Tensorflow 2.0 Autograph and Tracing: an example
首先说下为啥需要把代码转成 graph。我觉得可能主要有两点考虑:
- 把 graph 当做一种中间代码。类似 Java 的 “一次编译,到处运行”,graph 也可以在多平台上运行 (比如 TensorFlow Lite?)
- 针对 graph 有专门的 CPU/GPU/TPU 优化
那把代码转成 graph 其实有 3 个步骤 (Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow 这张图上只标了两步,有点 misleading):
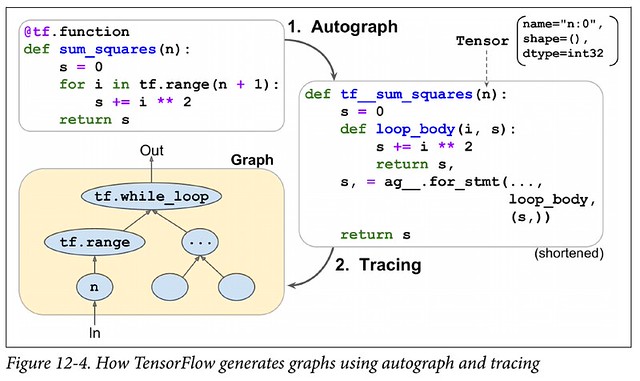
- Autograph
- 把原生 python 代码转成中间 python 代码
- 我要吐槽下这个名字:autograph 并没有把代码 automatically 转化成 graph 啊,这才第一步啊,这个名字是不是欠妥?
- Symbolic Execution
- 就是右上角传入的那个
n,我们称之为 symbolic tensor (只有符号意义,没有实际的值) - 你可以把这个 symbolic execution 想象成是 debugging 时一步步 step over 的过程 (然后 tracer 来 trace)
- 就是右上角传入的那个
- Tracing
- Tracer 对 symbolic execution 的代码会区别对待:
- 如果遇到的是一个 Tensorflow operation (简单说就是
tf.XXX()代码),会把这个 operation 当做一个节点添加到 graph 里 - 如果不是,那么 tracer 会直接执行这句代码,但是不会把它加到 graph 里
- 这也就是 Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow 里说的 “code running only during tracing”
- 也就是说,如果 calling 一个
@tf.function函数没有引发 tracing 或者 re-tracing,这段代码是不会被执行的 (而是直接去执行 graph 代码了,但是 graph 又不会包含这句代码,相当于是跳过了)
- 也就是说,如果 calling 一个
- 这也就是 Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow 里说的 “code running only during tracing”
- 如果遇到的是一个 Tensorflow operation (简单说就是
- Tracing 完了,graph 就生成完了。
- Tracer 对 symbolic execution 的代码会区别对待:
那么一个 @tf.function 函数什么时候会生成 graph?我个人的总结是:
- 第一次调用时会调用 Autograph 和 Tracing,然后执行
- 后续的调用
- 如果没有引发 re-tracing,那么就直接执行 (应该是去直接执行 graph 了)
- 如果引发了 re-tracing,那么应该会再次执行 tracing (但是应该没有必要从 autograph 执行起)
那么什么时候会引发 re-tracing 呢?其实每个 @tf.function function 会维护一个类似 <trace_cache_key, graph> 的 caching dict。TensorFlow 2.0 RFC: Functions, not Sessions 有讲:
假定:
fis a Python function that returns zero or more TensorsF = tf.function(f)
Every time F is invoked in the Python program, a trace_cache_key is computed as a function of:
- The element datatype and shape of every Tensor argument
- The length of the list, and
(dtype, shape)of every element in the list of Tensor argument - The concrete value of non-Tensor (and list of Tensor) Python object arguments
- The “context” in which
Fis invoked (e.g., the device prescribed by thetf.device()scope in whichFis invoked).
When F is invoked it:
- Potentially casts inputs to tensors if an input signature was specified, see the “Input Signatures” section below.
- Determines a
trace_cache_key(based on the types and/or values of the arguments). - Every time a new
trace_cache_keyis encountered, it invokesfto create a TensorFlow graph,G. If thetrace_cache_keyhas been seen before, it looks upGfrom a cache. - It executes the graph defined by
G, feeding each argument as a value of the corresponding node in the graph, and returns a tuple of Tensors (or list of Tensors).
补充一点,按照 Analyzing tf.function to discover AutoGraph strengths and subtleties - part 2 的实验结果,对 python primitive numerical values,1 == 1.0,所以先调用 F(1) 再调用 F(1.0) 不会引发 re-tracing。但是如果你先传一个 int tensor 再传一个 float tensor (假定 shape 相同),肯定会触发 re-tracing
以上是一般规律,但是下面这个例子我觉得是个 corner case,目前我还不知道如何解释。以下修改自 Hands-On Machine Learning with Scikit-Learn, Keras, and Tensorflow:
import tensorflow as tf # TF 2.0 beta
import numpy as np
import os
# Only GPU #0 will be used
# 我装了一块 Titan Z,有两个 GPU devices,貌似会自动并行计算;
# 于是限定只用一个 GPU,disable 掉自动并行
os.environ["CUDA_VISIBLE_DEVICES"] = "0"
np.random.seed(1000)
@tf.function
def my_rnd(x):
return np.random.rand()
if __name__ == '__main__':
print(my_rnd(tf.constant(2)))
print(my_rnd(tf.constant(3)))
# Output:
# tf.Tensor(0.6535896, shape=(), dtype=float32)
# tf.Tensor(0.6535896, shape=(), dtype=float32)
- 首先第二次调用肯定没有引发 re-tracing
- 第二这个 graph 应该是个空的,因为没有
tf.XXX()语句 - 那为什么两次返回的结果是一样的?graph 为空的时候是如何执行这个代码的?待查
如果改成下面这样,两次执行会返回不同的结果:
@tf.function
def my_rnd2(x):
return tf.random.uniform([])
@tf.function 的源代码在 tensorflow/tensorflow/python/eager/def_function.py:
- 第一次调用时,Autograph 应该是
class Function的__call__中的self._initialize(args, kwds, add_initializers_to=initializer_map)这句 - 第一次调用时的 tracing 和 execution 应该是
class Function的__call__中的return self._concrete_stateful_fn._filtered_call(canon_args, canon_kwds)这句 - 第二次调用,如果没有引发 re-tracing,execution 应该是执行
class Function的__call__中的results = self._stateful_fn(*args, **kwds)这句
留下评论