Lab Memo: Use Cases for Pipeline Refactoring
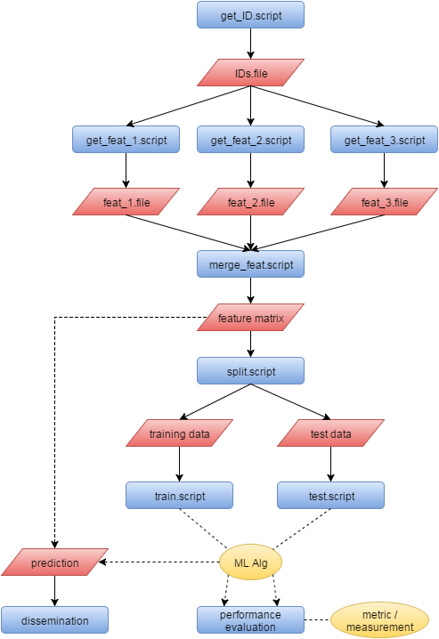
For pipeline refactoring, there are several use cases that need special attention:
- How to easily switch to a new ML alg? Or use multiple ML algs together in one run?
- How to integrate new features?
- How to integrate new metric?
- Get ready for the update for existing features.
- E.g. the remote databases might update their records without notification.
- E.g. snapshots for remote data at local storage
- E.g. data serialization
- This is a specific issue of “Persistence and Traceability”
- We’ll switch to new assembly some day.
- We’ll have new ground-truth cases some day. Prepare to rerun the pipeline.
- We might need to make prediction for millions of examples. Speed it up?
- Persistence and Traceability
There is another issue for engineering:
- Better project/folder structure for
- multilingual scripts, and
- intermediate/final data files
留下评论