many regards. The first thing to know is that there are two basic built-in types for binary sequences: the immutable bytes type introduced in Python 3 and the mutable bytearray, added in Python 2.6. (Python 2.6 also introduced bytes, but it’s just an alias to the str type, and does not behave like the Python 3 bytes type.)
Each item in bytes or bytearray is an integer from 0 to 255, and not a one-character string like in the Python 2 str.
my_bytes[0]retrieves an intmy_bytes[:1]returns a bytes object of length 1 (i.e. always a sequence)- however,
my_str[0] == my_str[:1]
4.3 Basic Encoders/Decoders
Each codec has a name, like utf_8, and often aliases, such as utf8, utf-8, and U8. 其他常见的 codec 还有:
latin1a.k.a.iso8859_1cp1252cp437gb2312utf-16le
4.4 Understanding Encode/Decode Problems (略)
4.5 Handling Text Files
If the encoding argument was omitted when opening the file to write, the locale default encoding would be used. Always pass an explicit encoding= argument when opening text files.
- On GNU/Linux and OSX all of these encodings are set to UTF-8 by default, and have been for several years.
- On Windows, not only are different encodings used in the same system, but they are usually codepages like
cp850orcp1252that support only ASCII with 127 additional characters that are not the same from one encoding to the other.
留下评论