Digest of Advanced R (亟待更新)
P.S. It was 2015 when the 1st edition of this book came out and I wrote this post. Now Hadley Wickham is working on the 2nd edition where a lot contents changed.
TODO: Update or delete this post.
Part I. Foundations
1. Data structures
| Homogeneous | Heterogeneous | |
|---|---|---|
| 1-d | Atomic vector | List |
| 2-d | Matrix | Data frame |
| n-d | Array |
Note that R has no 0-dimensional, or scalar types. Individual numbers or strings, which you might think would be scalars, are actually vectors of length one.
1.1 Quiz
Q: What are the three properties of a vector, other than its contents?
- The three properties of a vector
xaretypeof(x),length(x), andattributes(x).
Q: What are the four common types of atomic vectors? What are the two rare types?
- The four common types of atomic vector are logical, integer, double (sometimes called numeric), and character. The two rarer types are complex and raw.
- atomic 本身并没有指特定的某种类型,你理解为 primitive 就好了
Q: What are attributes? How do you get them and set them?
- Attributes allow you to associate arbitrary additional metadata to any object. You can get and set individual attributes with
attr(x, "y")andattr(x, "y") <- value;or get and set all attributes at once withattributes(x)(implemented as a list).
Q: How is a list different from an atomic vector? How is a matrix different from a data frame?
- The elements of a list can be any type (even a list); the elements of an atomic vector are all of the same type. Similarly, every element of a matrix must be the same type; in a data frame, the different columns can have different types.
Q: Can you have a list that is a matrix? Can a data frame have a column that is a matrix?
- You can make “list-array” by assuming dimensions to a list. You can make a matrix a column of a data frame with
df$x <- matrix(), or usingI()when creating a new data framedata.frame(x = I(matrix())).
1.2 Atomic Vectors
c() means “combine”.
# 你没看错,你没写小数点也默认是 double
dbl_var <- c(1, 2, 4)
# With the L suffix, you get an integer rather than a double
int_var <- c(1L, 6L, 10L)
# Use TRUE and FALSE (or T and F) to create logical vectors
log_var <- c(TRUE, FALSE, T, F)
# string vector
chr_var <- c("these are", "some strings")
Atomic vectors are always flat, even if you nest c()’s:
c(1, c(2, c(3, 4)))
#> [1] 1 2 3 4
除了 typeof(x) 外,还有:
is.character(x)is.double(x)is.integer(x)is.logical(x)is.numeric(x): 虽然一般管 double 叫 numeric,但是is.numeric(x) == is.double(x) || is.integer(x)- or, more generally,
is.atomic(x).
1.3 Lists
Lists are sometimes called recursive vectors, because a list can contain other lists. This makes them fundamentally different from atomic vectors.
x <- list(list(list(list())))
str(x)
#> List of 1
#> $ :List of 1
#> ..$ :List of 1
#> .. ..$ : list()
is.recursive(x)
#> [1] TRUE
c() will combine several lists into one. If given a combination of atomic vectors and lists, c() will coerce the vectors to lists before combining them.
x <- list(list(1, 2), c(3, 4))
y <- c(list(1, 2), c(3, 4))
str(x)
#> List of 2
#> $ :List of 2
#> ..$ : num 1
#> ..$ : num 2
#> $ : num [1:2] 3 4
str(y)
#> List of 4
#> $ : num 1
#> $ : num 2
#> $ : num 3
#> $ : num 4
Lists are used to build up many of the more complicated data structures in R.
is.list(mtcars)
#> [1] TRUE
mod <- lm(mpg ~ wt, data = mtcars)
is.list(mod)
#> [1] TRUE
注意:如果要把 list 转成 vector,应该用 unlist(x) 而不是 as.vector(x);unlist(x) 会得到一个 named vector,如果不要 name 的话,可以用 unname(unlist(x))。
1.4 Attributes
All objects can have arbitrary additional attributes, used to store metadata about the object. Attributes can be thought of as a named list (with unique names).
The structure() function returns a new object with modified attributes:
structure(1:10, my_attribute = "This is a vector")
#> [1] 1 2 3 4 5 6 7 8 9 10
#> attr(,"my_attribute")
#> [1] "This is a vector"
Note that some attributes (namely “class”, “comment”, “dim”, “dimnames”, “names”, “row.names” and “tsp”) are treated specially and have restrictions on the values which can be set.
The attributes hidden by attributes(x) are the three most important:
- “names”, a character vector giving each element a name.
- “dim”, used to turn vectors into matrices and arrays.
- “class”, used to implement the S3 object system.
Each of these three attributes has a specific accessor function to get and set values. When working with these attributes, use names(x), dim(x), and class(x), NOT attr(x, "names"), attr(x, "dim"), and attr(x, "class").
1.5 Factors
Factors are built on top of integer vectors using two attributes:
class(f) == “factor”, which makes them behave differently from regular integer vectors andlevels(f), which defines the set of allowed values.
1.6 Matrices and arrays
Adding a dim(x) attribute to an atomic vector x allows it to behave like a multi-dimensional array. A special case of the array is the matrix, which has two dimensions.
length(x)generalizes tonrow(x)andncol(x)for matrices, anddim(x)for arrays.names(x)generalizes torownames(x)andcolnames(x)for matrices, anddimnames(x), a list of character vectors, for arrays.c()generalizes tocbind()andrbind()for matrices, and toabind()(provided by theabindpackage) for arrays.- You can transpose a matrix with
t(); the generalized equivalent for arrays isaperm().
1.7 Data frames
Under the hood, a data frame is a list of equal-length vectors. This makes it a 2-dimensional structure, so it shares properties of both the matrix and the list.
- This means that a data frame has
names(),colnames(), andrownames(), althoughnames()andcolnames()are the same thing. - The
length()of a data frame is the length of the underlying list and so is the same asncol(); nrow()gives the number of rows.
Because a data.frame is an S3 class, its type reflects the underlying vector used to build it: the list. To check if an object is a data frame, use class() or test explicitly with is.data.frame():
typeof(df)
#> [1] "list"
class(df)
#> [1] "data.frame"
is.data.frame(df)
#> [1] TRUE
You can coerce an object to a data frame with as.data.frame():
- A vector will create a one-column data frame.
- A list will create one column for each element; it’s an error if they’re not all the same length.
- A matrix will create a data frame with the same number of columns and rows as the matrix.
It’s a common mistake to try and create a data frame by cbind()ing vectors together. This doesn’t work because cbind() will create a matrix unless one of the arguments is already a data frame. Instead use data.frame() directly.
2. Subsetting
It’s easiest to learn how subsetting works for atomic vectors, and then how it generalises to higher dimensions and other more complicated objects.
2.1 Quiz
Q: What is the result of subsetting a vector with positive integers, negative integers, a logical vector, or a character vector?
- Positive integers select elements at specific positions, negative integers drop elements; logical vectors keep elements at positions corresponding to TRUE; character vectors select elements with matching names.
Q: What’s the difference between [, [[, and $ when applied to a list?
[selects sub-lists. It always returns a list; if you use it with a single positive integer, it returns a list of length one.[[selects an element within a list.$is a convenient shorthand:x$yis equivalent tox[["y"]].
Q: When should you use drop = FALSE?
- 简单说就是:如果
drop = FALSE,你 subset 的输入和输出会保持同一类型,比如你 subset 一个 matrix,得到的结果还是 matrix,不会变成 vector
Q: If x is a matrix, what does x[] <- 0 do? How is it different to x <- 0?
- If
xis a matrix,x[] <- 0will replace every element with 0, keeping the same number of rows and columns. x <- 0completely replaces the matrix with the value 0.
Q: How can you use a named vector to relabel categorical variables?
- A named character vector can act as a simple lookup table:
c(x = 1, y = 2, z = 3)[c("y", "z", "x")]
2.2 Subsetting operator []
2.2.1 Subsetting atomic vectors
There are six things that you can use to subset a vector:
x <- c(2.1, 4.2, 3.3, 5.4)
# CASE 1. Positive integers, which return elements at the specified positions
x[c(3, 1)]
x[order(x)]
x[c(1, 1)] # Duplicated indices yield duplicated values
x[c(2.1, 2.9)] # Real numbers are silently truncated to integers
# CASE 2. Negative integers, which omit elements at the specified positions
x[-c(3, 1)]
x[c(-1, 2)] # ERROR. You can’t mix positive and negative integers in a single subset
# CASE 3. Logical vectors, which select elements where the corresponding logical value is TRUE
x[c(TRUE, TRUE, FALSE, FALSE)]
x[x > 3]
x[c(TRUE, FALSE)] # If the logical vector is shorter than the vector being subsetted, it will be recycled to be the same length.
x[c(TRUE, TRUE, NA, FALSE)] # A missing value in the index always yields a missing value in the output
# CASE 4. Nothing, which returns the original vector
# More useful for matrices, data frames, and arrays
x[]
# CASE 5. Zero, which returns a zero-length vector
x[0]
# CASE 6. Character vectors, which return elements with matching names
# Only if the vector is named
y <- setNames(x, letters[1:4]) # letters[1:4] = c("a", "b", "c", "d")
y[c("d", "c", "a")]
y[c("a", "a", "a")] # Like integer indices, you can repeat indices
CASE 4, “Subsetting with nothing” can be useful in conjunction with assignment because it will preserve the original object class and structure. Compare the following two expressions:
mtcars[] <- lapply(mtcars, as.integer) # mtcars will remain as a data frame
mtcars <- lapply(mtcars, as.integer) # mtcars will become a list
2.2.2 Subsetting lists
Subsetting a list works in the same way as subsetting an atomic vector. Using [ will always return a list.
2.2.3 Subsetting matrices and arrays
You can subset higher-dimensional structures in three ways:
- With multiple vectors.
- 以 matrix 为例就是
m[rows, cols]- 如果省略了
rows就表示 all rows - 如果省略了
cols就表示 all cols - 逗号不能省,否则就变成了 subsetting with a single vector
- 如果省略了
- 比如
m[1:2, 3:4]就是要 1-2 row, 3-4 col 一共 4 个元素
- 以 matrix 为例就是
- With a single vector.
- 以 matrix 为例就是
m[indices] - indices 是 column-wise 算的,比如一个 5x5 的 matrix,
- index=3 表示
m[3,1] - index=15 表示
m[5,3] m[c(3, 15)]就是把上面这两个元素都选出来
- index=3 表示
- 以 matrix 为例就是
- With a matrix.
- 以 matrix 为例就是
m[indices] - indices 是一个 2-column 的 matrix,每一 row 表示一个下标
- 比如 $ \begin{bmatrix}1 & 1 \newline 3 & 1 \newline 4 & 2 \end{bmatrix} $ 就可以取到
m[1,1],m[3,1],m[4,2]这三个元素
- 比如 $ \begin{bmatrix}1 & 1 \newline 3 & 1 \newline 4 & 2 \end{bmatrix} $ 就可以取到
- 以 matrix 为例就是
如果是 array 的话,上面这三种方法都需要扩展维数。
2.2.4 Subsetting data frames
Data frames possess the characteristics of both lists and matrices:
- if you subset with a single vector, they behave like lists;
- 而 list 和 vector 的逻辑是一样的
- if you subset with two vectors, they behave like matrices.
df <- data.frame(x = 1:3, y = 3:1, z = letters[1:3])
df[df$x == 2, ] # x=2 的 row
df[c(1, 3), ] # 1st and 3rd rows
# select multiple columns
# 这两种方法是等价的,而且返回结果都是 data frame
df[c("x", "z")]
df[, c("x", "z")]
# select single column
# 情况稍微有点不同
df["x"] # return a data frame
df[, "x"] # return a vector
2.3 Subsetting operator [[]]
[[ is similar to [, except it can only return a single value and it allows you to pull pieces out of a list.
You need [[ when working with lists. This is because when [ is applied to a list it always returns a list: it never gives you the contents of the list. To get the contents, you need [[.
Because it can return only a single value, you must use [[ with either a single positive integer or a string:
a <- list(a = 1, b = 2)
a[[1]]
#> [1] 1
a[["a"]]
#> [1] 1
# If you do supply a vector it indexes recursively
b <- list(a = list(b = list(c = list(d = 1))))
b[[c("a", "b", "c", "d")]]
#> [1] 1
# Same as
b[["a"]][["b"]][["c"]][["d"]]
#> [1] 1
Because data frames are lists of columns, you can use [[ to extract a column from data frames: mtcars[[1]], mtcars[["cyl"]].
Simplifying vs. preserving subsetting
- Simplifying subsets returns the simplest possible data structure that can represent the output, and is useful interactively because it usually gives you what you want.
- Preserving subsetting keeps the structure of the output the same as the input, and is generally better for programming because the result will always be the same type.
- Omitting
drop = FALSEwhen subsetting matrices and data frames is one of the most common sources of programming errors.
- Omitting
Unfortunately, how you switch between simplifying and preserving differs for different data types:
| Simplifying | Preserving | |
|---|---|---|
| Vector | x[[1]] |
x[1] |
| List | x[[1]] |
x[1] |
| Factor | x[1:4, drop = T] |
x[1:4] |
| Array | x[1, ] or x[, 1] |
x[1, , drop = F] or x[, 1, drop = F] |
| Data frame | x[, 1] or x[[1]] |
x[, 1, drop = F] or x[1] |
How does it simplify?
# CASE: atomic vector
# Remove names.
x <- c(a = 1, b = 2)
x[1]
#> a
#> 1
x[[1]]
#> [1] 1
# CASE: list
# Return the object inside the list, not a single element list.
# 例子略
# CASE: factor
# Drops any unused levels.
z <- factor(c("a", "b"))
z[1]
#> [1] a
#> Levels: a b
z[1, drop = TRUE]
#> [1] a
#> Levels: a
# CASE: matrix or array
# If any of the dimensions has length 1, drops that dimension.
a <- matrix(1:4, nrow = 2)
a[1, , drop = FALSE]
#> [,1] [,2]
#> [1,] 1 3
a[1, ]
#> [1] 1 3
# CASE: data frame
# If output is a single column, returns a vector instead of a data frame.
df <- data.frame(a = 1:2, b = 1:2)
str(df[1])
#> 'data.frame': 2 obs. of 1 variable:
#> $ a: int 1 2
str(df[[1]])
#> int [1:2] 1 2
str(df[, "a", drop = FALSE])
#> 'data.frame': 2 obs. of 1 variable:
#> $ a: int 1 2
str(df[, "a"])
#> int [1:2] 1 2
Out-of-bound indices
[ and [[ differ slightly in their behaviour when the index is out of bounds (OOB)。我们干脆总结得远一些:
| Operator | Index | Atomic | List |
|---|---|---|---|
[ |
OOB | NA |
list(NULL) |
[ |
NA_real_ |
NA |
list(NULL) |
[ |
NULL |
x[0] |
list(NULL) |
[[ |
OOB | Error | Error |
[[ |
NA_real_ |
Error | NULL |
[[ |
NULL |
Error | Error |
2.4 Subsetting operator $
$ is a shorthand operator, where x$y is equivalent to x[["y", exact = FALSE]]. It’s often used to access variables in a data frame, as in mtcars$cyl or diamonds$carat.
There’s one important difference between $ and [[. $ does partial matching:
x <- list(abc = 1)
x$a
#> [1] 1
x[["a"]]
#> NULL
2.5 Subsetting S3 and S4 objects
- S3 objects
- S3 objects are made up of atomic vectors, arrays, and lists, so you can always pull apart an S3 object using the techniques described above and the knowledge you gain from
str().
- S3 objects are made up of atomic vectors, arrays, and lists, so you can always pull apart an S3 object using the techniques described above and the knowledge you gain from
- S4 objects
- There are also two additional subsetting operators that are needed for S4 objects:
@(equivalent to$), and@is more restrictive than$in that it will return an error if the slot does not exist.
slot()(equivalent to[[).
- There are also two additional subsetting operators that are needed for S4 objects:
S3 and S4 objects can override the standard behaviour of [ and [[ so they behave differently for different types of objects.
2.6 Subsetting and assignment
就两个小地方注意下:
- With lists, you can use subsetting + assignment + NULL to remove components from a list.
- data frame 是 list of vectors,所以可以赋 NULL 来 remove 某个 column
- To add a literal NULL to a list, use
[andlist(NULL).
x <- list(a = 1, b = 2)
x[["b"]] <- NULL
str(x)
#> List of 1
#> $ a: num 1
y <- list(a = 1)
y["b"] <- list(NULL)
str(y)
#> List of 2
#> $ a: num 1
#> $ b: NULL
2.7 Applications
Lookup tables (character subsetting)
讲真,lookup 做 noun 的时候表示的是 looking something up 这样一个动作,所以把一个 var 命名为 lookup 我是有点难理解的;用 lookupTable 会好一点,但是要注意逻辑是 looking something up in this lookupTable。
Say you want to convert abbreviations:
x <- c("m", "f", "u", "f", "f", "m", "m")
lut <- c(m = "Male", f = "Female", u = NA)
lut[x]
#> m f u f f m m
#> "Male" "Female" NA "Female" "Female" "Male" "Male"
unname(lut[x])
#> [1] "Male" "Female" NA "Female" "Female" "Male" "Male"
# Or with fewer output values
lut2 <- c(m = "Known", f = "Known", u = "Unknown")
unname(lut2[x])
#>
#> [1] "Known" "Known" "Unknown" "Known" "Known" "Known" "Known"
Random samples/bootstrap (integer subsetting)
df <- data.frame(x = rep(1:3, each = 2), y = 6:1, z = letters[1:6])
# Set seed for reproducibility
set.seed(10)
# Randomly reorder
df[sample(nrow(df)), ]
# Select 3 random rows
df[sample(nrow(df), 3), ]
# Select 6 bootstrap replicates
df[sample(nrow(df), 6, rep = T), ]
Expanding aggregated counts (integer subsetting)
df <- data.frame(x = c(2, 4, 1), y = c(9, 11, 6), n = c(3, 5, 1))
rep(1:nrow(df), df$n)
#> [1] 1 1 1 2 2 2 2 2 3
df[rep(1:nrow(df), df$n), ]
#> x y n
#> 1 2 9 3
#> 1.1 2 9 3
#> 1.2 2 9 3
#> 2 4 11 5
#> 2.1 4 11 5
#> 2.2 4 11 5
#> 2.3 4 11 5
#> 2.4 4 11 5
#> 3 1 6 1
这里 n 是表示 count,比如 (x, y, n) = (2, 9, 3) 就表示 (x, y) = (2, 9) 的数据有 3 个。我们用上面的语句把这个 count 展开。
3. Functions
3.1 Function components
All R functions have three parts:
body(f), the code inside the function.formals(f), the list of formal arguments which controls how you can call the function.environment(f), the “map” of the location of the function’s variables.
f <- function(x) x^2
f
#> function(x) x^2
formals(f)
#> $x
body(f)
#> x^2
environment(f)
#> <environment: R_GlobalEnv>
Exception: Primitive functions
There is one exception to the rule that functions have three components. Primitive functions, like sum(), call C code directly with .Primitive() interface and contain no R code. Therefore their formals(), body(), and environment() are all NULL:
sum
#> function (..., na.rm = FALSE) .Primitive("sum")
formals(sum)
#> NULL
body(sum)
#> NULL
environment(sum)
#> NULL
Primitive functions are only found in the base package, and since they operate at a low level, they can be more efficient (primitive replacement functions don’t have to make copies), and can have different rules for argument matching (e.g., switch and call). This, however, comes at a cost of behaving differently from all other functions in R. Hence the R core team generally avoids creating them unless there is no other option.
# 见名知意
is.function(f)
is.primitive(f)
3.2 Lexical scoping
Scoping is the set of rules that govern how R looks up the value of a symbol. 比如我们有 x <- 10,那么 scoping is the set of rules that leads R to go from the symbol x to its value 10.
R has two types of scoping: lexical scoping, implemented automatically at the language level, and dynamic scoping, used in select functions to save typing during interactive analysis. We discuss lexical scoping here because it is intimately tied to function creation.
The “lexical” in lexical scoping doesn’t correspond to the usual English definition (“of or relating to words or the vocabulary of a language as distinguished from its grammar and construction”) but comes from the computer science term “lexing”, which is part of the process that converts code represented as text to meaningful pieces that the programming language understands.
Lexical scoping looks up symbol values based on how functions were nested when they were created, NOT how they are nested when they are called. With lexical scoping, you don’t need to know how the function is called to figure out where the value of a variable will be looked up. You just need to look at the function’s definition.
There are four basic principles behind R’s implementation of lexical scoping:
- name masking
- functions vs. variables
- a fresh start
- dynamic lookup
3.2.1 Name Masking
注:老实说这一节我不明白为啥叫 Name Masking,因为好像并没有讲 masking 啊……根据 How does R handle overlapping object names? 的说法:
Masking occurs when two or more packages have objects (such as functions) with the same name.
这个和我理解得一样。Anyway,以下是正文。
When there is a name in a function, R will look for the name’s definition inside the current function, then where that function was defined (maybe an outer function), and so on, all the way up to the global environment, and then on to other loaded packages.
x <- 1
h <- function() {
y <- 2
i <- function() {
z <- 3
c(x, y, z)
}
i()
}
h() # output: [1] 1 2 3
The same rules apply to closures, functions created by other functions. The following function, j(), returns a function:
j <- function(x) {
y <- 2
function() {
c(x, y)
}
}
k <- j(1)
k() # output: [1] 1 2
This seems a little magical. How does R know what the value of y is after the function has been called? It works because k preserves the environment in which it was defined and because the environment includes the value of y. Environments gives some pointers on how you can dive in and figure out what values are stored in the environment associated with each function.
3.2.2 Functions vs. variables
The same principles apply regardless of the type of associated value — finding functions works exactly the same way as finding variables.
However, there is one small tweak to the rule. If you are using a name in a context where it’s obvious that you want a function (e.g., f(3)), R will ignore objects that are not functions while it is searching. In the following example n takes on a different value depending on whether R is looking for a function or a variable.
n <- function(x) x / 2 # this n is a function
o <- function() {
n <- 10 # and this n is a variable
n(n) # WTF!
}
o() # output: [1] 5
However, using the same name for functions and other objects will make for confusing code, and is generally best avoided.
3.2.3 A fresh start
# exists("a") returns true if variable `a` exists.
j <- function() {
if (!exists("a")) {
a <- 1
} else {
a <- a + 1
}
print(a)
}
j()
j() returns the same value, 1, every time. This is because every time a function is called, a new environment is created to host execution. A function has no way to tell what happened the last time it was run (除非我们用 <<-); each invocation is completely independent.
3.2.4 Dynamic lookup
Lexical scoping determines where to look for values, not when to look for them. R looks for values when the function is run, not when it’s created (但查找还是先到 definition 里去查). This means that the output of a function can be different depending on objects outside its environment:
f <- function() x
x <- 15
f()
#> [1] 15
x <- 20
f()
#> [1] 20
You generally want to avoid this behaviour because it means the function is no longer self-contained. This is a common error — if you make a spelling mistake in your code, you won’t get an error when you create the function, and you might not even get one when you run the function, depending on what variables are defined in the global environment.
One way to detect this problem is the findGlobals() function from codetools. This function lists all the external dependencies of a function:
f <- function() x + 1
codetools::findGlobals(f)
#> [1] "+" "x"
Another way to try and solve the problem would be to manually change the environment of the function to the emptyenv(), an environment which contains absolutely nothing:
environment(f) <- emptyenv()
f()
#> Error in f(): could not find function "+"
However this hardly works because R relies on lexical scoping to find everything, even the + operator. It’s never possible to make a function completely self-contained because you must always rely on functions defined in base R or other packages.
3.3 Every operation is a function call
Great, the C++ way.
This includes infix operators like +, control flow operators like for, if, and while, subsetting operators like [] and $, and even the curly brace {.
Note that `, the backtick, lets you refer to functions or variables that have otherwise reserved or illegal names:
x <- 10; y <- 5
x + y
#> [1] 15
`+`(x, y)
#> [1] 15
for (i in 1:2) print(i)
#> [1] 1
#> [1] 2
`for`(i, 1:2, print(i))
#> [1] 1
#> [1] 2
x[3]
#> [1] NA
`[`(x, 3)
#> [1] NA
It is possible to override the definitions of these special functions, but you need to be careful.
It’s more often useful to treat special functions as ordinary functions. For example, we could use sapply() to add 3 to every element of a list by first defining a function add(), like this:
add <- function(x, y) x + y
sapply(1:10, add, 3)
#> [1] 4 5 6 7 8 9 10 11 12 13
But we can also get the same effect using the built-in + function:
sapply(1:5, `+`, 3)
#> [1] 4 5 6 7 8
# This works because sapply can use match.fun() to find functions given their names.
sapply(1:5, "+", 3)
#> [1] 4 5 6 7 8
A more useful application is to combine lapply() or sapply() with subsetting:
x <- list(1:3, 4:9, 10:12)
sapply(x, "[", 2)
#> [1] 2 5 11
# equivalent to
sapply(x, function(x) x[2])
#> [1] 2 5 11
3.4 Function arguments
3.4.1 Calling functions
When calling a function you can specify arguments by position, by complete name, or by partial name. Arguments are matched
- first by exact name (perfect matching),
- then by prefix matching,
- and finally by position.
- then by prefix matching,
If a function uses ..., you can only specify arguments listed after ... with their full name.
3.4.2 Calling a function given a list of arguments
Suppose you had a list of function arguments. How could you then send that list to mean()? You need do.call():
args <- list(1:10, na.rm = TRUE)
do.call(mean, args)
#> [1] 5.5
# Equivalent to
mean(1:10, na.rm = TRUE)
#> [1] 5.5
注意这里 na.rm 是 args 的一个元素,并不是 args 的一个参数。
3.4.3 Default and missing arguments
You can determine if an argument was supplied or not with the missing() function.
i <- function(a, b) {
c(missing(a), missing(b))
}
i()
#> [1] TRUE TRUE
i(a = 1)
#> [1] FALSE TRUE
i(b = 2)
#> [1] TRUE FALSE
i(1, 2)
#> [1] FALSE FALSE
3.4.4 Lazy evaluation
By default, R function arguments are lazy — they’re only evaluated if they’re actually used:
f <- function(x) {
10
}
f(stop("This is an error!"))
#> [1] 10
stop() is not used, so not evaluated (thus not executed).
If you want to ensure that an argument is evaluated you can use force():
f <- function(x) {
force(x)
10
}
f(stop("This is an error!"))
#> Error in force(x): This is an error!
This code is exactly equivalent to:
f <- function(x) {
x
10
}
f(stop("This is an error!"))
This is important when creating closures with lapply() or a loop:
add <- function(x) {
function(y) x + y
}
adders <- lapply(1:10, add)
adders[[1]](10)
#> [1] 20
adders[[10]](10)
#> [1] 20
因为 x 在 add 内没有值,所以最终 adders[[1]] 到 adders[[10]] 这 10 个函数用的都是外部的 x 值,而外部 x 的值是最终定格在 10 的(1:10),所以你调用任意的 adders[[n]](10) 都是执行 10+10 而不是 n+10。
正确的写法是:
add <- function(x) {
force(x)
function(y) x + y
}
adders2 <- lapply(1:10, add)
adders2[[1]](10)
#> [1] 11
adders2[[10]](10)
#> [1] 20
Default arguments are evaluated inside the function:
f <- function(x = ls()) {
a <- 1
x
}
# ls() evaluated inside f:
f()
#> [1] "a" "x"
More technically, an unevaluated argument is called a promise, or (less commonly) a thunk ([θʌŋk], a delayed computation). A promise is made up of two parts:
- The expression which gives rise to the delayed computation. (It can be accessed with
substitute().) - The environment where the expression was created and where it should be evaluated.
The first time a promise is accessed, the expression is evaluated in the environment where it was created. This value is cached, so that subsequent access to the evaluated promise does not recompute the value (but the original expression is still associated with the value, so substitute() can continue to access it). You can find more information about a promise using pryr::promise_info(). This uses some C++ code to extract information about the promise without evaluating it, which is impossible to do in pure R code.
3.4.5 Variable argument list ...
- ellipsis: [ɪˈlɪpsɪs], 省略号
To capture ... in a form that is easier to work with, you can use list(...):
f <- function(...) {
names(list(...))
}
f(a = 1, b = 2)
#> [1] "a" "b"
It’s often better to be explicit rather than implicit, so you might instead ask users to supply a list of additional arguments. That’s certainly easier if you’re trying to use ... with multiple additional functions.
3.5 Special calls
R supports two additional syntaxes for calling special types of functions:
- infix and
- replacement functions.
3.5.1 Infix functions
Most functions in R are “prefix” operators: the name of the function comes before the arguments. You can also create infix functions where the function name comes in between its arguments, like + or -. All user-created infix functions must start and end with %. R comes with the following infix functions predefined: % %, %*%, %/%, %in%, %o%, %x%.
For example, we could create a new operator that pastes together strings:
`%+%` <- function(a, b) paste0(a, b)
"new" %+% " string"
#> [1] "new string"
3.5.2 Replacement functions
Replacement functions act like they modify their arguments in place, and have the special name xxx<-. They typically have two arguments (x and value), although they can have more, and they must return the modified object. For example, the following function allows you to modify the second element of a vector:
`second<-` <- function(x, value) {
x[2] <- value
x
}
x <- 1:10
second(x) <- 5L
x
#> [1] 1 5 3 4 5 6 7 8 9 10
I say they “act” like they modify their arguments in place, because they actually create a modified copy. We can see that by using pryr::address() to find the memory address of the underlying object.
library(pryr)
x <- 1:10
address(x) # 类似 C 的 &x
#> [1] "0x433fdf0"
second(x) <- 6L
address(x)
#> [1] "0x4305078"
Built-in functions that are implemented using .Primitive() will modify in place:
x <- 1:10
address(x)
#> [1] "0x103945110"
x[2] <- 7L
address(x)
#> [1] "0x103945110"
It’s important to be aware of this behaviour since it has important performance implications.
If you want to supply additional arguments, they go in between x and value:
`modify<-` <- function(x, position, value) {
x[position] <- value
x
}
modify(x, 1) <- 10
x
#> [1] 10 6 3 4 5 6 7 8 9 10
When you call modify(x, 1) <- 10, behind the scenes R turns it into x <- `modify<-`(x, 1, 10). This means you CANNOT do things like: modify(get("x"), 1) <- 10 because that gets turned into the invalid code: get("x") <- `modify<-`(get("x"), 1, 10).
3.6 Return values
The last expression evaluated in a function becomes the return value, or you can use an explicit return().
The functions that are the easiest to understand and reason about are pure functions: functions that always map the same input to the same output and have no other impact on the workspace. In other words, pure functions have no side effects: they don’t affect the state of the world in any way apart from the value they return.
R protects you from one type of side effect: most R objects have copy-on-modify semantics. So modifying a function argument does not change the original value. (也就是传说中的 pass-by-value)
Most base R functions are pure, with a few notable exceptions:
library()which loads a package, and hence modifies the search path.setwd(),Sys.setenv(),Sys.setlocale()which change the working directory, environment variables, and the locale, respectively.plot()and friends which produce graphical output.write(),write.csv(),saveRDS(), etc. which save output to disk.options()andpar()which modify global settings.- S4 related functions which modify global tables of classes and methods.
- Random number generators which produce different numbers each time you run them.
3.6.1 Invisible
Functions can return invisible values, which are not printed out by default when you call the function.
f1 <- function() 1
f2 <- function() invisible(1)
f1()
#> [1] 1
f2()
f1() == 1
#> [1] TRUE
f2() == 1
#> [1] TRUE
You can force an invisible value to be displayed by wrapping it in parentheses:
(f2())
#> [1] 1
The most common function that returns invisibly is <-:
a <- 2
(a <- 2)
#> [1] 2
3.6.2 On exit
As well as returning a value, functions can set up other triggers to occur when the function is finished using on.exit(). This is often used as a way to guarantee that changes to the global state are restored when the function exits. The code in on.exit() is run regardless of how the function exits, whether with an return, an error, or simply reaching the end of the function body.
in_dir <- function(dir, code) {
old <- setwd(dir)
on.exit(setwd(old))
force(code)
}
getwd()
#> [1] "/home/travis/build/hadley/adv-r"
in_dir("~", getwd())
#> [1] "/home/travis"
Caution: If you’re using multiple on.exit() calls within a function, make sure to set add = TRUE. Unfortunately, the default in on.exit() is add = FALSE, so that every time you run it, it overwrites existing exit expressions.
4. OO field guide
R has three object oriented systems, S3, S4, “Reference Classes” (S5), and a “Base Types” system.
- Base types, the internal C-level types that underlie the other OO systems. Base types are mostly manipulated using C code, but they’re important to know about because they provide the building blocks for the other OO systems.
- S3 implements a style of OO programming called generic-function OO. This is different from most programming languages, like Java, C++, and C#, which implement message-passing OO.
- With message-passing, objects usually appear before the name of the method/message: e.g.,
canvas.drawRect("blue"). - S3 is different. While computations are still carried out via methods, a special type of function called a generic function decides which method to call, e.g., drawRect(canvas, “blue”).
- S3 is a very casual system. It has no formal definition of classes.
- With message-passing, objects usually appear before the name of the method/message: e.g.,
- S4 works similarly to S3, but is more formal. There are two major differences to S3:
- S4 has formal class definitions, which describe the representation and inheritance for each class, and has special helper functions for defining generics and methods.
- S4 also has multiple dispatch, which means that generic functions can pick methods based on the class of any number of arguments, not just one.
- Reference classes, called RC for short, are quite different from S3 and S4. RC implements message-passing OO, so methods belong to classes, not functions. $ is used to separate objects and methods, so method calls look like
canvas$drawRect("blue"). RC objects are also mutable: they don’t use R’s usual copy-on-modify semantics, but are modified in place. This makes them harder to reason about, but allows them to solve problems that are difficult to solve with S3 or S4.
In the examples below, you’ll need install.packages("pryr"), to access useful functions for examining OO properties.
4.1 Quiz
Q: How do you tell what OO system (base, S3, S4, or RC) an object is associated with?
- If
!is.object(x), it’s a base object.- If
!isS4(x), it’s S3.- If
!is(x, "refClass"), it’s S4;- otherwise it’s RC.
- If
- If
Q: How do you determine the base type (like integer or list) of an object?
- Use
typeof()to determine the base class of an object.
Q: What is a generic function?
- A generic function calls specific methods depending on the class of it inputs. In S3 and S4 object systems, methods belong to generic functions, not classes like in other programming languages.
4.2 Base types
Underlying every R object is a C structure (or struct) that describes how that object is stored in memory. The struct includes the contents of the object, the information needed for memory management, and, most importantly for this section, a type. This is the base type of an R object. Base types are not really an object system because only the R core team can create new types. As a result, new base types are added very rarely.
Data structures section explains the most common base types (atomic vectors and lists), but base types also encompass functions, environments, and other more exotic objects likes names, calls, and promises.
You can determine an object’s base type with typeof(). Unfortunately the names of base types are not used consistently throughout R:
# The type of a function is "closure"
f <- function() {}
typeof(f)
#> [1] "closure"
is.function(f)
#> [1] TRUE
# The type of a primitive function is "builtin"
typeof(sum)
#> [1] "builtin"
is.primitive(sum)
#> [1] TRUE
Functions that behave differently for different base types are almost always written in C, where dispatch occurs using switch statements (e.g., switch(TYPEOF(x))).
4.3 S3
4.3.1 Recognising objects, generic functions, and methods
Most objects that you encounter are S3 objects. But unfortunately there’s no simple way to test if an object is an S3 object in base R. The closest you can come is is.object(x) & !isS4(x), i.e., it’s an object, but not S4. An easier way is to use pryr::otype():
library(pryr)
df <- data.frame(x = 1:10, y = letters[1:10])
otype(df) # A data frame is an S3 class
#> [1] "S3"
otype(df$x) # A numeric vector isn't
#> [1] "base"
otype(df$y) # A factor is
#> [1] "S3"
In S3, methods belong to functions, called generic functions, or generics for short. To determine if a function is an S3 generic, you can inspect its source code for a call to UseMethod(): that’s the function that figures out the correct method to call, the process of method dispatch. pryr also provides ftype() which describes the object system, if any, associated with a function:
mean
#> function (x, ...)
#> UseMethod("mean")
#> <bytecode: 0x2bc14a0>
#> <environment: namespace:base>
ftype(mean)
#> [1] "s3" "generic"
Some S3 generics, like [, sum(), and cbind(), don’t call UseMethod() because they are implemented in C. Instead, they call the C functions DispatchGroup() or DispatchOrEval(). Functions that do method dispatch in C code are called internal generics and are documented in ?"internal generic". ftype() knows about these special cases too.
Given a class, the job of an S3 generic is to call the right S3 method. You can recognise S3 methods by their names, which look like generic.class(). For example, the Date method for the mean() generic is called mean.Date(), and the factor method for print() is called print.factor().
This is the reason that most modern style guides discourage the use of . in function names: it makes them look like S3 methods.
ftype(t.data.frame) # data frame method for t()
#> [1] "s3" "method"
ftype(t.test) # generic function for t tests
#> [1] "s3" "generic"
You can see all the methods that belong to a generic with methods():
methods("mean")
#> [1] mean.Date mean.default mean.difftime mean.POSIXct mean.POSIXlt
methods("t.test")
#> [1] t.test.default* t.test.formula*
#>
#> Non-visible functions are asterisked
Apart from methods defined in the base package, most S3 methods will not be visible: use getS3method() to read their source code.
You can also list all generics that have a method for a given class:
methods(class = "ts")
#> [1] aggregate.ts as.data.frame.ts cbind.ts* cycle.ts*
#> [5] diffinv.ts* diff.ts* kernapply.ts* lines.ts*
#> [9] monthplot.ts* na.omit.ts* Ops.ts* plot.ts
#> [13] print.ts* time.ts* [<-.ts* [.ts*
#> [17] t.ts* window<-.ts* window.ts*
#>
#> Non-visible functions are asterisked
4.3.2 Defining classes and creating objects
S3 is a simple and ad hoc system; it has no formal definition of a class. To make an object an instance of a class, you just take an existing base object and set the class attribute. You can do that during creation with structure(), or after the fact with class<-():
# Create and assign class in one step
foo <- structure(list(), class = "foo")
# Create, then set class
foo <- list()
class(foo) <- "foo"
You can determine the class of any object using class(x), and see if an object inherits from a specific class using inherits(x, “classname”).
class(foo)
#> [1] "foo"
inherits(foo, "foo")
#> [1] TRUE
S3 objects are usually built on top of lists, or atomic vectors with attributes. You can also turn functions into S3 objects.
The class of an S3 object can be a vector, which describes behaviour from most to least specific. For example, the class of the glm() object is c("glm", "lm") indicating that generalised linear models inherit behaviour from linear models.
Most S3 classes provide a constructor function. This ensures that you’re creating the class with the correct components. Constructor functions usually have the same name as the class (like factor() and data.frame()).
foo <- function(x) {
if (!is.numeric(x)) stop("X must be numeric")
structure(list(x), class = "foo")
}
Apart from developer supplied constructor functions, S3 has no checks for correctness. This means you can change the class of existing objects. If you’ve used other OO languages, this might make you feel queasy ([ˈkwi:zi], having an unpleasantly nervous or doubtful feeling).
4.3.3 Creating new methods and generics
一般的模式是这样的:
f <- function(x) UseMethod("f") # dispatch on the function name "f"
objA <- structure(list(), class = "a") # we define an object, `objA`, of class `a`
f.a <- function(x) { # f.a 专门负责 class 为 `a` 的参数
# code goes here
}
f(objA) # dispatched to f.a(objA)
其中 f.a 是一个 method,然后 f 是一个 generic。
Adding a method to an existing generic works in the same way:
mean.a <- function(x) {
# code goes here
}
mean(objA) # dispatched to mean.a(objA)
A default class makes it possible to set up a fall back method for otherwise unknown classes:
f.default <- function(x) {
# code goes here
}
objB <- structure(list(), class = "b")
f(objB) # dispatched to f.default(objB) because we don't have `f.b(x)`
4.4 S4
S4 works in a similar way to S3, but it adds formality and rigour. Methods still belong to functions, not classes, but:
- Classes have formal definitions which describe their fields and inheritance structures (parent classes).
- Method dispatch can be based on multiple arguments to a generic function, not just one.
- There is a special operator,
@, for extracting slots (aka fields) from an S4 object.
All S4 related code is stored in the methods package. This package is always available when you’re running R interactively, but may not be available when running R in batch mode. For this reason, it’s a good idea to include an explicit library(methods) whenever you’re using S4.
4.4.1 Recognising objects, generic functions, and methods
You can identify an S4 object if:
str()describes it as a “formal” class,isS4()returns TRUE, orpryr::otype()returns “S4”.
4.4.2 Defining classes and creating objects
In S3, you can turn any object into an object of a particular class just by setting the class attribute. S4 is much stricter: you must define the representation of a class with setClass(), and create a new object with new(). You can find the documentation for a class with a special syntax: class?className, e.g., class?mle.
An S4 class has three key properties:
- A name: an alpha-numeric class identifier. By convention, S4 class names use
UpperCamelCase. - A named list of slots (fields), which defines slot names and permitted classes.
- For example, a person class might be represented by a character name and a numeric age:
list(name = "character", age = "numeric").
- For example, a person class might be represented by a character name and a numeric age:
- A string giving the class it inherits from, or, in S4 terminology, that it contains. You can provide multiple classes for multiple inheritance, but this is an advanced technique which adds much complexity.
S4 classes have other optional properties like a validity method that tests if an object is valid, and a prototype object that defines default slot values. See ?setClass for more details.
The following example creates a Person class with fields name and age, and an Employee class that inherits from Person. The Employee class inherits the slots and methods from the Person, and adds an additional slot, boss. To create objects we call new() with the name of the class, and name-value pairs of slot values.
setClass("Person",
slots = list(name = "character", age = "numeric"))
setClass("Employee",
slots = list(boss = "Person"),
contains = "Person")
alice <- new("Person", name = "Alice", age = 40)
john <- new("Employee", name = "John", age = 20, boss = alice)
Most S4 classes also come with a constructor function with the same name as the class: if that exists, use it instead of calling new() directly.
To access slots of an S4 object use @ or slot() (@ is equivalent to $, and slot() to [[.):
alice@age
#> [1] 40
slot(john, "boss")
#> An object of class "Person"
#> Slot "name":
#> [1] "Alice"
#>
#> Slot "age":
#> [1] 40
If an S4 object contains (inherits from) an S3 class or a base type, it will have a special .Data slot which contains the underlying base type or S3 object.
4.4.3 Creating new methods and generics
S4 provides special functions for creating new generics and methods. setGeneric() creates a new generic or converts an existing function into a generic. setMethod() takes the name of the generic, the classes the method should be associated with, and a function that implements the method:
setGeneric("union")
#> [1] "union"
setMethod("union",
c(x = "data.frame", y = "data.frame"),
function(x, y) {
unique(rbind(x, y))
}
)
#> [1] "union"
If you create a new generic from scratch, you need to supply a function that calls standardGeneric():
setGeneric("myGeneric", function(x) {
standardGeneric("myGeneric")
})
#> [1] "myGeneric"
standardGeneric() is the S4 equivalent to UseMethod().
4.5 RC
They are fundamentally different to S3 and S4 because:
- RC methods belong to objects, not functions
- RC objects are mutable: the usual R copy-on-modify semantics do not apply
These properties make RC objects behave more like objects do in most other programming languages, e.g., Python, Ruby, Java, and C#. Reference classes are implemented using R code: they are a special S4 class that wraps around an environment.
4.5.1 Defining classes and creating objects
Account <- setRefClass("Account",
fields = list(balance = "numeric"))
a <- Account$new(balance = 100)
a$balance
#> [1] 100
a$balance <- 200
a$balance
#> [1] 200
Note that RC objects are mutable, i.e., they have reference semantics, and are not copied-on-modify:
b <- a
b$balance
#> [1] 200
a$balance <- 0
b$balance
#> [1] 0
嗯,这真真是 reference。
For this reason, RC objects come with a copy() method that allow you to make a copy of the object:
c <- a$copy()
c$balance
#> [1] 0
a$balance <- 100
c$balance
#> [1] 0
RC methods are associated with a class and can modify its fields in place. In the following example, note that you access the value of fields with their name, and modify them with <<-:
Account <- setRefClass("Account",
fields = list(balance = "numeric"),
methods = list(
withdraw = function(x) {
balance <<- balance - x
},
deposit = function(x) {
balance <<- balance + x
}
)
)
The final important argument to setRefClass() is contains. This is the name of the parent RC class to inherit behaviour from. The following example creates a new type of bank account that returns an error preventing the balance from going below 0:
NoOverdraft <- setRefClass("NoOverdraft",
contains = "Account",
methods = list(
withdraw = function(x) {
if (balance < x) stop("Not enough money")
balance <<- balance - x
}
)
)
All reference classes eventually inherit from envRefClass. It provides useful methods like
copy(),callSuper()(to call the parent field),field()(to get the value of a field given its name),export()(equivalent toas()), andshow()(overridden to control printing).
See the inheritance section in setRefClass() for more details.
4.5.2 Recognising objects and methods
You can recognise RC objects if they are S4 objects (isS4(x)) that inherit from “refClass” (is(x, "refClass")). pryr::otype() will return “RC”. RC methods are also S4 objects, with class refMethodDef.
4.5.3 Method dispatch
When you call x$f(), R will look for a method f in the class of x, then in its parent, then its parent’s parent, and so on. From within a method, you can call the parent method directly with callSuper().
4.6 Picking a system
- In R you usually create fairly simple objects and methods for pre-existing generic functions like
print(),summary(), andplot(). S3 is well suited to this task, and the majority of OO code that I have written in R is S3. S3 is a little quirky, but it gets the job done with a minimum of code. - If you are creating more complicated systems of interrelated objects, S4 may be more appropriate. A good example is the
Matrixpackage by Douglas Bates and Martin Maechler. It is designed to efficiently store and compute with many different types of sparse matrices. S4 is also used extensively byBioconductorpackages, which need to model complicated interrelationships between biological objects (BTW,Bioconductorprovides many good resources for learning S4.). - If you’ve programmed in a mainstream OO language, RC will seem very natural. But because they can introduce side effects through mutable state.
5. Environments
- The environment is the data structure that powers scoping.
- Environments can also be useful data structures in their own right because they have reference semantics. When you modify a binding in an environment, the environment is not copied; it’s modified in place.
5.1 Quiz
Q: List at least three ways that an environment is different to a list.
- There are four ways: every object in an environment must have a name; order doesn’t matter; environments have parents; environments have reference semantics.
Q: What is the parent of the global environment? What is the only environment that doesn’t have a parent?
- The parent of the global environment is the last package that you loaded.
- The only environment that doesn’t have a parent is the empty environment.
Q: What is the enclosing environment of a function? Why is it important?
- The enclosing environment of a function is the environment where it was created. It determines where a function looks for variables.
Q: How are <- and <<- different?
<-always creates a binding in the current environment;<<-rebinds an existing name in a parent of the current environment.
5.2 Environment basics
The job of an environment is to associate, or bind, a set of names to a set of values. Each name points to an object stored elsewhere in memory:
e <- new.env()
e$a <- FALSE
e$b <- "a"
e$c <- 2.3
e$d <- 1:3
e$a <- e$d # a 和 d 同时指向同一组 1:3
e$a <- 1:3 # 此时 a 指向一组新的 1:3
If an object has no names pointing to it, it gets automatically deleted by the garbage collector.
Every environment has a parent, another environment. The parent is used to implement lexical scoping: if a name is not found in an environment, then R will look in its parent (and so on). Only one environment doesn’t have a parent: the empty environment.
More technically, an environment is made up of two components:
- the frame, which contains the name-object bindings, and
- the parent environment.
Unfortunately “frame” is used inconsistently in R. For example, parent.frame() doesn’t give you the parent frame of an environment. Instead, it gives you the calling environment.
There are four special environments:
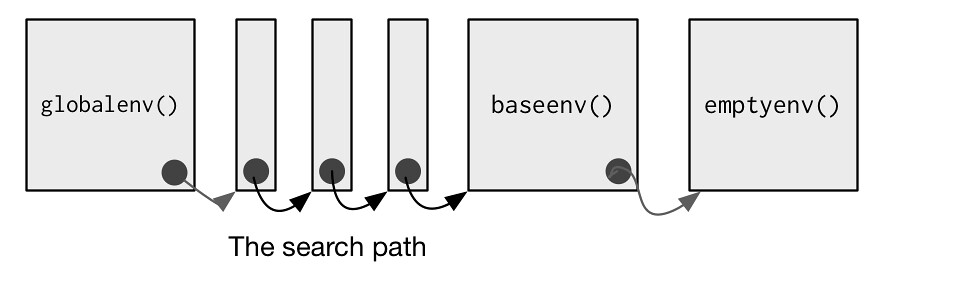
- The
globalenv(), or global environment, is the interactive workspace. This is the environment in which you normally work. The parent of the global environment is the last package that you attached withlibrary()orrequire(). - The
baseenv(), or base environment, is the environment of thebasepackage. Its parent is the empty environment. - The
emptyenv(), or empty environment, is the ultimate ancestor of all environments, and the only environment without a parent. - The
environment()is the current environment.
search() lists all parents of the global environment. This is called the search path because objects in these environments can be found from the top-level interactive workspace. It contains one environment for each attached package and any other objects that you’ve attach()ed. It also contains a special environment called Autoloads which is used to save memory by only loading package objects (like big datasets) when needed.
You can access any environment on the search list using as.environment().
search()
#> [1] ".GlobalEnv" "package:stats" "package:graphics"
#> [4] "package:grDevices" "package:utils" "package:datasets"
#> [7] "package:methods" "Autoloads" "package:base"
as.environment("package:stats")
#> <environment: package:stats>
globalenv(), baseenv(), the environments on the search path, and emptyenv() are connected as shown below. Each time you load a new package with library() it is inserted between the global environment and the package that was previously at the button of the search path.
To create an environment manually, use new.env():
e <- new.env()
# the default parent provided by new.env() is environment from
# which it is called - in this case that's the global environment.
parent.env(e)
#> <environment: R_GlobalEnv>
e$a <- 1
e$b <- 2
e$.a <- 2
ls(e)
#> [1] "a" "b"
ls(e, all.names = TRUE)
#> [1] "a" ".a" "b"
str(e)
#> <environment: 0x122f450>
ls.str(e)
#> a : num 1
#> b : num 2
ls.str(e, all.names = TRUE)
#> .a : num 2
#> a : num 1
#> b : num 2
e$c <- 3
e$c
#> [1] 3
e[["c"]]
#> [1] 3
get("c", envir = e) # get() uses the regular scoping rules and throws an error if the binding is not found
#> [1] 3
rm(".a", envir = e) # e$.a <- NULL 并不能 remove 掉 .a
x <- 10
exists("x", envir = e)
#> [1] TRUE
exists("x", envir = e, inherits = FALSE)
#> [1] FALSE
# To compare environments, you must use identical() not ==:
identical(globalenv(), environment())
#> [1] TRUE
globalenv() == environment()
#> Error in globalenv() == environment(): comparison (1) is possible only for atomic and list types
5.3 Recursing over environments
library(pryr)
x <- 5
where("x")
#> <environment: R_GlobalEnv>
where("mean")
#> <environment: base>
where 的实现大概是这样的:
where <- function(name, env = parent.frame()) {
if (identical(env, emptyenv())) {
# Base case
stop("Can't find ", name, call. = FALSE)
} else if (exists(name, envir = env, inherits = FALSE)) {
# Success case
env
} else {
# Recursive case
where(name, parent.env(env))
}
}
5.4 Function environments
- The enclosing environment is the environment where the function was created.
- Every function has one and only one enclosing environment.
- Binding a function to a name with
<-defines a binding environment. - Calling a function creates an ephemeral ([ɪˈfemərəl], lasting a very short time) execution environment that stores variables created during execution.
- Every execution environment is associated with a calling environment, which tells you where the function was called.
- For the 3 types of environment above, there may be 0, 1, or many environments associated with each function.
5.4.1 The enclosing environment
When a function is created, it gains a reference to the environment where it was made. This is the enclosing environment and is used for lexical scoping. You can determine the enclosing environment of a function by calling environment(f):
y <- 1
f <- function(x) x + y
environment(f)
#> <environment: R_GlobalEnv>
5.4.2 Binding environments
The name of a function is defined by a binding. The binding environments of a function are all the environments which have a binding to it.
e <- new.env()
e$g <- function() 1
- 所谓 binding 就是
foo <- bar这么一个赋值。binding environment 最简单的判断方法就是:变量(函数名)在哪个 environment,哪个 environment 就是 binding environment。比如上面的e$g <- function,g在e内部,所以 binding environment 就是e - 而
e$g的 enclosing environment 是 global,因为function的定义是写在当前 workspace 的。实在吃不准的时候别忘了可以用environment(e$g) - The enclosing environment belongs to the function, and never changes, even if the function is moved to a different environment.
- The enclosing environment determines how the function finds values;
- the binding environments determine how we find the function.
Namespaces are implemented using environments, taking advantage of the fact that functions don’t have to live in their enclosing environments. For example, take the base function sd(). It’s binding and enclosing environments are different:
environment(sd)
#> <environment: namespace:stats>
where("sd")
#> <environment: package:stats>
The definition of sd() uses var(), but if we make our own version of var() it doesn’t affect sd():
x <- 1:10
sd(x)
#> [1] 3.02765
var <- function(x, na.rm = TRUE) 100
sd(x)
#> [1] 3.02765
This works because every package has two environments associated with it: the package environment and the namespace environment.
- The package environment contains every publicly accessible function, and is placed on the search path.
- The namespace environment contains all functions (including internal functions), and its parent environment is a special imports environment that contains bindings to all the functions that the package needs.
- Every exported function in a package is bound into the package environment, but enclosed by the namespace environment.
When we type var into the console, it’s found first in the global environment. When sd() looks for var() it finds it first in its namespace environment so never looks in the globalenv().
5.4.3 Execution environments
Each time a function is called, a new environment is created to host execution. Once the function has completed, this environment is thrown away.
5.4.4 Calling environments
f2 <- function() {
x <- 5
function() {
innerX <- get("x", environment())
outerX <- get("x", parent.frame())
list(outerX = outerX, innerX = innerX, x = x)
}
}
g2 <- f2()
x <- 47
str(g2())
#> List of 3
#> $ outerX: num 47
#> $ innerX: num 5
#> $ x : num 5
identical(parent.env(environment(g2)), environment(f2))
#> [1] TRUE
Note that each execution environment has two parents: a calling environment and an enclosing environment. R’s regular scoping rules only use the enclosing parent; parent.frame() allows you to access the calling parent.
Looking up variables in the calling environment rather than in the enclosing environment is called dynamic scoping. Dynamic scoping is primarily useful for developing functions that aid interactive data analysis. It is one of the topics discussed in “non-standard evaluation”.
5.4.5 Summary
总结一下:
- Enclosing environment: 函数定义所在的 environment
- 获取方法:
- 在函数
f外部调用environment(f) - 在函数内部调用
parent.env(environment())
- 在函数
- The enclosing environment belongs to the function, and never changes.
- 获取方法:
- Binding environment:函数名所在的 environment
- 比如
e$g <- function() {},binding environment 就是e
- 比如
- Execution environment:函数执行创建的 envrionment
- 获取方法:函数内部调用
environment()(不带参数,表示 to get current environment) - Execution environment 有两个 parents:
- Enclosing environment
- Calling environment
- 如果在 Execution environment 里找不到 variable,scoping 规定会去 Enclosing environment 里去找,而不会去 Calling environment
- 获取方法:函数内部调用
- Calling environment:the environment from which a function is called
- 获取方法:函数内部调用
parent.frame()(不带参数)
- 获取方法:函数内部调用
实验:
f <- function() {
print(environment())
function() {
print(environment())
print(parent.frame())
print(parent.env(environment()))
}
}
g <- f()
#> <environment: 0x0000000008175e28> # SAME
g()
#> <environment: 0x0000000008181d68>
#> <environment: R_GlobalEnv>
#> <environment: 0x0000000008175e28> # SAME
5.5 Binding names to values
- The regular assignment arrow,
<-, always creates a variable in the current environment. - The deep assignment arrow,
<<-, never creates a variable in the current environment, but instead modifies an existing variable found by walking up the parent environments.- If
<<-doesn’t find an existing variable, it will create one in the global environment. - You can also do deep binding with
assign():name <<- valueis equivalent toassign("name", value, inherits = TRUE).
- If
There are two other special types of binding:
- A delayed binding creates and stores a promise to evaluate the expression when needed.
- We can create delayed bindings with the special assignment operator
%<d-%, provided by thepryrpackage. %<d-%is a wrapper around the basedelayedAssign()function.
- We can create delayed bindings with the special assignment operator
- An active binding does not bound to a constant object. Instead, they’re re-computed every time they’re accessed.
- We can create active bindings with the special assignment operator
%<a-%, provided by thepryrpackage. %<a-%is a wrapper for the base functionmakeActiveBinding().
- We can create active bindings with the special assignment operator
library(pryr)
x %<d-% (a + b)
a <- 10
b <- 100
x
#> [1] 110
set.seed(47)
x %<a-% runif(1)
x
#> [1] 0.976962
x
#> [1] 0.373916
5.6 Using environments explicitly
Environments are also useful data structures in their own right because they have reference semantics.
modify <- function(x) {
x$a <- 2
invisible()
}
# CASE 1: pass by value
x_l <- list()
x_l$a <- 1
modify(x_l)
x_l$a
#> [1] 1
# CASE 2: pass by reference
x_e <- new.env()
x_e$a <- 1
modify(x_e)
x_e$a
#> [1] 2
When creating your own environment, note that you should set its parent environment to be the empty environment. This ensures you don’t accidentally inherit objects from somewhere else:
x <- 1
e1 <- new.env()
get("x", envir = e1)
#> [1] 1
e2 <- new.env(parent = emptyenv())
get("x", envir = e2)
#> Error in get("x", envir = e2): object 'x' not found
Environments are data structures useful for solving three common problems:
- Avoiding copies of large data.
- Managing state within a package.
- Efficiently looking up values from names.
5.6.1 Avoiding copies
Since environments have reference semantics, you’ll never accidentally create a copy. This makes it a useful vessel for large objects. It’s a common technique for bioconductor packages which often have to manage large genomic objects. Changes to R 3.1.0 have made this use substantially less important because modifying a list no longer makes a deep copy. Previously, modifying a single element of a list would cause every element to be copied, an expensive operation if some elements are large. Now, modifying a list efficiently reuses existing vectors, saving much time.
5.6.2 Package state
Explicit environments are useful in packages because they allow you to maintain state across function calls. Normally, objects in a package are locked, so you can’t modify them directly. Instead, you can do something like this:
my_env <- new.env(parent = emptyenv())
my_env$a <- 1
get_a <- function() {
my_env$a
}
set_a <- function(value) {
old <- my_env$a
my_env$a <- value
invisible(old)
}
5.6.3 As a hashmap
A hashmap is a data structure that takes constant, O(1), time to find an object based on its name. Environments provide this behaviour by default, so can be used to simulate a hashmap.
6. Debugging, condition handling, and defensive programming
详细内容见 原地址。实际操作时再来看学得更快。另外还有
Conditions include:
- Errors raised by
stop() - Warnings raised by
warning() - Messages raised by
message()
Condition handling tools, like withCallingHandlers(), tryCatch(), and try() allow you to take specific actions when a condition occurs.
6.1 Condition handling
6.1.1 Ignore errors with a single try()
try() allows execution to continue even after an error has occurred. If you wrap the statement that creates the error in try(), the error message will be printed but execution will continue
f1 <- function(x) {
log(x)
10
}
f1("x")
#> Error in log(x): non-numeric argument to mathematical function
f2 <- function(x) {
try(log(x))
10
}
f2("a")
#> Error in log(x) : non-numeric argument to mathematical function
#> [1] 10
You can suppress the message with try(..., silent = TRUE).
To pass larger blocks of code to try(), wrap them in {}:
try({
a <- 1
b <- "x"
a + b
})
You can also capture the output of the try() function. If successful, it will be the last result evaluated in the block (just like a function). If unsuccessful it will be an (invisible) object of class try-error:
success <- try(1 + 2)
failure <- try("a" + "b")
class(success)
#> [1] "numeric"
class(failure)
#> [1] "try-error"
try() is particularly useful when you’re applying a function to multiple elements in a list. 这样把每个元素都过一遍,出错了也不要紧,最后的结果我们过滤掉 try-error 就好了:
elements <- list(1:10, c(-1, 10), c(T, F), letters)
results <- lapply(elements, log) # 不用 try 的话会中断执行
#> Warning in lapply(elements, log): NaNs produced
#> Error in FUN(X[[4L]], ...): non-numeric argument to mathematical function
results <- lapply(elements, function(x) try(log(x)))
#> Warning in log(x): NaNs produced
# filter 函数:return TRUE if x inherits from "try-error"
is.error <- function(x) inherits(x, "try-error")
succeeded <- !sapply(results, is.error)
# look at successful results
str(results[succeeded])
#> List of 3
#> $ : num [1:10] 0 0.693 1.099 1.386 1.609 ...
#> $ : num [1:2] NaN 2.3
#> $ : num [1:2] 0 -Inf
# look at inputs that failed
str(elements[!succeeded])
#> List of 1
#> $ : chr [1:26] "a" "b" "c" "d" ...
6.1.2 Handle conditions with tryCatch()
With tryCatch() you map conditions to handlers, named functions that are called with the condition as an input.
show_condition <- function(code) {
tryCatch(code,
error = function(c) print(c$message),
warning = function(c) print(c$message),
message = function(c) print(c$message)
)
}
show_condition(stop("Error-1"))
#> [1] "Error-1"
show_condition(warning("Warning-2"))
#> [1] "Warning-2"
show_condition(message("Message-3"))
#> [1] "Message-3\n"
# If no condition is captured, tryCatch returns the value of `code`
show_condition(10)
#> [1] 10
As well as returning default values when a condition is signalled, handlers can be used to make more informative error messages. For example, by modifying the message stored in the error condition object, the following function wraps read.csv() to add the file name to any errors:
read.csv2 <- function(file, ...) {
tryCatch(read.csv(file, ...), error = function(c) {
c$message <- paste0(c$message, " (in ", file, ")")
stop(c)
})
}
read.csv("code/dummy.csv")
#> Error in file(file, "rt"): cannot open the connection
read.csv2("code/dummy.csv")
#> Error in file(file, "rt"): cannot open the connection (in code/dummy.csv)
6.2 Defensive programming
A key principle of defensive programming is to “fail fast”: as soon as something wrong is discovered, signal an error. This is more work for the author of the function (you!), but it makes debugging easier for users because they get errors earlier rather than later, after unexpected input has passed through several functions.
In R, the “fail fast” principle is implemented in three ways:
- Be strict about what you accept.
- Avoid functions that use non-standard evaluation, like
subset,transform, andwith. - Avoid functions that return different types of output depending on their input.
- The two biggest offenders are
[andsapply(). - Whenever subsetting a data frame in a function, you should always use
drop = FALSE, otherwise you will accidentally convert 1-column data frames into vectors. - Similarly, never use
sapply()inside a function: always use the strictervapply()which will throw an error if the inputs are incorrect types and return the correct type of output even for zero-length inputs.
- The two biggest offenders are
There is a tension between interactive analysis and programming.
- When you’re working interactively, you want R to do what you mean. If it guesses wrong, you want to discover that right away so you can fix it.
- When you’re programming, you want functions that signal errors if anything is even slightly wrong or underspecified.
Keep this tension in mind when writing functions.
- If you’re writing functions to facilitate interactive data analysis, feel free to guess what the analyst wants and recover from minor misspecifications automatically.
- If you’re writing functions for programming, be strict. Never try to guess what the caller wants.
Part II. Functional programming
7. Functional programming
R, at its heart, is a functional programming (FP) language.
Then you’ll learn about the three building blocks of functional programming:
- anonymous functions,
- closures (functions written by functions), and
- lists of functions.
我们举一个 anonymous function + function vector 的例子:
x <- 1:10
# 基础版
summary <- function(x) {
c(mean(x, na.rm = TRUE),
median(x, na.rm = TRUE),
sd(x, na.rm = TRUE),
mad(x, na.rm = TRUE),
IQR(x, na.rm = TRUE))
}
# 高阶版
summary <- function(x) {
funs <- c(mean, median, sd, mad, IQR)
lapply(funs, function(f) f(x, na.rm = TRUE))
}
有点厉害。
7.1 Anonymous functions
In R, functions are objects in their own right. They aren’t automatically bound to a name. If you choose not to give the function a name, you get an anonymous function.
You can call an anonymous function without giving it a name, but the code is a little tricky to read:
# 定义了一个 function,body 是 "3()"
# 这里 "3" 被当做一个函数名,因为没有被调用,所以没有报错
# 一旦调用这个函数,就会报错,以为 "3" 不是一个合法的函数名
function(x) 3()
#> function(x) 3()
# With appropriate parenthesis, the function is called:
(function(x) 3)()
#> [1] 3
(function(x) x + 3)(10)
#> [1] 13
7.2 Closures
Closures are functions written by functions. Closures get their name because they enclose the environment of the parent function and can access all its variables. This is useful because it allows us to have two levels of parameters:
- a parent level that controls operation and
- a child level that does the work.
从上面这一段论述来看,好像被包的函数才叫 closure。
The following example uses this idea to generate a family of power functions in which a parent function (power()) creates two child functions (square() and cube()).
power <- function(exponent) {
function(x) {
x ^ exponent
}
}
square <- power(2)
square(2)
#> [1] 4
square(4)
#> [1] 16
cube <- power(3)
cube(2)
#> [1] 8
cube(4)
#> [1] 64
The difference between square() and cube() is their enclosing environments. One way to see the contents of the environment is to convert it to a list; Another way to see what’s going on is to use pryr::unenclose().
as.list(environment(square))
#> $exponent
#> [1] 2
as.list(environment(cube))
#> $exponent
#> [1] 3
library(pryr)
unenclose(square)
#> function (x)
#> {
#> x^2
#> }
unenclose(cube)
#> function (x)
#> {
#> x^3
#> }
The parent environment of a closure is the execution environment of the function that created it. The execution environment normally disappears after the function returns a value. However, when function outer returns function inner, function inner captures and stores the execution environment of function outer, and it doesn’t disappear.
- Primitive functions call C code directly and don’t have an associated environment.
我们也称 power() 这样生成 function 的 function 为 function factory。Function factories are most useful when:
- The different levels are more complex, with multiple arguments and complicated bodies.
- Some work only needs to be done once, when the function is generated.
7.3 Mutable state
Having variables at two levels allows you to maintain state across function invocations. This is possible because while the execution environment is refreshed every time, the enclosing environment is constant.
new_counter <- function() {
i <- 0
function() {
i <<- i + 1
i
}
}
counter_a <- new_counter()
counter_b <- new_counter()
counter_a()
#> [1] 1
counter_a()
#> [1] 2
counter_a()
#> [1] 3
counter_b()
#> [1] 1
counter_b()
#> [1] 2
counter_b()
#> [1] 3
是不是有点像 object 和 object member!
7.4 Lists of functions
起手式:
x <- 1:10
funs <- list(
sum = sum,
mean = mean,
median = median
)
lapply(funs, function(f) f(x))
#> $sum
#> [1] 55
#>
#> $mean
#> [1] 5.5
#>
#> $median
#> [1] 5.5
8. Functionals
The complement to a closure is a functional, a function that takes a function as an input.
8.1 My first functional: lapply()
- Input
xis a list.- Remember that data frames are also lists.
- Also returns a list.
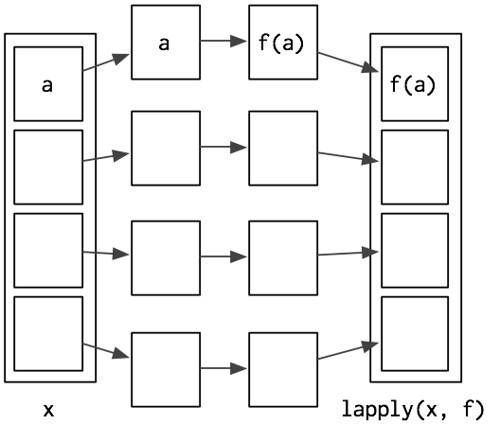
Looping patterns
It’s useful to remember that there are three basic ways to loop over a vector:
- loop over the elements:
for (x in xs)- Usually not a good choice if you generate output like
res <- c(); for (x in xs) { res <- c(res, sqrt(x)) }–it copiesresevery step.
- Usually not a good choice if you generate output like
- loop over the numeric indices:
for (i in seq_along(xs))- 比上面的情况好很多:
res <- numeric(length(xs)) for (i in seq_along(xs)) { res[i] <- sqrt(xs[i]) }
- 比上面的情况好很多:
- loop over the names:
for (nm in names(xs))
Just as there are three basic ways to use a for loop, there are three basic ways to use lapply():
- loop over the elements:
lapply(xs, function(x) {})lapply()takes care of saving the output for you.
- loop over the numeric indices:
lapply(seq_along(xs), function(i) {}) - loop over the names:
lapply(names(xs), function(nm) {})
Digress: parameter order
假定有 foo(x, y),如果不指定的话,lapply(ms, foo, n) 的参数顺序就是 foo(m[[i]], n),如果指定了 lapply(ms, foo, x=n),则参数顺序就是 foo(n, m[[i]]):
foo <- function(x, y) {
c(x, y)
}
ms <- 1:2
n <- 47
lapply(ms, foo, n)
[[1]]
[1] 1 47
[[2]]
[1] 2 47
lapply(ms, foo, x=n)
[[1]]
[1] 47 1
[[2]]
[1] 47 2
8.2 For loop functionals: friends of lapply()
8.2.1 Vector output: sapply and vapply
sapply() and vapply() are very similar to lapply() except they simplify their output to produce an atomic vector.
- While
sapply()guesses, vapply()takes an additional argumentFUN.VALUEspecifying the output type.
sapply(mtcars, is.numeric)
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
vapply(mtcars, is.numeric, logical(1))
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE TRUE
sapply(list(), is.numeric)
#> list()
vapply(list(), is.numeric, logical(1))
#> logical(0)
关于 vapply 这里说两句:
logical(1)指长度为 1 的 logical vector;我们的 TRUE、FALSE 其实都是logical(1)。这里FUN.VALUE = logical(1)的意思就是规定输出结果的每个元素都是logical(1)- 虽然
is.numeric本身就是返回 TRUE/FALSE 的,但是FUN.VALUE这个参数必须要指定 - 如果
FUN.VALUE指定为numeric(1),输出结果会把 TRUE 转成 1,FALSE 转为 0,相当于做了一个as.numeric(x)转换 character(1)是长度为 1 的 string vector,不要误解为是长度为 1 的 string:
df <- data.frame(x = 1:10, y = letters[1:10])
vapply(df, class, character(1))
#> x y
#> "integer" "factor"
sapply() is a thin wrapper around lapply() that transforms a list into a vector in the final step. vapply() is an implementation of lapply() that assigns results to a vector (or matrix) of appropriate type instead of as a list. The following code shows a pure R implementation of the essence of sapply() and vapply() (the real functions have better error handling and preserve names, among other things).
sapply2 <- function(x, f, ...) {
res <- lapply2(x, f, ...)
simplify2array(res)
}
vapply2 <- function(x, f, f.value, ...) {
out <- matrix(rep(f.value, length(x)), nrow = length(x))
for (i in seq_along(x)) {
res <- f(x[i], ...)
stopifnot(
length(res) == length(f.value),
typeof(res) == typeof(f.value)
)
out[i, ] <- res
}
out
}
8.2.2 Multiple inputs: Map (and mapply)
lapply(xs, foo) 是循环 foo(xs[[i]]),那么 Map(foo, xs, ys) 就是循环 foo(xs[[i]], ys[[i]])。It is equivalent to:
lapply(seq_along(xs), function(i) {
foo(xs[[i]], ws[[i]])
})
或者更严密一点:
stopifnot(length(xs) == length(ws))
out <- vector(mode="list", length=length(xs))
for (i in seq_along(xs)) {
out[[i]] <- weighted.mean(xs[[i]], ws[[i]])
}
- 注意
vector(mode="list")是创建了一个 list
Technically, Map() is equivalent to mapply() with simplify = FALSE, which is almost always what you want.
8.2.3 Rolling computations
What if you need a for-loop replacement that doesn’t exist in base R? You can often create your own wrapper. For example, you might be interested in smoothing your data using a rolling (or running) mean function:
rollmean <- function(x, n) {
out <- rep(NA, length(x))
offset <- trunc(n / 2)
for (i in (offset + 1):(length(x) - n + offset + 1)) {
out[i] <- mean(x[(i - offset):(i + offset - 1)])
}
out
}
x <- seq(1, 3, length = 1e2) + runif(1e2)
plot(x)
lines(rollmean(x, 5), col = "blue", lwd = 2)
lines(rollmean(x, 10), col = "red", lwd = 2)
But if the noise was more variable, you might worry that your rolling mean was too sensitive to outliers. Instead, you might want to compute a rolling median. 此时我们就可以重构一下,把 mean 和 median 作为参数传给我们自己的 apply 函数:
rollapply <- function(x, n, f, ...) {
out <- rep(NA, length(x))
offset <- trunc(n / 2)
for (i in (offset + 1):(length(x) - n + offset + 1)) {
out[i] <- f(x[(i - offset):(i + offset)], ...)
}
out
}
plot(x)
lines(rollapply(x, 5, median), col = "red", lwd = 2)
You might notice that the internal loop looks pretty similar to a vapply() loop, so we could rewrite the function as:
rollapply <- function(x, n, f, ...) {
offset <- trunc(n / 2)
locs <- (offset + 1):(length(x) - n + offset + 1)
num <- vapply(
locs,
function(i) f(x[(i - offset):(i + offset)], ...),
numeric(1)
)
c(rep(NA, offset), num)
}
This is effectively the same as the implementation in zoo::rollapply(), which provides many more features and much more error checking.
8.2.4 Parallelisation
- parallelisation: [pærəlelaɪ’zeɪʃən]
One interesting thing about the implementation of lapply() is that because each iteration is isolated from all others, the order in which they are computed doesn’t matter. 比如我们可以先计算 foo(xs[[2]]) 再计算 foo(xs[[1]])。
This has a very important consequence: since we can compute each element in any order, it’s easy to dispatch the tasks to different cores, and compute them in parallel. This is what parallel::mclapply() (and parallel::mcMap()) does. (These functions are not available in Windows, but you can use the similar parLapply() with a bit more work.)
如果并行的任务太简单,mclapply() may be slower than lapply(). This is because the cost of the individual computations is low, and additional work is needed to send the computation to the different cores and to collect the results.
If we take a more realistic example, generating bootstrap replicates of a linear model for example, the advantages are clearer:
boot_df <- function(x) x[sample(nrow(x), rep = T), ]
rsquared <- function(mod) summary(mod)$r.square
boot_lm <- function(i) {
rsquared(lm(mpg ~ wt + disp, data = boot_df(mtcars)))
}
system.time(lapply(1:500, boot_lm))
#> user system elapsed
#> 1.527 0.008 1.565
system.time(mclapply(1:500, boot_lm, mc.cores = 2))
#> user system elapsed
#> 0.706 0.065 0.774
8.3 Manipulating matrices and data frames
In this section, we’ll give a brief overview of the available options, hint at how they can help you, and point you in the right direction to learn more. We’ll cover three categories of data structure functionals:
apply(),sweep(), andouter()work with matrices.tapply()summarises a vector by groups defined by another vector.- the
plyrpackage, which generalisestapply()to make it easy to work with data frames, lists, or arrays as inputs, and data frames, lists, or arrays as outputs.
8.3.1 Matrix and array operations
You can think of apply() as an operation that summarises a matrix or array by collapsing each row or column to a single number. It has four arguments:
X, the matrix or array to summariseMARGIN, an integer vector giving the dimensions to summarise over, 1 = rows, 2 = columns, etc.FUN, a summary function...other arguments passed on toFUN
a <- matrix(1:20, nrow = 5)
a
#> [,1] [,2] [,3] [,4]
#> [1,] 1 6 11 16
#> [2,] 2 7 12 17
#> [3,] 3 8 13 18
#> [4,] 4 9 14 19
#> [5,] 5 10 15 20
apply(a, 1, mean)
#> [1] 8.5 9.5 10.5 11.5 12.5
apply(a, 2, mean)
#> [1] 3 8 13 18
There are a few caveats to using apply():
- It doesn’t have a simplify argument, so you can never be completely sure what type of output you’ll get. This means that
apply()is not safe to use inside a function unless you carefully check the inputs. apply()is also not idempotent in the sense that if the summary function is the identity operator, the output is not always the same as the input.- idempotent: [aɪ’dempətənt], 幂等的, describing an action which, when performed multiple times, has no further effect on its subject after the first time it is performed.
- You can put high-dimensional arrays back in the right order using
aperm(), or useplyr::aaply(), which is idempotent.
a <- matrix(1:20, nrow = 5) # 5x4 matrix
# identity(x) == x,它就是这么一个无聊的用途……
a1 <- apply(a, 1, identity) # 4x5 matrix. WTF!
a2 <- apply(a, 2, identity) # 5x4 matrix. same with a
sweep() allows you to “sweep” out the values of a summary statistic. It is often used with apply() to standardise arrays. The following example scales the rows of a matrix so that all values lie between 0 and 1:
x <- matrix(rnorm(20, 0, 10), nrow = 4)
# 每一 row 都减去自己 row 的 min,使得每一 row 的最小值都是 0
x1 <- sweep(x, 1, apply(x, 1, min), `-`)
# 每一 row 都除以自己 row 的 max,使得每一 row 的最大值都是 1
x2 <- sweep(x1, 1, apply(x1, 1, max), `/`)
The final matrix functional is outer(). It’s a little different in that it takes multiple vector inputs and creates a matrix or array output where the input function is run over every combination of the inputs:
outer(1:3, 1:10, "*")
#> [,1] [,2] [,3] [,4] [,5] [,6] [,7] [,8] [,9] [,10]
#> [1,] 1 2 3 4 5 6 7 8 9 10
#> [2,] 2 4 6 8 10 12 14 16 18 20
#> [3,] 3 6 9 12 15 18 21 24 27 30
8.3.2 Group apply
x <- 1:22
group <- rep(c("A", "B"), c(10, 12)) # 10 个 A,12 个 B
tapply(x, group, length)
#> A B
#> 10 12
tapply(x, group, mean)
#> A B
#> 5.5 16.5
这里 x 和 group 是两个 vector,实际情况更多的是 data.frame 的两个 column。
tapply() is just the combination of split() and sapply():
> split(x, group)
#> $A
#> [1] 1 2 3 4 5 6 7 8 9 10
#> $B
#> [1] 11 12 13 14 15 16 17 18 19 20 21 22
tapply2 <- function(x, group, f, ..., simplify = TRUE) {
pieces <- split(x, group)
sapply(pieces, f, simplify = simplify)
}
8.3.3 The plyr package
One challenge with using the base functionals is that they have grown organically over time, and have been written by multiple authors. This means that they are not very consistent:
- With
tapply()andsapply(), the simplify argument is calledsimplify. Withmapply(), it’s calledSIMPLIFY. Withapply(), the argument is absent. vapply()is a variant ofsapply()that allows you to describe what the output should be, but there are no corresponding variants fortapply(),apply(), orMap().- The first argument of most base functionals is a vector, but the first argument in
Map()is a function.
This makes learning these operators challenging, as you have to memorise all of the variations. Additionally, if you think about the possible combinations of input and output types, base R only covers a partial set of cases:
| input \ output | list | data frame | array |
|---|---|---|---|
| list | lapply() |
sapply() |
|
| data frame | by() |
||
| array | apply() |
This was one of the driving motivations behind the creation of the plyr package. It provides consistently named functions with consistently named arguments and covers all combinations of input and output data structures:
| input \ output | list | data frame | array |
|---|---|---|---|
| list | llply() |
ldply() |
laply() |
| data frame | dlply() |
ddply() |
daply() |
| array | alply() |
adply() |
aaply() |
Each of these functions splits up the input, applies a function to each piece, and then combines the results. Overall, this process is called “split-apply-combine”.
8.4 Manipulating lists
Another way of thinking about functionals is as a set of general tools for altering, subsetting, and collapsing lists. Every functional programming language has three tools for this: Map(), Reduce(), and Filter(). We’ve seen Map() already, and the following sections describe:
Reduce(), a powerful tool for extending two-argument functions, andFilter(), a member of an important class of functionals that work with predicates, functions that return a single TRUE or FALSE.- 没有一点点防备,就这样讲到了 MapReduce
8.4.1 Reduce()
Reduce() reduces a vector, x, to a single value by recursively calling a function, f, two arguments at a time. It combines the first two elements with f, then combines the result of that call with the third element, and so on. Calling Reduce(f, 1:3) is equivalent to f(f(1, 2), 3). Reduce is also known as fold, because it folds together adjacent elements in the list.
initis an optional initial valueright=FALSEindicates whether to from right to leftaccumulate = FALSEindicates whether the successive reduce combinations should be accumulated.- 比如
a <- 1:3; Reduce(`+`, a, accumulate=TRUE)返回一个 vector [1 3 6]
- 比如
Imagine you have a list of numeric vectors, and you want to find the values that occur in every element. Using reduce() make it easier:
set.seed(1130)
x <- replicate(5, sample(1:5, 7, replace = T), simplify = FALSE)
str(x)
#> List of 5
#> $ : int [1:7] 1 5 5 3 1 1 3
#> $ : int [1:7] 4 1 4 5 4 2 5
#> $ : int [1:7] 1 5 3 4 2 5 3
#> $ : int [1:7] 5 5 3 4 4 1 5
#> $ : int [1:7] 4 4 5 1 5 4 1
Reduce(intersect, x)
#> [1] 1 5
8.4.2 Predicate functionals
A predicate is a function that returns a single TRUE or FALSE, like is.character, all, or is.NULL. There are three useful predicate functionals in base R:
Filter()selects only those elements which match the predicate.Find()returns the first element which matches the predicate (or the last element ifright = TRUE).Position()returns the position of the first element that matches the predicate (or the last element ifright = TRUE).
Another useful predicate functional is where(), a custom functional that generates a logical vector from a list (or a data frame) and a predicate:
where <- function(f, x) {
vapply(x, f, logical(1))
}
The following example shows how you might use these functionals with a data frame:
# 注意 stringsAsFactors 没有关
df <- data.frame(x = 1:3, y = c("a", "b", "c"))
where(is.factor, df)
#> x y
#> FALSE TRUE
str(Filter(is.factor, df))
#> 'data.frame': 3 obs. of 1 variable:
#> $ y: Factor w/ 3 levels "a","b","c": 1 2 3
str(Find(is.factor, df))
#> Factor w/ 3 levels "a","b","c": 1 2 3
Position(is.factor, df)
#> [1] 2
8.5 Mathematical functionals
In this section we’ll use some of R’s built-in mathematical functionals. There are three functionals that work with functions to return single numeric values:
integrate(f, lower, upper)calculates the area under the curve defined byf(), within $ [lower, upper] $- i.e. 积分
uniroot(f, interval)returns $ x $ where $ x \in interval $ and $ f(x) = 0 $optimise(f, interval)finds the $ x $ of lowest (or highest) value of $ f(x) $
integrate(sin, 0, pi)
str(uniroot(sin, pi * c(1 / 2, 3 / 2)))
str(optimise(sin, c(0, 2 * pi)))
str(optimise(sin, c(0, pi), maximum = TRUE))
In statistics, optimisation is often used for maximum likelihood estimation (MLE). In MLE, we have two sets of parameters: the data, which is fixed for a given problem, and the parameters, which vary as we try to find the maximum. These two sets of parameters make the problem well suited for closures. Combining closures with optimisation gives rise to the following approach to solving MLE problems.
The following example shows how we might find the maximum likelihood estimate for $ \lambda $, if our data come from a Poisson distribution. First, we create a function factory that, given a dataset, returns a function that computes the negative log likelihood (NLL) for parameter lambda. In R, it’s common to work with the negative since optimise() defaults to finding the minimum.
poisson_nll <- function(x) {
n <- length(x)
sum_x <- sum(x)
function(lambda) {
n * lambda - sum_x * log(lambda) # + terms not involving lambda
}
}
Note how the closure allows us to precompute values that are constant with respect to the data.
We can use this function factory to generate specific NLL functions for input data. Then optimise() allows us to find the best values (the maximum likelihood estimates), given a generous starting range.
x1 <- c(41, 30, 31, 38, 29, 24, 30, 29, 31, 38)
x2 <- c(6, 4, 7, 3, 3, 7, 5, 2, 2, 7, 5, 4, 12, 6, 9)
nll1 <- poisson_nll(x1)
nll2 <- poisson_nll(x2)
lambdas <- c(0, 100)
optimise(nll1, lambdas)$minimum
#> [1] 32.09999
optimise(nll2, lambdas)$minimum
#> [1] 5.466681
Another important mathematical functional is optim(). It is a generalisation of optimise() that works with more than one dimension. If you’re interested in how it works, you might want to explore the Rvmmin package, which provides a pure-R implementation of optim(). Interestingly Rvmmin is no slower than optim(), even though it is written in R, not C. For this problem, the bottleneck lies not in controlling the optimisation but with having to evaluate the function multiple times.
8.6 Loops that should be left as is
Some loops have no natural functional equivalent. In this section you’ll learn about three common cases:
- modifying in place
- If you need to modify part of an existing data frame, it’s often better to use a for-loop.
- recursive relationships
- It’s hard to convert a for-loop into a functional when the relationship between elements is not independent, or is defined recursively.
- independent elements 的意思是 element 的计算顺序有要求,比如要先计算
xs[[i]]再计算xs[[i+1]]。Reduce()可能有用,但不一定能照顾到所有的情况
- while-loops
- 比如
while (TRUE) { break }这种,你就不好改写成 functional
- 比如
It’s possible to torture these problems to use a functional, but it’s not a good idea. You’ll create code that is harder to understand, eliminating the main reason for using functionals in the first case.
9. Function operators (FOs)
A function operator is a function that takes one (or more) functions as input and returns a function as output.
The chapter covers four important types of FO:
- Behaviour FOs change the behaviour of a function like automatically logging usage to disk or ensuring that a function is run only once.
- Output FOs manipulate the output of a function, like capturing errors, or fundamentally change what the function does.
- Input FOs modify the inputs to a function.
- Combining FOs provide function composition and logical operations.
其实这一节更像是 R 的 design pattern,但是与 procedural 与 object-oriented 的做法都不一样,请仔细体会
9.1 Behavioural FOs
Behavioural FOs leave the inputs and outputs of a function unchanged, but add some extra behaviour.
比如我们有一个 url 的 vector,要 download one by one,我们希望第 n 次下载开始后,间隔 1 秒再开始第 n+1 次,我们可以做这么一个 FO:
delay_by <- function(seconds, f) {
function(...) {
f(...)
Sys.sleep(seconds)
}
}
若是我们希望每下载 10 个 url 就在 console 打一个 . 来表示 progress,可以做这么一个 FO:
dot_every <- function(n, f) {
i <- 1
function(...) {
if (i %% n == 0) cat(".")
i <<- i + 1
f(...)
}
}
Notice that I’ve made the function the last argument in each FO. This makes it easier to read when we compose multiple function operators:
# Good practice
download <- dot_every(10, delay_by(1, download_file))
# Bad practice
download <- dot_every(delay_by(download_file, 1), 10)
9.1.1 Memoization
- memoize: memo + -ize, 发音这这么发
- memoization: (computer science) A technique in which partial results are recorded (forming a memo) and then can be re-used later without having to recompute them.
Another thing you might worry about when downloading multiple files is accidentally downloading the same file multiple times. You could avoid this by calling unique() on the list of input URLs, or manually managing a data structure that mapped the URL to the result. An alternative approach is to use memoization: modify a function to automatically cache its results.
你可以这样理解 memoized function:它维护了一个 Map<Input, Output>,对每一个 input,它先检查下有没有 output,有的话就直接返回,没有就按正常业务走,然后把这对 <input, output> 存到 Map 里。
A realistic use of memoisation is computing the Fibonacci series:
library(memoise)
fib <- function(n) {
if (n < 2) return(1)
fib(n - 2) + fib(n - 1)
}
system.time(fib(23))
#> user system elapsed
#> 0.126 0.011 0.137
system.time(fib(24))
#> user system elapsed
#> 0.205 0.000 0.205
fib2 <- memoise(function(n) {
if (n < 2) return(1)
fib2(n - 2) + fib2(n - 1)
})
system.time(fib2(23))
#> user system elapsed
#> 0.005 0.000 0.004
system.time(fib2(24))
#> user system elapsed
#> 0 0 0
It doesn’t make sense to memoise all functions. For example, a memoised random number generator is no longer random.
9.1.2 Capturing function invocations
这里的情形其实和我们 debug 时在函数前后打 log 的做法是一样的:
ignore <- function(...) NULL
tee <- function(f, on_input = ignore, on_output = ignore) {
function(...) {
on_input(...)
output <- f(...)
on_output(output)
output
}
}
(The function is inspired by the unix shell command tee, which is used to split up streams of file operations so that you can both display what’s happening and save intermediate results to a file.)
We can use tee() to look inside the uniroot() functional, and see how it iterates its way to a solution:
g <- function(x) cos(x) - x
show <- function(x, ...) cat(sprintf("%+.08f", x), "\n")
# The x it tries step by step
zeros <- uniroot(tee(g, on_input = show), c(-5, 5))
#> -5.00000000
#> +5.00000000
#> +0.28366219
#> +0.87520341
#> +0.72298040
#> +0.73863091
#> +0.73908529
#> +0.73902425
#> +0.73908529
# The g(x) value it gets per step
zeros <- uniroot(tee(g, on_output = show), c(-5, 5))
#> +5.28366219
#> -4.71633781
#> +0.67637474
#> -0.23436269
#> +0.02685676
#> +0.00076012
#> -0.00000026
#> +0.00010189
#> -0.00000026
我们其实还可以再套一个 closure 把每一对 <x, g(x)> 都记录下来,然后再画个图啥的,具体就不展开了。
9.1.3 Laziness
The function operators we’ve seen so far follow a common pattern:
funop <- function(f, otherargs) {
function(...) {
# maybe do something
res <- f(...)
# maybe do something else
res
}
}
Unfortunately there’s a problem with this implementation because function arguments are lazily evaluated: f() may have changed between applying the FO and evaluating the function. This is a particular problem if you’re using a for loop or lapply() to apply multiple function operators. In the following example, we take a list of functions and delay each one. But when we try to evaluate the mean, we get the sum instead:
funs <- list(mean = mean, sum = sum)
funs_m <- lapply(funs, delay_by, seconds = 0.1)
funs_m$mean(1:10)
#> [1] 55
We can avoid that problem by explicitly forcing the evaluation of f():
delay_by <- function(seconds, f) {
force(f) # the skeleton key
function(...) {
Sys.sleep(seconds)
f(...)
}
}
It’s good practice to do that whenever you create a new FO.
9.2 Output FOs
9.2.1 Minor modifications
base::Negate(f)takes a function that returns a logical vector (i.e. a predicate function), and returns the negation of that function.- negate: [nɪˈgeɪt], (grammar) to make (a word or phrase) negative
- 比如
Negate(is.null)返回一个相当于!is.null()的 function,我们可以就可以测试参数是否为 “非 NULL”:(Negate(is.null))(x)
plyr::failwith(defaultResult, f)turns a function that throws an error into a function that returns a default value when there’s an error.- 不用自己写 try 或是 tryCatch 了
9.2.2 Changing what a function does
举两个例子:
# EG 1: Return text that the function printed
capture_it <- function(f) {
force(f)
function(...) {
capture.output(f(...))
}
}
str_out <- capture_it(str)
str(1:10)
#> int [1:10] 1 2 3 4 5 6 7 8 9 10
str_out(1:10)
#> [1] " int [1:10] 1 2 3 4 5 6 7 8 9 10"
# EG 2: Return how long a function took to run
time_it <- function(f) {
force(f)
function(...) {
system.time(f(...))
}
}
9.3 Input FOs
9.3.1 Prefilling function arguments: partial function application
比如我们有一个函数有 n 个参数,但是实际应用的时候,有 m 个参数的值都是固定的。为了不用每次都写那么长一串参数,我们很容易想到写一个只有 (n-m) 个函数来把这个函数包起来。我们称这种做法为 partial function application,而 pryr::partial() 给我们提供了一种简写的方式:
# 一般的写法:
f <- function(a) g(a, b = 1) # 绑定 b=1
compact <- function(x) Filter(Negate(is.null), x) # 绑定第一个参数为 Negate(is.null)
Map(function(x, y) f(x, y, zs), xs, ys) # 绑定第三个参数为 zs
# 用 partial() 的写法:
f <- partial(g, b = 1)
compact <- partial(Filter, Negate(is.null))
Map(partial(f, zs = zs), xs, ys)
NB: Using partial function application is a straightforward task in many functional programming languages, but it’s not entirely clear how it should interact with R’s lazy evaluation rules.
9.3.2 Changing input types
base::Vectorize() creates a function wrapper that vectorizes the action of its argument FUN. 有点不好解释,看下面的例子:
sample2 <- Vectorize(sample, "size", SIMPLIFY = FALSE)
str(sample2(1:5, c(1, 1, 3))) # size=1, size=1 and size=3
#> List of 3
#> $ : int 3
#> $ : int 4
#> $ : int [1:3] 5 4 3
SIMPLIFY = FALSEensures that our newly vectorised function always returns a list. This is usually what you want.
splat() converts a function that takes multiple arguments to a function that takes a single list of arguments. This is useful when you want to run a function with different argument composition.
splat <- function (f) {
force(f)
function(args) {
do.call(f, args)
}
}
x <- c(NA, runif(100), 1000)
args <- list(
list(x), # 第一套参数
list(x, na.rm = TRUE), # 第二套参数
list(x, na.rm = TRUE, trim = 0.1) # 第三套参数
)
lapply(args, splat(mean))
#> [[1]]
#> [1] NA
#> [[2]]
#> [1] 10.4192
#> [[3]]
#> [1] 0.5280969
plyr::colwise(f)(df) apply function f column-wise to df:
median(mtcars)
#> Error in median.default(mtcars): need numeric data
median(mtcars$mpg)
#> [1] 19.2
plyr::colwise(median)(mtcars)
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> 1 19.2 6 196.3 123 3.695 3.325 17.71 0 0 4 2
9.4. Combining FOs
9.4.1 Aggregating multiple functions into a single function
summaries <- plyr::each(mean, sd, median)
summaries(1:10)
#> mean sd median
#> 5.50000 3.02765 5.50000
9.4.2 Function composition
这里说的 composition 指 f(g(x)) 这种形式,我们可以用 pryr::compose(f, g) 来实现:
sapply(mtcars, compose(length, unique))
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> 25 3 27 22 22 29 30 2 2 3 6
# 等价于 sapply(mtcars, function(x) length(unique(x)))
Mathematically, function composition is often denoted with the infix operator, o, like (f o g)(x). In R, we can create our own infix composition function:
"%o%" <- compose
sapply(mtcars, length %o% unique)
#> mpg cyl disp hp drat wt qsec vs am gear carb
#> 25 3 27 22 22 29 30 2 2 3 6
sqrt(1 + 8)
#> [1] 3
compose(sqrt, `+`)(1, 8)
#> [1] 3
(sqrt %o% `+`)(1, 8)
#> [1] 3
Compose also allows for a very succinct implementation of Negate, which is just a partially evaluated version of compose():
Negate <- partial(compose, `!`)
We could implement the population standard deviation with function composition:
square <- function(x) x^2
deviation <- function(x) x - mean(x)
sd2 <- sqrt %o% mean %o% square %o% deviation
sd2(1:10)
#> [1] 2.872281
This type of programming is called tacit or point-free programming. (The term point-free comes from the use of “point” to refer to values in topology; this style is also derogatorily known as pointless). In this style of programming, you don’t explicitly refer to variables. Instead, you focus on the high-level composition of functions rather than the low-level flow of data. The focus is on what’s being done, not on objects it’s being done to. Since we’re using only functions and not parameters, we use verbs and not nouns. This style is common in Haskell, and is the typical style in stack based programming languages like Forth and Factor. It’s not a terribly natural or elegant style in R, but it is fun to play with.
综合 compose() 和 partial() 我们可以改写本章开头的那个例子:
download <- dot_every(10, memoise(delay_by(1, download_file)))
# 新写法
download <- pryr::compose(
partial(dot_every, 10),
memoise,
partial(delay_by, 1),
download_file
)
9.4.3 Logical predicates and boolean algebra
举几个例子:
and <- function(f1, f2) {
force(f1); force(f2)
function(...) {
f1(...) && f2(...)
}
}
or <- function(f1, f2) {
force(f1); force(f2)
function(...) {
f1(...) || f2(...)
}
}
not <- function(f) {
force(f)
function(...) {
!f(...)
}
}
This would allow us to write:
Filter(or(is.character, is.factor), iris)
Filter(not(is.numeric), iris)
是不是方便多了~
Part III. Metaprogramming
10. Non-standard evaluation
10.1 Capturing expressions
Instead of using the value, substitute(x) or quote(x) returns the code of its parameter (i.e. the expression):
f <- function(x) {
substitute(x)
}
f(1:10)
#> 1:10
x <- 10
f(x)
#> x
y <- 13
f(x + y^2)
#> x + y^2
上面这个例子中,substitute() 是在函数内部使用的,而且是直接作用于函数的参数,这个使用场景需要注意,因为不同的使用场景对 substitute() 的结果会有影响。
substitute() 和 quote() 的区别在于:
quote(x)直接返回 expressionx,没有任何附加的处理substitute(x, env)returns the parse tree for expressionx(目前可以简单理解为就是 expression), substituting any variables bound inenv.envdefaults to the current evaluation environment.- Substitution takes place by examining each component of the parse tree as follows:
- CASE 1: If it is not a bound symbol in
env, it is unchanged. - CASE 2: 如果不是 CASE 1 的话,it is an ordinary variable in
env, and its value will be substituted, unlessenvis.GlobalEnvin which case the symbol is left unchanged. - CASE 3: If it is a promise object, i.e., a formal argument to a function or explicitly created using
delayedAssign(), the expression slot of the promise replaces the symbol.- Function arguments are represented by a special type of object called a promise, which contain three slots:
- a value (lazy evaluated),
- an expression, and
- an environment.
- 上面的例子就是这种情况。
- You’re not normally aware of promises because the first time you access a promise its code is evaluated in its environment, yielding a value.
- Function arguments are represented by a special type of object called a promise, which contain three slots:
- CASE 1: If it is not a bound symbol in
我们举个 CASE 1 和 CASE 2 的例子:
e <- new.env()
e$a <- 5
substitute(a+b, e)
#> 5 + b
quote(a+b)
#> a + b
quote(e$a+e$b)
#> e$a + e$b
substitute() and quote() are often paired with deparse(). That function takes an expression, and turns it into a character vector:
g <- function(x) deparse(substitute(x))
g(1:10)
#> [1] "1:10"
g(x)
#> [1] "x"
g(x + y^2)
#> [1] "x + y^2"
这样 plot(x, y) 才能知道在 x-axis 上写 “x”、在 y-axis 上写 “y” (如果是 data.frame 的话可以用 names(df))。
There are a lot of functions in Base R that use these ideas. Some use them to avoid quotes:
library(ggplot2)
# the same as
library("ggplot2")
10.2 Non-standard evaluation in subset
sample_df <- data.frame(a = 1:5, b = 5:1, c = c(5, 3, 1, 4, 1))
subset(sample_df, a >= 4)
# equivalent to:
sample_df[sample_df$a >= 4, ]
subset(sample_df, b == c)
# equivalent to:
sample_df[sample_df$b == sample_df$c, ]
subset() is special because it implements different scoping rules: the expressions a >= 4 or b == c are evaluated in the specified data frame rather than in the current or global environments. This is the essence of non-standard evaluation.
How does subset() work? We’ve already seen how to capture an argument’s expression rather than its result, so we just need to figure out how to evaluate that expression in the right context. Specifically, we want x to be interpreted as sample_df$x, not globalenv()$x. To do this, we need eval(). This function takes an expression and evaluates it in the specified environment:
eval(quote(x <- 1))
eval(quote(x))
#> [1] 1
eval(quote(y))
#> Error in eval(expr, envir, enclos): object 'y' not found
e <- new.env()
e$x <- 20
eval(quote(x), e) # evaluate in envrionment e
#> [1] 20
Because lists and data frames bind names to values in a similar way to environments, eval()’s second argument need not be limited to an environment: it can also be a list or a data frame:
eval(quote(x), list(x = 30))
#> [1] 30
eval(quote(x), data.frame(x = 40))
#> [1] 40
This gives us one part of subset():
eval(quote(a >= 4), sample_df)
#> [1] FALSE FALSE FALSE TRUE TRUE
eval(quote(b == c), sample_df)
#> [1] TRUE FALSE FALSE FALSE TRUE
A common mistake when using eval() is to forget to quote the first argument. Compare the results below:
a <- 10
eval(quote(a), sample_df)
#> [1] 1 2 3 4 5
eval(a, sample_df)
#> [1] 10
Now we can use eval() and substitute() to write subset():
# Caution: Scoping issue
subset2 <- function(x, condition) {
condition_call <- substitute(condition)
r <- eval(condition_call, x)
x[r, ]
}
subset2(sample_df, a >= 4)
#> a b c
#> 4 4 2 4
#> 5 5 1 1
10.3 Scoping issues
There is something wrong with the previous implementation:
x <- 4
y <- 4
subset2(sample_df, a == 4) # OK
#> a b c
#> 4 4 2 4
subset2(sample_df, a == y) # OK
#> a b c
#> 4 4 2 4
subset2(sample_df, a == x) # WTF!
#> a b c
#> 1 1 5 5
#> 2 2 4 3
#> 3 3 3 1
#> 4 4 2 4
#> 5 5 1 1
#> NA NA NA NA
#> NA.1 NA NA NA
What went wrong? In the previous implementation, if eval() can’t find the variable inside the data frame (its second argument), it looks first in the environment of subset2(). That’s obviously not what we want, so we need some way to tell eval() where to look if it can’t find the variables in the data frame.
The key is the third argument to eval(): enclos. This allows us to specify a parent (or enclosing) environment for objects that don’t have one (like lists and data frames). If the binding is not found in env, eval() will next look in enclos, and then in the parents of enclos. enclos is ignored if env is a real environment. We want to look for x in the environment from which subset2() was called. In R terminology this is called the parent frame and is accessed with parent.frame(). This is an example of dynamic scoping: the values come from the location where the function was called, not where it was defined:
subset2 <- function(x, condition) {
condition_call <- substitute(condition)
r <- eval(condition_call, x, parent.frame())
x[r, ]
}
x <- 4
subset2(sample_df, a == x)
#> a b c
#> 4 4 2 4
We can get the same behaviour by using list2env(). It turns a list into an environment with an explicit parent:
subset2a <- function(x, condition) {
condition_call <- substitute(condition)
env <- list2env(x, parent = parent.frame())
r <- eval(condition_call, env)
x[r, ]
}
10.4 Calling from another function
这一段的论述其实我没有看懂。它主要说的问题就是外部函数把 expression 作为参数传到其调用的内部函数(比如上面的 subset2())时会出现一个有点微妙的错误,比如:
subset2 <- function(x, condition) {
condition_call <- substitute(condition)
r <- eval(condition_call, x, parent.frame())
x[r, ]
}
scramble <- function(x) x[sample(nrow(x)), ]
subscramble <- function(x, condition) {
scramble(subset2(x, condition))
}
subscramble(sample_df, a >= 4)
# Error in eval(expr, envir, enclos) : object 'a' not found
修正的方案是把 condition 放在外部函数 subscramble() 里转成 expression,然后 subset2 里不做 substitute() 或是 quote(),直接 eval():
subset2_q <- function(x, condition) {
r <- eval(condition, x, parent.frame())
x[r, ]
}
subscramble <- function(x, condition) {
condition <- substitute(condition)
scramble(subset2_q(x, condition))
}
subscramble(sample_df, a >= 3)
#> a b c
#> 4 4 2 4
#> 5 5 1 1
#> 3 3 3 1
出错的原因我觉得在于:在 subscramble() 内部,condition 已经被 evaluate 了一次,此时 a >= 3 这样的式子在 subscramble() 的 environment(以及其 parent)中必定是找不到 object a 的,所以这个已经被 evaluate 的结果,再传给 eval(),报的错误还是说找不到 object a。
除此之外,本节 debug 的手法值得学习一下:
# Debugging Example 1
subscramble(sample_df, a >= 4)
# Error in eval(expr, envir, enclos) : object 'a' not found
traceback()
#> 5: eval(expr, envir, enclos)
#> 4: eval(condition_call, x, parent.frame()) at #3
#> 3: subset2(x, condition) at #1
#> 2: scramble(subset2(x, condition)) at #2
#> 1: subscramble(sample_df, a >= 4)
# Debugging Example 2
debugonce(subset2)
subscramble(sample_df, a >= 4)
#> debugging in: subset2(x, condition)
#> debug at #1: {
#> condition_call <- substitute(condition)
#> r <- eval(condition_call, x, parent.frame())
#> x[r, ]
#> }
n
#> debug at #2: condition_call <- substitute(condition)
n
#> debug at #3: r <- eval(condition_call, x, parent.frame())
r <- eval(condition_call, x, parent.frame())
#> Error in eval(expr, envir, enclos) : object 'a' not found
condition_call
#> condition
eval(condition_call, x)
#> Error in eval(expr, envir, enclos) : object 'a' not found
Q
10.5 More on substitute()
To make it easier to experiment with substitute(), pryr provides the subs() function. It works exactly the same way as substitute() except it has a shorter name and it works in the global environment. These two features make experimentation easier:
a <- 1
b <- 2
subs(a + b + z)
#> 1 + 2 + z
The second argument env (of both subs() and substitute()) can override the use of the current environment, and provide an alternative via a list of name-value pairs:
subs(a + b, list(a = "y"))
#> "y" + b
subs(a + b, list(a = quote(y)))
#> y + b
subs(a + b, list(a = quote(y())))
#> y() + b
Remember that every action in R is a function call, so we can also replace + with another function:
subs(a + b, list("+" = quote(f)))
#> f(a, b)
subs(a + b, list("+" = quote(`*`)))
#> a * b
Adding an escape hatch to substitute()
substitute() is itself a function that uses non-standard evaluation and doesn’t have an escape hatch. This means we can’t use substitute() if we already have an expression saved in a variable:
x <- quote(a + b)
substitute(x, list(a = 1, b = 2))
#> x
Although substitute() doesn’t have a built-in escape hatch, we can use the function itself to create one:
substitute_q <- function(x, env) {
call <- substitute(substitute(y, env), list(y = x))
eval(call)
}
x <- quote(a + b)
substitute_q(x, list(a = 1, b = 2))
#> 1 + 2
- First, the expression
substitute(y, env)is captured andyis replaced by the value ofx. Because we’ve putxinside a list, it will be evaluated and the rules of substitute will replaceywith its value. This yields the expressionsubstitute(a + b, env). - Next we evaluate
substitute(a + b, env)givenenv=list(a = 1, b = 2)and the result will be1 + 2.
Capturing unevaluated …
Another useful technique is to capture all of the unevaluated expressions in .... Base R functions do this in many ways, but there’s one technique that works well across a wide variety of situations:
dots <- function(...) {
eval(substitute(alist(...)))
}
This uses the alist() function which simply captures all its arguments. This function is the same as pryr::dots(). pryr also provides pryr::named_dots(), which, by using deparsed expressions as default names, ensures that all arguments are named (just like data.frame()).
10.6 The downsides of non-standard evaluation
The biggest downside of NSE is that functions that use it are no longer referentially transparent. A function is referentially transparent if you can replace its arguments with their values and its behaviour doesn’t change. For example, if a function, f(), is referentially transparent and both x and y are 10, then f(x), f(y), and f(10) will all return the same result. Referentially transparent code is easier to reason about because the names of objects don’t matter, and because you can always work from the innermost parentheses outwards.
There are many important functions that by their very nature are not referentially transparent. Take the assignment operator. You can’t take a <- 1 and replace a by its value and get the same behaviour.
Using NSE prevents a function from being referentially transparent. This makes the mental model needed to correctly predict the output much more complicated. So, it’s only worthwhile to use NSE if there is significant gain. For example, library() and require() can be called either with or without quotes, because internally they use deparse(substitute(x)) plus some other tricks. This means that these two lines do exactly the same thing:
library(ggplot2)
library("ggplot2")
Things start to get complicated if the variable is associated with a value. What package will this load?
ggplot2 <- "plyr"
library(ggplot2)
There are a number of other R functions that work in this way, like ls(), rm(), data(), demo(), example(), and vignette(). To me, eliminating two keystrokes is not worth the loss of referential transparency, and I don’t recommend you use NSE for this purpose.
One situation where non-standard evaluation is worthwhile is data.frame(). If not explicitly supplied, it uses the input to automatically name the output variables:
x <- 10
y <- "a"
df <- data.frame(x, y)
names(df)
#> [1] "x" "y"
I think it’s worthwhile because it eliminates a lot of redundancy in the common scenario when you’re creating a data frame from existing variables. More importantly, if needed, it’s easy to override this behaviour by supplying names for each variable.
Non-standard evaluation allows you to write functions that are extremely powerful. However, they are harder to understand and to program with. As well as always providing an escape hatch, carefully consider both the costs and benefits of NSE before using it in a new domain.
11. Expressions
Throughout this chapter we’re going to use tools from the pryr package to help see what’s going on.
11.1 Structure of expressions
An expression is also called an abstract syntax tree (AST) because it represents the hierarchical tree structure of the code. We’ll use pryr::ast() to see this more clearly:
x <- 4
# 恰好构成一个先根遍历(pre-order)
ast(y <- x * 10)
#> \- () # A function call
#> \- `<- # the function name (also a name)
#> \- `y # the 1st argument (also a name)
#> \- () # the 2nd argument (another function call)
#> \- `*
#> \- `x
#> \- 10 # A constant
ast(function(x = 1, y) x)
#> \- ()
#> \- `function
#> \- [] # A pairlist
#> \ x = 1
#> \ y =`MISSING
#> \- `x
#> \- <srcref> # An attribute of function
There are four possible components of an expression:
- Constants are length one atomic vectors, like
"a",10,1LorTRUE.ast()displays them as is.- Quoting a constant returns it unchanged:
identical(1, quote(1)) == TRUE
- Quoting a constant returns it unchanged:
- Names, or symbols, represent the name of an object rather than its value.
ast()prefixes names with a backtick, like`x. - Calls represent the action of calling a function.
ast()prints()and then lists the children. The first child is the function that is called, and the remaining children are the function’s arguments. - Pairlists, short for dotted pair lists (in the form of
< e1 . e2 >), are a legacy of R’s past. They are only used in one place: the formal arguments of a function.ast()prints[]at the top-level of a pairlist.
Note that str() does not follow these naming conventions when describing objects. Instead, it describes names as “symbols” and calls as “language objects”:
str(quote(a))
#> symbol a
str(quote(a + b))
#> language a + b
11.2 Names
Typically, we use quote() to capture names. You can also convert a string to a name with as.name(). However, this is most useful only when as.name() receives strings as input:
as.name("name")
#> name
identical(quote(name), as.name("name"))
#> [1] TRUE
is.name("name")
#> [1] FALSE
is.name(quote(name))
#> [1] TRUE
is.name(quote(f(name)))
#> [1] FALSE
Names are also called symbols. as.symbol() and is.symbol() are identical to as.name() and is.name().
Names that would otherwise be invalid are automatically surrounded by backticks (意思是如果不用 backticks 包一下的话就是个非法的 name):
as.name("a b")
#> `a b`
as.name("if")
#> `if`
There’s one special name that needs a little extra discussion: the empty name. It is used to represent missing arguments. This object behaves strangely. You can’t bind it to a variable. If you do, it triggers an error about missing arguments. It’s only useful if you want to programmatically create a function with missing arguments.
f <- function(x) 10
formals(f)$x
#> # empty line here
is.name(formals(f)$x)
#> [1] TRUE
as.character(formals(f)$x)
#> [1] ""
missing_arg <- formals(f)$x
# Doesn't work!
is.name(missing_arg)
#> Error in eval(expr, envir, enclos): argument "missing_arg" is missing, with no default
11.3 Calls
A call is very similar to a list. It has length, [[ and [ methods. The first element of the call is the function that gets called. It’s usually the name of a function:
x <- quote(read.csv("important.csv", row.names = FALSE))
x[[1]]
#> read.csv
is.name(x[[1]])
#> [1] TRUE
You can add, modify, and delete elements of the call with the standard replacement operators, like x$row.names <- TRUE or x[[4]] <- NULL.
Calls also support the [ method. But use it with care:
x <- quote(read.csv("important.csv", row.names = FALSE))
x[1]
#> read.csv()
x[2]
#> "important.csv"()
x[-1] # remove the function name - but it's still a call!
#> "important.csv"(row.names = FALSE)
x[-2] # remove the first argument
#> read.csv(row.names = FALSE)
# A list of the unevaluated arguments
as.list(x[-1])
#> [[1]]
#> [1] "important.csv"
#>
#> $row.names
#> [1] FALSE
Generally speaking, because R’s function calling semantics are so flexible, getting or setting arguments by position is dangerous. To work around this problem, pryr provides standardise_call(). It uses the base match.call() function to convert all positional arguments to named arguments:
m1 <- quote(read.delim("data.txt", sep = "|"))
m2 <- quote(read.delim(s = "|", "data.txt"))
m3 <- quote(read.delim(file = "data.txt", , "|"))
standardise_call(m1)
#> read.delim(file = "data.txt", sep = "|")
standardise_call(m2)
#> read.delim(file = "data.txt", sep = "|")
standardise_call(m3)
#> read.delim(file = "data.txt", sep = "|")
To create a new call from its components, you can use call() or as.call(). The first argument to call() is a string which gives a function name. The other arguments are expressions that represent the arguments of the call.
call(":", 1, 10)
#> 1:10
call("mean", quote(1:10), na.rm = TRUE)
#> mean(1:10, na.rm = TRUE)
as.call() is a minor variant of call() that takes a single list as input. The first element is a name or call. The subsequent elements are the arguments.
as.call(list(quote(mean), quote(1:10)))
#> mean(1:10)
11.4 Capturing the current call
sys.call()captures exactly what the user typed.match.call()makes a call that only uses named arguments. It’s like automatically callingpryr::standardise_call()on the result ofsys.call()
f <- function(abc = 1, def = 2, ghi = 3) {
list(sys = sys.call(), match = match.call())
}
f(d = 2, 2) # d 模糊匹配到 def
#> $sys
#> f(d = 2, 2)
#>
#> $match
#> f(abc = 2, def = 2)
Modelling functions often use match.call() to capture the call used to create the model. This makes it possible to update() a model, re-fitting the model after modifying some of original arguments. Here’s an example of update() in action:
mod <- lm(mpg ~ wt, data = mtcars)
update(mod, formula = . ~ . + cyl)
#>
#> Call:
#> lm(formula = mpg ~ wt + cyl, data = mtcars)
#>
#> Coefficients:
#> (Intercept) wt cyl
#> 39.686 -3.191 -1.508
具体实现部分省略。
11.5 Pairlists
Pairlists are a holdover from R’s past. They behave identically to lists, but have a different internal representation (as a linked list rather than a vector). Pairlists have been replaced by lists everywhere except in function arguments.
The only place you need to care about the difference between a list and a pairlist is if you’re going to construct functions by hand:
make_function <- function(args, body, env = parent.frame()) {
args <- as.pairlist(args)
# `function 本身也是个 operator,作用是返回一个 function
eval(call("function", args, body), env)
}
This function is also available in pryr, where it does a little extra checking of arguments. make_function() is best used in conjunction with alist() (alist for Argument LIST). alist() doesn’t evaluate its arguments so that alist(x = a) is shorthand for list(x = quote(a)).
add <- make_function(alist(a = 1, b = 2), quote(a + b))
add(1)
#> [1] 3
add(1, 2)
#> [1] 3
# To have an argument with no default, you need an explicit =
make_function(alist(a = , b = a), quote(a + b))
#> function (a, b = a)
#> a + b
# To take `...` as an argument put it on the LHS of =
make_function(alist(a = , b = , ... =), quote(a + b))
#> function (a, b, ...)
#> a + b
make_function() has one advantage over using closures to construct functions: with it, you can easily read the source code. For example:
adder <- function(x) {
make_function(alist(y =), substitute({x + y}), parent.frame())
}
adder(10)
#> function (y)
#> {
#> 10 + y
#> }
One useful application of make_function() is in functions like curve(). curve() allows you to plot a mathematical function without creating an explicit R function:
curve(sin(exp(4 * x)), n = 1000)
Here x is a pronoun (代词). x doesn’t represent a single concrete value, but is instead a placeholder that varies over the range of the plot. One way to implement curve() would be with make_function():
curve2 <- function(expr, xlim = c(0, 1), n = 100,
env = parent.frame()) {
f <- make_function(alist(x = ), substitute(expr), env)
x <- seq(xlim[1], xlim[2], length = n)
y <- f(x)
plot(x, y, type = "l", ylab = deparse(substitute(expr)))
}
Functions that use a pronoun are called anaphoric functions. They are used in Arc (a lisp-like language), Perl, and Clojure.
11.6 Parsing and deparsing
Sometimes code is represented as a string, rather than as an expression. You can convert a string to an expression with parse(). parse() is the opposite of deparse(): it takes a character vector and returns an expression object.
- The primary use of
parse()is parsing files of code to disk, so the first argument is a file path. - If you have code in a character vector, you need to use the
textargument.
z <- quote(y <- x * 10)
deparse(z)
#> [1] "y <- x * 10"
parse(text = deparse(z))
#> expression(y <- x * 10)
Because there might be many top-level calls in a file, parse() doesn’t return just a single expression. Instead, it returns an expression object, which is essentially a list of expressions:
exp <- parse(text = c("
x <- 4
x
5
"))
length(exp)
#> [1] 3
typeof(exp)
#> [1] "expression"
exp[[1]]
#> x <- 4
exp[[2]]
#> x
You can create expression objects by hand with expression(), but I wouldn’t recommend it. There’s no need to learn about this esoteric data structure if you already know how to use expressions.
With parse() and eval(), it’s possible to write a simple version of source(). We read in the file from disk, parse() it and then eval() each component in a specified environment. This version defaults to a new environment, so it doesn’t affect existing objects. source() invisibly returns the result of the last expression in the file, so simple_source() does the same.
simple_source <- function(file, envir = new.env()) {
stopifnot(file.exists(file))
stopifnot(is.environment(envir))
lines <- readLines(file, warn = FALSE)
exprs <- parse(text = lines)
n <- length(exprs)
if (n == 0L) return(invisible())
for (i in seq_len(n - 1)) {
eval(exprs[i], envir)
}
invisible(eval(exprs[n], envir))
}
11.7 Walking the AST with recursive functions
It’s easy to modify a single call with substitute() or pryr::modify_call(). For more complicated tasks we need to work directly with the AST. The base codetools package provides some useful motivating examples of how we can do this: \index{recursion!over ASTs}
findGlobals()locates all global variables used by a function. This can be useful if you want to check that your function doesn’t inadvertently rely on variables defined in their parent environment.checkUsage()checks for a range of common problems including unused local variables, unused parameters, and the use of partial argument matching.
To write functions like findGlobals() and checkUsage(), we’ll need a new tool. Because expressions have a tree structure, using a recursive function would be the natural choice. The key to doing that is getting the recursion right. This means making sure that you know what the base case is and figuring out how to combine the results from the recursive case. For calls, there are two base cases (atomic vectors and names) and two recursive cases (calls and pairlists). This means that a function for working with expressions will look like:
recurse_call <- function(x) {
if (is.atomic(x)) {
# Return a value
} else if (is.name(x)) {
# Return a value
} else if (is.call(x)) {
# Call recurse_call recursively
} else if (is.pairlist(x)) {
# Call recurse_call recursively
} else {
# User supplied incorrect input
stop("Don't know how to handle type ", typeof(x),
call. = FALSE)
}
}
11.7.1 Finding F(ALSE) and T(RUE)
We’ll start simple with a function that determines whether a function uses the logical abbreviations T and F. Using T and F is generally considered to be poor coding practice, and is something that R CMD check will warn about. Let’s first compare the AST for T vs. TRUE:
ast(TRUE)
#> \- TRUE
ast(T)
#> \- `T
TRUE is parsed as a logical vector of length one, while T is parsed as a name. This tells us how to write our base cases for the recursive function: while an atomic vector will never be a logical abbreviation, a name might.
logical_abbr <- function(x) {
if (is.atomic(x)) {
FALSE
} else if (is.name(x)) {
identical(x, quote(T)) || identical(x, quote(F))
} else if (is.call(x) || is.pairlist(x)) {
for (i in seq_along(x)) {
if (logical_abbr(x[[i]])) return(TRUE)
}
FALSE
} else {
stop("Don't know how to handle type ", typeof(x),
call. = FALSE)
}
}
logical_abbr(quote(TRUE))
#> [1] FALSE
logical_abbr(quote(T))
#> [1] TRUE
logical_abbr(quote(mean(x, na.rm = T)))
#> [1] TRUE
logical_abbr(quote(function(x, na.rm = T) FALSE))
#> [1] TRUE
11.7.2 Finding all variables created by assignment
The next task, listing all variables created by assignment, is a little more complicated. Again, we start by looking at the AST for assignment:
ast(x <- 10)
#> \- ()
#> \- `<-
#> \- `x
#> \- 10
Assignment is a call where the first element is the name <-, the second is the object the name is assigned to, and the third is the value to be assigned. This makes the base cases simple: constants and names don’t create assignments, so they return NULL. The recursive cases aren’t too hard either. We lapply() over pairlists and over calls to functions other than <-.
非常精彩的一个重构的例子,具体请看书。
11.7.3 Modifying the call tree
The next step up in complexity is returning a modified call tree, like what you get with bquote(). bquote() is a slightly more flexible form of quote(): it allows you to optionally quote and unquote some parts of an expression (it’s similar to the backtick operator in Lisp). Everything is quoted, unless it’s encapsulated in .() in which case it’s evaluated and the result is inserted:
a <- 1
b <- 3
bquote(a + b)
#> a + b
bquote(a + .(b))
#> a + 3
bquote(.(a) + .(b))
#> 1 + 3
bquote(.(a + b))
#> [1] 4
How does bquote() work? Below, I’ve rewritten bquote() to use the same style as our other functions:
bquote2 <- function (x, where = parent.frame()) {
if (is.atomic(x) || is.name(x)) {
# Leave unchanged
x
} else if (is.call(x)) {
if (identical(x[[1]], quote(.))) {
# Call to .(), so evaluate
eval(x[[2]], where)
} else {
# Otherwise apply recursively, turning result back into call
as.call(lapply(x, bquote2, where = where))
}
} else if (is.pairlist(x)) {
as.pairlist(lapply(x, bquote2, where = where))
} else {
# User supplied incorrect input
stop("Don't know how to handle type ", typeof(x),
call. = FALSE)
}
}
x <- 1
y <- 2
bquote2(quote(x == .(x)))
#> x == 1
bquote2(quote(function(x = .(x)) {
x + .(y)
}))
#> function(x = 1) {
#> x + 2
#> }
The main difference between this and the previous recursive functions is that after we process each element of calls and pairlists, we need to coerce them back to their original types.
These tools are somewhat similar to Lisp macros, as discussed in Programmer’s Niche: Macros in R by Thomas Lumley. However, macros are run at compile-time, which doesn’t have any meaning in R, and always return expressions. They’re also somewhat like Lisp fexprs. A fexpr is a function where the arguments are not evaluated by default. The terms macro and fexpr are useful to know when looking for useful techniques from other languages.
12. Domain Specific Languages
The combination of first class environments, lexical scoping, non-standard evaluation, and metaprogramming gives us a powerful toolkit for creating embedded domain specific languages (DSLs) in R. Embedded DSLs take advantage of a host language’s parsing and execution framework, but adjust the semantics to make them more suitable for a specific task. DSLs are a very large topic, and this chapter will only scratch the surface, focussing on important implementation techniques rather than on how you might come up with the language in the first place.
R’s most popular DSL is the formula specification, which provides a succinct way of describing the relationship between predictors and the response in a model. Other examples include ggplot2 (for visualisation) and plyr (for data manipulation). Another package that makes extensive use of these ideas is dplyr, which provides translate_sql() to convert R expressions into SQL:
library(dplyr)
translate_sql(sin(x) + tan(y))
#> <SQL> SIN("x") + TAN("y")
translate_sql(x < 5 & !(y >= 5))
#> <SQL> "x" < 5.0 AND NOT(("y" >= 5.0))
translate_sql(first %like% "Had*")
#> <SQL> "first" LIKE 'Had*'
translate_sql(first %in% c("John", "Roger", "Robert"))
#> <SQL> "first" IN ('John', 'Roger', 'Robert')
translate_sql(like == 7)
#> <SQL> "like" = 7.0
12.1 DSL Example 1: Generating HTML
12.1.1 Goal
Our goal is to make it easy to generate HTML from R:
with_html(body(
h1("A heading", id = "first"),
p("Some text &", b("some bold text.")),
img(src = "myimg.png", width = 100, height = 100)
))
## Generates:
<body>
<h1 id='first'>A heading</h1>
<p>Some text & <b>some bold text.</b></p>
<img src='myimg.png' width='100' height='100' />
</body>
12.2 DSL Example 2: Turning R mathematical expressions into LaTeX
12.2.1 Goal
Our goal is to use these rules to automatically convert an R expression to its appropriate LaTeX representation. We’ll tackle this in four stages:
- Convert known symbols:
- E.g.
pi=>\pi
- E.g.
- Leave other symbols unchanged:
- E.g.
x=>x,y=>y
- E.g.
- Convert known functions to their special forms:
- E.g.
sqrt(frac(a, b))=>\sqrt{\frac{a, b}}
- E.g.
- Wrap unknown functions with
\textrm:- E.g.
f(a)=>\textrm{f}(a)
- E.g.
Part IV. Performant code
13. Performance
13.1 Why is R slow?
To understand R’s performance, it helps to think about R both a) as a language and b) as an implementation of that language.
- The language is abstract: it defines what R code means and how it should work.
- I’ll call the language R-language.
- The implementation is concrete: it reads R code and computes a result.
- The most popular implementation is the one from r-project.org.
- I’ll call that implementation GNU-R.
- There are alternative R implementations like pqR (pretty quick R), Renjin, FastR and Riposte
The distinction between R-language and GNU-R is a bit murky because the R-language is not formally defined. The R-language is mostly defined in terms of how GNU-R works. This is in contrast to other languages, like C++ and javascript, that make a clear distinction between language and implementation by laying out formal specifications that describe in minute detail how every aspect of the language should work. Nevertheless, the distinction between R-language and GNU-R is still useful:
- poor performance due to the language is hard to fix without breaking existing code;
- fixing poor performance due to the implementation is easier.
Why is R slow? Two general reasons are:
- The design of the R-language imposes fundamental constraints on R’s speed.
- GNU-R is currently far from the theoretical maximum.
13.2 Microbenchmarking
While it’s hard to know exactly how much faster a better implementation could be, a “>10x” improvement in speed seems achievable.
The best tool for microbenchmarking in R is the microbenchmark package:
library(microbenchmark)
x <- runif(100)
microbenchmark(
sqrt(x),
x ^ 0.5
)
#> Unit: nanoseconds
#> expr min lq mean median uq max neval
#> sqrt(x) 1,820 2,040 2479 2,410 2,770 8,160 100
#> x^0.5 17,200 17,600 19928 19,400 19,700 87,500 100
By default, microbenchmark() runs each expression 100 times (controlled by the times parameter). In the process, it also randomises the order of the expressions. It summarises the results with a minimum (min), lower quartile (lq), median, upper quartile (uq), and maximum (max). Focus on the median, and use the upper and lower quartiles (lq and uq) to get a feel for the variability. In this example, you can see that using the special purpose sqrt() function is faster than the general exponentiation operator.
As with all microbenchmarks, pay careful attention to the units:
- ms: millisecond, 1s == 1,000ms
- µs: microsecond, 1s == 1,000,000µs
- ns: nanosecond, 1s == 1,000,000,000ns
13.3 Language performance
In this section, I’ll explore three trade-offs that limit the performance of the R-language:
- extreme dynamism,
- name lookup with mutable environments, and
- lazy evaluation of function arguments.
I’ll illustrate each trade-off with a microbenchmark, showing how it slows GNU-R down. I benchmark GNU-R because you can’t benchmark the R-language (it can’t run code). This means that the results are only suggestive of the cost of these design decisions, but are nevertheless useful.
13.3.1 Extreme dynamism
R is an extremely dynamic programming language. Almost anything can be modified after it is created, like adding new fields to an S3 object, or even changing its class. Pretty much the only things you can’t change are objects in sealed namespaces, which are created when you load a package.
- The advantage of dynamism is that you need minimal upfront planning. You can change your mind at any time, iterating your way to a solution without having to start afresh.
- The disadvantage of dynamism is that it’s difficult to predict exactly what will happen with a given function call.
- This is a problem because the easier it is to predict what’s going to happen, the easier it is for an interpreter or compiler to make an optimisation.
- For example, the following loop is slow in R, because R doesn’t know that
xis always an integer. That means R has to look for the right+method (i.e., is it adding doubles, or integers?) in every iteration of the loop.
x <- 0L
for (i in 1:1e6) {
x <- x + 1
}
The cost of finding the right method is higher for non-primitive functions. microbenchmark 部分略。
13.3.2 Name lookup with mutable environments
It’s surprisingly difficult to find the value associated with a name in the R-language. This is due to combination of lexical scoping and extreme dynamism. This means that you can’t do name lookup just once: you have to start from scratch each time (比如我们在函数的内部访问了函数外部的一个 a,然后在函数内部我们自己又创建了一个 a).
This problem is exacerbated by the fact that almost every operation is a lexically scoped function call. You might think the following simple function calls two functions: + and ^. In fact, it calls four because { and ( are regular functions in R.
f <- function(x, y) {
(x + y) ^ 2
}
Since these functions are in the global environment, R has to look through every environment in the search path, which could easily be 10 or 20 environments. microbenchmark 部分略。
13.3.3 Lazy evaluation overhead
To implement lazy evaluation, R uses a promise object that contains the expression needed to compute the result and the environment in which to perform the computation. Creating these objects has some overhead, so each additional argument to a function decreases its speed a little. microbenchmark 部分略。
13.4 Implementation performance
The design of the R language limits its maximum theoretical performance, but GNU-R is currently nowhere near that maximum.
R is over 20 years old. It contains nearly 800,000 lines of code (about 45% C, 19% R, and 17% Fortran). Changes to base R can only be made by members of the R Core Team (or R-core for short). Currently R-core has twenty members, but only six are active in day-to-day development. No one on R-core works full time on R. Most are statistics professors who can only spend a relatively small amount of their time on R. Because of the care that must be taken to avoid breaking existing code, R-core tends to be very conservative about accepting new code. It can be frustrating to see R-core reject proposals that would improve performance. However, the overriding concern for R-core is not to make R fast, but to build a stable platform for data analysis and statistics.
Below, I’ll show two small, but illustrative, examples of parts of R that are currently slow but could, with some effort, be made faster.
13.4.1 Extracting a single value from a data frame
The following microbenchmark shows seven ways to access a single value from the built-in mtcars dataset (to be specific, the number in the bottom-right corner). The variation in performance is startling: the slowest method takes 30x longer than the fastest. There’s no reason that there has to be such a huge difference in performance. It’s simply that no one has had the time to fix it.
microbenchmark(
"[32, 11]" = mtcars[32, 11],
"$carb[32]" = mtcars$carb[32],
"[[c(11, 32)]]" = mtcars[[c(11, 32)]],
"[[11]][32]" = mtcars[[11]][32],
".subset2" = .subset2(mtcars, 11)[32]
)
#> Unit: nanoseconds
#> expr min lq mean median uq max neval
#> [32, 11] 35,700 36,800 40421 37,700 39,800 80,100 100
#> $carb[32] 19,000 19,800 22622 20,500 21,400 69,800 100
#> [[c(11, 32)]] 14,900 15,800 17690 16,600 19,700 28,000 100
#> [[11]][32] 14,300 15,000 17215 15,800 19,200 34,300 100
#> .subset2 511 888 5267 982 1,150 416,000 100
13.4.2 ifelse(), pmin(), and pmax()
Some base functions are known to be slow. For example, take the following three implementations of squish(), a function that ensures that the smallest value in a vector x is at least a and its largest value is at most b:
squish_ife <- function(x, a, b) {
ifelse(x <= a, a, ifelse(x >= b, b, x))
}
squish_p <- function(x, a, b) {
pmax(pmin(x, b), a)
}
squish_in_place <- function(x, a, b) {
x[x <= a] <- a
x[x >= b] <- b
x
}
x <- runif(100, -1.5, 1.5)
microbenchmark(
squish_ife = squish_ife(x, -1, 1),
squish_p = squish_p(x, -1, 1),
squish_in_place = squish_in_place(x, -1, 1),
unit = "us"
)
#> Unit: microseconds
#> expr min lq mean median uq max neval
#> squish_ife 81.1 83.5 88.1 85.7 89.8 177.0 100
#> squish_p 33.7 35.9 45.8 37.6 39.6 767.0 100
#> squish_in_place 11.5 12.2 13.5 12.8 13.5 24.7 100
pmin 和 pmax 的 p 是 parallel 的意思,通过代码来体会一下:
min(5:1, pi)
#> 1
pmin(5:1, pi)
#> 3.141593 3.141593 3.000000 2.000000 1.000000
We can often do even better by using C++.
14. Optimising code
Optimising code to make it run faster is an iterative process:
- Find the biggest bottleneck (the slowest part of your code).
- Instead of relying on your intuition, you should profile your code: use realistic inputs and measure the run-time of each individual operation.
- Try to eliminate it (you may not succeed but that’s ok).
- Repeat until your code is “fast enough.”
Prerequisites: In this chapter we’ll be using the lineprof package to understand the performance of R code. Get it with:
devtools::install_github("hadley/lineprof")
注意会用到 Rtools(中的 make),请把类似 “E:\Rtools\bin” 这样的路径添加到 path。
14.1 Measuring performance
To understand performance, you use a profiler. There are a number of different types of profilers. R uses a fairly simple type called a sampling or statistical profiler. A sampling profiler stops the execution of code every few milliseconds and records which function is currently executing (along with which function called that function, and so on). For example, consider f(), below:
f <- function() {
pause(0.1)
g()
h()
}
g <- function() {
pause(0.1)
h()
}
h <- function() {
pause(0.1)
}
tmp <- tempfile()
Rprof(tmp, interval = 0.1)
f()
Rprof(NULL)
summaryRprof(tmp)
更多 Rprof 的用法请参考 How to efficiently use Rprof in R?。简化一下 profile 的结果,我们可以得到的这样的一个结构:
f()
f() > g()
f() > g() > h()
f() > h()
Each line represents one “tick” of the profiler (0.1 s in this case), and function calls are nested with >. It shows that the code spends 0.1 s running f(), then 0.2 s running g(), then 0.1 s running h().
I wrote the lineprof package as a simpler way to visualise profiling data. As the name suggests, the fundamental unit of analysis in lineprof() is a line of code. This makes lineprof less precise than the alternatives (because a line of code can contain multiple function calls), but it’s easier to understand the context.
To use lineprof, we first save the code in a file and source() it. Here “profiling-example.R” contains the definition of f(), g(), and h(). Note that you must use source() to load the code. This is because lineprof uses srcrefs to match up the code to the profile, and the needed srcrefs are only created when you load code from disk. We then use lineprof() to run our function and capture the timing output:
library(lineprof)
source("profiling-example.R")
l <- lineprof(f())
l
#> time alloc release dups ref src
#> 1 0.074 0.001 0 0 profiling.R#2 f/pause
#> 2 0.143 0.002 0 0 profiling.R#3 f/g
#> 3 0.071 0.000 0 0 profiling.R#4 f/h
library(shiny)
shine(l)
lineprof provides some functions to navigate through this data structure, but they’re a bit clumsy. Instead, we’ll start an interactive explorer using the shiny package. shine(l) will open a new web page (or if you’re using RStudio, a new pane) that shows your source code annotated with information about how long each line took to run. shine() starts a shiny app which “blocks” your R session. To exit, you’ll need to stop the process using escape or ctrl + c.
Limitations
There are some other limitations to profiling:
- Profiling does not extend to C code. You can see if your R code calls C/C++ code but not what functions are called inside of your C/C++ code.
- Similarly, you can’t see what’s going on inside primitive functions or byte code compiled code.
- If you’re doing a lot of functional programming with anonymous functions, it can be hard to figure out exactly which function is being called.
- The easiest way to work around this is to name your functions.
- Lazy evaluation means that arguments are often evaluated inside another function. For example, in
j(i()), profiling would make it seem likei()was called byj()because the argument isn’t evaluated until it’s needed byj().- If this is confusing, you can create temporary variables to force computation to happen earlier.
14.2 Improving performance
The following sections introduce you to 6 basic techniques that I’ve found broadly useful:
- Look for existing solutions.
- Do less work.
- Vectorise.
- Parallelise.
- Avoid copies.
- Byte-code compile.
A final technique is to rewrite in a faster language, like C++. That’s a big topic and is covered in Rcpp.
Before we get into specific techniques, I’ll first describe a general strategy and organisational style that’s useful when working on performance.
14.2.1 Best practice: Organize your code
When tackling a bottleneck, you’re likely to come up with multiple approaches. Write a function for each approach, encapsulating all relevant behaviour. This makes it easier to check that each approach returns the correct result and to time how long it takes to run. To demonstrate the strategy, I’ll compare two approaches for computing the mean:
mean1 <- function(x) mean(x)
mean2 <- function(x) sum(x) / length(x)
I recommend that you keep a record of everything you try, even the failures. If a similar problem occurs in the future, it’ll be useful to see everything you’ve tried. To do this I often use R Markdown, which makes it easy to intermingle code with detailed comments and notes.
Next, generate a representative test case. The case should be big enough to capture the essence of your problem but small enough that it takes only a few seconds to run. You don’t want it to take too long because you’ll need to run the test case many times to compare approaches. On the other hand, you don’t want the case to be too small because then results might not scale up to the real problem.
Use this test case to quickly check that all variants return the same result. An easy way to do so is with stopifnot() and all.equal(). For real problems with fewer possible outputs, you may need more tests to make sure that an approach doesn’t accidentally return the correct answer. That’s unlikely for the mean.
x <- runif(100)
stopifnot(all.equal(mean1(x), mean2(x)))
Finally, use the microbenchmark package to compare how long each variation takes to run. For bigger problems, reduce the times parameter so that it only takes a couple of seconds to run. Focus on the median time, and use the upper and lower quartiles to gauge the variability of the measurement.
microbenchmark(
mean1(x),
mean2(x)
)
#> Unit: microseconds
#> expr min lq mean median uq max neval
#> mean1(x) 12.60 12.90 14.34 13.10 13.40 68.4 100
#> mean2(x) 1.58 1.74 2.35 2.11 2.22 26.4 100
(You might be surprised by the results: mean(x) is considerably slower than sum(x) / length(x). This is because, among other reasons, mean(x) makes two passes over the vector to be more numerically accurate.)
Before you start experimenting, you should have a target speed that defines when the bottleneck is no longer a problem. Setting such a goal is important because you don’t want to spend valuable time over-optimising your code.
14.2.2 Technique 1: Look for existing solutions
If your bottleneck is a function in a package, it’s worth looking at other packages that do the same thing. Two good places to start are:
- CRAN task views. If there’s a CRAN task view related to your problem domain, it’s worth looking at the packages listed there.
- Reverse dependencies of Rcpp, as listed on its CRAN page. Since these packages use C++, it’s possible to find a solution to your bottleneck written in a higher performance language.
Otherwise, the challenge is describing your bottleneck in a way that helps you find related problems and solutions. Knowing the name of the problem or its synonyms will make this search much easier.
It’s often helpful to restrict your search to R related pages. For Google, try rseek. For stackoverflow, restrict your search by including the R tag, [R], in your search.
As discussed above, record all solutions that you find, not just those that immediately appear to be faster. Some solutions might be initially slower, but because they are easier to optimise they end up being faster. You may also be able to combine the fastest parts from different approaches.
14.2.3 Technique 2: Unburden your functions
One way to do that is use a function tailored to a more specific type of input or ouput, or a more specific problem. For example:
rowSums(),colSums(),rowMeans(), andcolMeans()are faster than equivalent invocations that useapply()because they are vectorised.vapply()is faster thansapply()because it pre-specifies the output type.- If you want to see if a vector contains a single value,
any(x == 10)is much faster than10 %in% x. This is because testing equality is simpler than testing inclusion in a set.
Having this knowledge at your fingertips requires knowing that alternative functions exist: you need to have a good vocabulary. Good places to read code are the R-help mailing list and stackoverflow.
Some functions coerce their inputs into a specific type. If your input is not the right type, the function has to do extra work. Instead, look for a function that works with your data as it is, or consider changing the way you store your data. The most common example of this problem is using apply() on a data frame. apply() always turns its input into a matrix. Not only is this error prone (because a data frame is more general than a matrix), it is also slower.
Other functions will do less work if you give them more information about the problem. It’s always worthwhile to carefully read the documentation and experiment with different arguments. Some examples that I’ve discovered in the past include:
- For
read.csv(): specify known column types withcolClasses. - For
factor(): specify known levels withlevels. - For
cut(): don’t generate labels withlabels = FALSEif you don’t need them, or, even better, usefindInterval()as mentioned in the “see also” section of the documentation. unlist(x, use.names = FALSE)is much faster thanunlist(x).- For
interaction(): if you only need combinations that exist in the data, usedrop = TRUE.
Sometimes you can make a function faster by avoiding method dispatch, which can be costly in R. If you’re calling a method in a tight loop, you can avoid some of the costs by doing the method lookup only once:
- For S3, you can do this by calling
{generic}.{class}()instead of{generic}().- For example, calling
mean.default()quite a bit faster than callingmean()for small vectors. - This optimisation is a little risky. While
mean.default()is faster, it’ll fail in surprising ways ifxis not a numeric vector. You should only use it if you know for sure whatxis.
- For example, calling
- For S4, you can do this by using
findMethod()to find the method, saving it to a variable, and then calling that function.
Knowing that you’re dealing with a specific type of input can be another way to write faster code. For example, as.data.frame() is quite slow because it coerces each element into a data frame and then rbind()s them together. If you have a named list with vectors of equal length, you can directly transform it into a data frame. In this case, if you’re able to make strong assumptions about your input, you can write a method that’s about 20x faster than the default. Again, note the trade-off. This method is fast because it’s dangerous. If you give it bad inputs, you’ll get a corrupt data frame.
quickdf <- function(l) {
class(l) <- "data.frame"
attr(l, "row.names") <- .set_row_names(length(l[[1]]))
l
}
l <- lapply(1:26, function(i) runif(1e3))
names(l) <- letters
microbenchmark(
quick_df = quickdf(l),
as.data.frame = as.data.frame(l)
)
#> Unit: microseconds
#> expr min lq mean median uq max neval
#> quick_df 28.5 34.2 42.6 41.4 51.1 70.7 100
#> as.data.frame 2,560.0 3,050.0 3239.3 3,220.0 3,340.0 5,290.0 100
You can also take a general-purpose function and simplify its code for your specific goal. 书上简化 diff() 的做法是
- 假定 input 类型
- 固定 arguments 的值
A final example of doing less work is to use simpler data structures. For example, when working with rows from a data frame, it’s often faster to work with row indices than the whole data frame.
14.2.4 Technique 3: Vectorise
Vectorising your code is not just about avoiding for loops, although that’s often a step. Vectorising is about taking a “whole object” approach to a problem, thinking about vectors, not scalars. There are two key attributes of a vectorised function:
- It makes many problems simpler. Instead of having to think about the components of a vector, you only think about entire vectors.
- The loops in a vectorised function are written in C instead of R. Loops in C are much faster because they have much less overhead.
Functionals stressed the importance of vectorised code as a higher level abstraction. Vectorisation is also important for writing fast R code. This doesn’t mean simply using apply() or lapply(), or even Vectorise(). Those functions improve the interface of a function, but don’t fundamentally change performance. Using vectorisation for performance means finding the existing R function that is implemented in C and most closely applies to your problem.
例子略。
14.2.5 Technique 4: Avoid copies
A pernicious source of slow R code is growing an object with a loop. Whenever you use c(), append(), cbind(), rbind(), or paste() to create a bigger object, R must first allocate space for the new object and then copy the old object to its new home. If you’re repeating this many times, like in a for loop, this can be quite expensive. You’ve entered Circle 2 of the “R inferno”.
Here’s a little example that shows the problem. We first generate some random strings, and then combine them either iteratively with a loop using collapse(), or in a single pass using paste(). Note that the performance of collapse() gets relatively worse as the number of strings grows: combining 100 strings takes almost 30 times longer than combining 10 strings.
random_string <- function() {
paste(sample(letters, 50, replace = TRUE), collapse = "")
}
strings10 <- replicate(10, random_string())
strings100 <- replicate(100, random_string())
collapse <- function(xs) {
out <- ""
for (x in xs) {
out <- paste0(out, x)
}
out
}
microbenchmark(
loop10 = collapse(strings10),
loop100 = collapse(strings100),
vec10 = paste(strings10, collapse = ""),
vec100 = paste(strings100, collapse = "")
)
Modifying an object in a loop, e.g., x[i] <- y, can also create a copy, depending on the class of x.
14.2.6 Technique 5: Byte-code compile
R 2.13.0 introduced a byte code compiler which can increase the speed of some code. Using the compiler is an easy way to get improvements in speed. Even if it doesn’t work well for your function, you won’t have invested a lot of time in the effort. The following example shows the pure R version of lapply(). Compiling it gives a considerable speedup, although it’s still not quite as fast as the C version provided by base R.
lapply2 <- function(x, f, ...) {
out <- vector("list", length(x))
for (i in seq_along(x)) {
out[[i]] <- f(x[[i]], ...)
}
out
}
lapply2_c <- compiler::cmpfun(lapply2)
x <- list(1:10, letters, c(F, T), NULL)
microbenchmark(
lapply2(x, is.null),
lapply2_c(x, is.null),
lapply(x, is.null)
)
Byte code compilation really helps here, but in most cases you’re more likely to get a 5-10% improvement. All base R functions are byte code compiled by default.
14.2.7 Case study: t-test
一个非常详细的例子,写的很好,建议看书。
14.2.8 Technique 6: Parallelise
Parallelisation uses multiple cores to work simultaneously on different parts of a problem. It doesn’t reduce the computing time, but it saves your time because you’re using more of your computer’s resources.
What I want to show is a simple application of parallel computing to what are called “embarrassingly parallel problems”. An embarrassingly parallel problem is one that’s made up of many simple problems that can be solved independently. A great example of this is lapply() because it operates on each element independently of the others. It’s very easy to parallelise lapply() on Linux and the Mac because you simply substitute mclapply() for lapply(). The following code snippet runs a trivial (but slow) function on all cores of your computer.
library(parallel)
cores <- detectCores()
cores
#> [1] 32
pause <- function(i) {
function(x) Sys.sleep(i)
}
system.time(lapply(1:10, pause(0.25)))
#> user system elapsed
#> 0.002 0.000 2.508
system.time(mclapply(1:10, pause(0.25), mc.cores = cores))
#> user system elapsed
#> 0.017 0.120 0.326
Life is a bit harder in Windows. 具体看书。
There is some communication overhead with parallel computing. If the subproblems are very small, then parallelisation might hurt rather than help. It’s also possible to distribute computation over a network of computers (not just the cores on your local computer) but that’s beyond the scope of this book, because it gets increasingly complicated to balance computation and communication costs. A good place to start for more information is the high performance computing CRAN task view.
14.3 Other techniques
介绍了一些其他的资源(文档和书),有空可以看看。
15. Memory (很有意思,建议看书)
16. High performance functions with Rcpp
16.1 Getting started
cppFunction() allows you to write C++ functions in R:
library(Rcpp)
cppFunction('int add(int x, int y, int z) {
int sum = x + y + z;
return sum;
}')
# add works like a regular R function
add
#> function (x, y, z)
#> .Primitive(".Call")(<pointer: 0x7ff50baf33d0>, x, y, z)
add(1, 2, 3)
#> [1] 6
When you run this code, Rcpp will compile the C++ code and construct an R function that connects to the compiled C++ function.
16.1.1 Example 1: No inputs, scalar output
cppFunction('int one() {
return 1;
}')
This function returns an int (a scalar integer). The classes for the most common types of R vectors are: NumericVector, IntegerVector, CharacterVector, and LogicalVector.
16.1.2 Example 2: Scalar input, scalar output
cppFunction('int signC(int x) {
if (x > 0) {
return 1;
} else if (x == 0) {
return 0;
} else {
return -1;
}
}')
As in R you can use break to exit the loop, but to skip one iteration you need to use continue instead of next.
16.1.3 Example 3: Vector input, scalar output
# Bad practice anyway
sumR <- function(x) {
total <- 0
for (i in seq_along(x)) {
total <- total + x[i]
}
total
}
cppFunction('double sumC(NumericVector x) {
int n = x.size();
double total = 0;
for(int i = 0; i < n; ++i) {
total += x[i];
}
return total;
}')
16.1.4 Example 4: Vector input, vector output
pdistR <- function(x, ys) {
sqrt((x - ys) ^ 2)
}
cppFunction('NumericVector pdistC(double x, NumericVector ys) {
int n = ys.size();
NumericVector out(n);
for(int i = 0; i < n; ++i) {
out[i] = sqrt(pow(ys[i] - x, 2.0));
}
return out;
}')
Another useful way of making a vector is to copy an existing one: NumericVector zs = clone(ys).
In the Rcpp sugar section, you’ll see how to rewrite this function to take advantage of Rcpp’s vectorised operations so that the C++ code is almost as concise ([kənˈsaɪs], brief, yet including all important information) as R code.
16.1.5 Example 5: Matrix input, vector output
Each vector type in R has a matrix equivalent in Rcpp: NumericMatrix, IntegerMatrix, CharacterMatrix, and LogicalMatrix. For example, we could create a function that reproduces rowSums():
cppFunction('NumericVector rowSumsC(NumericMatrix x) {
int nrow = x.nrow(), ncol = x.ncol();
NumericVector out(nrow);
for (int i = 0; i < nrow; i++) {
double total = 0;
for (int j = 0; j < ncol; j++) {
total += x(i, j); # x[i, j] in R
}
out[i] = total;
}
return out;
}')
The main differences:
- In C++, you subset a matrix with
(), not[]. - Use
.nrow()and.ncol()methods to get the dimensions of a matrix.
16.1.6 Using sourceCpp()
So far, we’ve used inline C++ with cppFunction(). This makes presentation simpler, but for real problems, it’s usually easier to use stand-alone C++ files and then source them into R using sourceCpp().
Your stand-alone C++ file should have extension “.cpp”, and needs to start with Rcpp lib and namespace:
#include <Rcpp.h>
using namespace Rcpp;
And for each function that you want available within R, you need to prefix it with an Rcpp Attribute:
// [[Rcpp::export]]
You can embed R code in special C++ comment blocks. This is really convenient if you want to run some test code:
/*** R
# R code goes here
*/
注意:按 Using Rcpp with RStudio 的说法:
The
sourceCppfunction will first compile the C++ code into a shared library and thensourceall of the embedded R code.
而这里的 R code 一般都是函数调用,像上面说的 “run some test code” 就是个很常见的用法。比如你用 C++ 写了 foo(int x),你可以紧接着写个 R 来调用,比如 foo(100);,或是用 benchmark 来测。
The R code is run with source(echo = TRUE) so you don’t need to explicitly print output.
To compile the C++ code, use sourceCpp("path/to/file.cpp"). This will create the matching R functions and add them to your current session. Note that these functions can not be saved in a .Rdata file and reloaded in a later session; they must be recreated each time you restart R. For example, running sourceCpp() on the following file implements mean in C++ and then compares it to the built-in mean():
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
double meanC(NumericVector x) {
int n = x.size();
double total = 0;
for(int i = 0; i < n; ++i) {
total += x[i];
}
return total / n;
}
/*** R
library(microbenchmark)
x <- runif(1e5)
microbenchmark(
mean(x),
meanC(x)
)
*/
NB: if you run this code yourself, you’ll notice that meanC() is much faster than the built-in mean(). This is because it trades numerical accuracy for speed.
16.2 Attributes and other classes
All R objects have attributes, which can be queried and modified with .attr(). Rcpp also provides .names() as an alias for the name attribute. The following code snippet illustrates these methods. Note the use of ::create(), a class method. This allows you to create an R vector from C++ scalar values:
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
NumericVector attribs() {
NumericVector out = NumericVector::create(1, 2, 3);
out.names() = CharacterVector::create("a", "b", "c");
out.attr("my-attr") = "my-value";
out.attr("class") = "my-class";
return out;
}
For S4 objects, .slot() plays a similar role to .attr().
16.2.1 Functions
You can put R functions in an object of type Function. This makes calling an R function from C++ straightforward:
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
RObject callWithOne(Function f) {
return f(1);
}
Then call it from R:
callWithOne(function(x) x + 1)
#> [1] 2
callWithOne(paste)
#> [1] "1"
What type of object does an R function return? We don’t know, so we use the catchall type RObject. An alternative is to return a List. For example, the following code is a basic implementation of lapply in C++:
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
List lapply1(List input, Function f) {
int n = input.size();
List out(n);
for(int i = 0; i < n; i++) {
out[i] = f(input[i]); # calling R function f
}
return out;
}
In cpp, calling R functions with positional arguments is obvious, but to use named arguments, you need a special syntax:
f("y", 1);
f(_["x"] = "y", _["value"] = 1);
16.2.2 Other types
There are also classes for many more specialised language objects: Environment, ComplexVector, RawVector, DottedPair, Language, Promise, Symbol, WeakReference, and so on.
16.3 Missing values
16.3.1 Scalar NAs
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
List scalar_missings() {
int int_s = NA_INTEGER;
String chr_s = NA_STRING;
bool lgl_s = NA_LOGICAL;
double num_s2 = NAN;
return List::create(int_s, chr_s, lgl_s, num_s, num_s2);
}
str(scalar_missings())
#> List of 4
#> $ : int NA
#> $ : chr NA
#> $ : logi TRUE
#> $ : num NA
#> $ : num NaN
Integer NA
With integers, missing values are stored as the smallest integer. But, since C++ doesn’t know that the smallest integer has this special behaviour, if you do anything to it you’re likely to get an incorrect value: for example, evalCpp('NA_INTEGER + 1') gives -2147483647.
Double NA
R’s NA is a special type of IEEE 754 floating point number NaN (Not a Number). Any comparision that involves a NaN (or in C++, NAN) always evaluates as FALSE:
evalCpp("NAN == 1")
#> [1] FALSE
evalCpp("NAN < 1")
#> [1] FALSE
evalCpp("NAN > 1")
#> [1] FALSE
evalCpp("NAN == NAN")
#> [1] FALSE
But be careful when combining then with boolean values:
evalCpp("NAN && TRUE")
#> [1] TRUE
evalCpp("NAN || FALSE")
#> [1] TRUE
In numeric contexts NaNs will get propagated:
evalCpp("NAN + 1")
#> [1] NaN
evalCpp("NAN - 1")
#> [1] NaN
evalCpp("NAN / 1")
#> [1] NaN
evalCpp("NAN * 1")
#> [1] NaN
Boolean NA
While C++’s bool has two possible values (true or false), a logical vector in R has three (TRUE, FALSE, and NA). If you coerce a length 1 logical vector, make sure it doesn’t contain any missing values otherwise they will be converted to TRUE.
16.3.2 Vector NAs
With vectors, you need to use a missing value specific to the type of vector, NA_REAL, NA_INTEGER, NA_LOGICAL, NA_STRING:
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
List missing_sampler() {
return List::create(
NumericVector::create(NA_REAL),
IntegerVector::create(NA_INTEGER),
LogicalVector::create(NA_LOGICAL),
CharacterVector::create(NA_STRING));
}
str(missing_sampler())
#> List of 4
#> $ : num NA
#> $ : int NA
#> $ : logi NA
#> $ : chr NA
To check if a value in a vector is missing, use the class method ::is_na():
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
LogicalVector is_naC(NumericVector x) {
int n = x.size();
LogicalVector out(n);
for (int i = 0; i < n; ++i) {
out[i] = NumericVector::is_na(x[i]);
}
return out;
}
is_naC(c(NA, 5.4, 3.2, NA))
#> [1] TRUE FALSE FALSE TRUE
Another alternative is the sugar function is_na(), which takes a vector and returns a logical vector:
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
LogicalVector is_naC2(NumericVector x) {
return is_na(x);
}
is_naC2(c(NA, 5.4, 3.2, NA))
#> [1] TRUE FALSE FALSE TRUE
Finally, noNA(x) asserts that the vector x does not contain any missing values, and allows optimisation of some mathematical operations.
16.4 Rcpp sugar
Rcpp provides a lot of syntactic “sugar” to ensure that C++ functions work very similarly to their R equivalents. In fact, Rcpp sugar makes it possible to write efficient C++ code that looks almost identical to its R equivalent. If there’s a sugar version of the function you’re interested in, you should use it: it’ll be both expressive and well tested. Sugar functions aren’t always faster than a handwritten equivalent, but they will get faster in the future as more time is spent on optimising Rcpp.
16.4.1 Arithmetic and logical operators
All the basic arithmetic and logical operators are vectorised: + *, -, /, pow, <, <=, >, >=, ==, !=, !. For example, we could use sugar to considerably simplify the implementation of pdistC().
pdistR <- function(x, ys) {
sqrt((x - ys) ^ 2)
}
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
NumericVector pdistC2(double x, NumericVector ys) {
return sqrt(pow((x - ys), 2));
}
16.4.2 Logical summary functions
The sugar function any() and all() are fully lazy so that any(x == 0), for example, might only need to evaluate one element of a vector, and return a special type that can be converted into a bool using .is_true(), .is_false(), or .is_na(). We could also use this sugar to write an efficient function to determine whether or not a numeric vector contains any missing values. To do this in R, we could use any(is.na(x)):
any_naR <- function(x) any(is.na(x))
However, the above code will do the same amount of work regardless of the location of the missing value. Here’s the C++ implementation:
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
bool any_naC(NumericVector x) {
return is_true(any(is_na(x)));
}
x0 <- runif(1e5)
x1 <- c(x0, NA)
x2 <- c(NA, x0)
microbenchmark(
any_naR(x0), any_naC(x0),
any_naR(x1), any_naC(x1),
any_naR(x2), any_naC(x2)
)
#> Unit: microseconds
#> expr min lq mean median uq max neval
#> any_naR(x0) 592.00 611.00 708.89 622.00 694.00 1,790.0 100
#> any_naC(x0) 595.00 635.00 680.86 645.00 735.00 801.0 100
#> any_naR(x1) 551.00 612.00 765.49 624.00 751.00 1,910.0 100
#> any_naC(x1) 585.00 634.00 669.19 644.00 679.00 802.0 100
#> any_naR(x2) 326.00 332.00 457.22 347.00 402.00 1,570.0 100
#> any_naC(x2) 2.16 3.23 4.29 4.01 4.68 18.2 100
16.4.3 Vector views
A number of helpful functions provide a “view” of a vector: head(), tail(), rep_each(), rep_len(), rev(), seq_along(), and seq_len(). In R these would all produce copies of the vector, but in Rcpp they simply point to the existing vector and override the subsetting operator ([) to implement special behaviour. This makes them very efficient: for instance, rep_len(x, 1e6) does not have to make a million copies of x.
16.4.4 Other useful functions
Finally, there’s a grab bag of sugar functions that mimic frequently used R functions:
- Math functions:
abs(),acos(),asin(),atan(),beta(),ceil(),ceiling(),choose(),cos(),cosh(),digamma(),exp(),expm1(),factorial(),floor(),gamma(),lbeta(),lchoose(),lfactorial(),lgamma(),log(),log10(),log1p(),pentagamma(),psigamma(),round(),signif(),sin(),sinh(),sqrt(),tan(),tanh(),tetragamma(),trigamma(),trunc(). - Scalar summaries:
mean(),min(),max(),sum(),sd(), and (for vectors)var(). - Vector summaries:
cumsum(),diff(),pmin(), andpmax(). - Finding values:
match(),self_match(),which_max(),which_min(). - Dealing with duplicates:
duplicated(),unique(). d/q/p/rfor all standard distributions.
16.5 The STL
16.5.1 Using iterators
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
double sum3(NumericVector x) {
double total = 0;
NumericVector::iterator it;
for(it = x.begin(); it != x.end(); ++it) {
total += *it;
}
return total;
}
#include <numeric>
#include <Rcpp.h>
using namespace Rcpp;
// [[Rcpp::export]]
double sum4(NumericVector x) {
return std::accumulate(x.begin(), x.end(), 0.0);
}
accumulate() (along with the other functions in <numeric>, like adjacent_difference(), inner_product(), and partial_sum()) is not that important because Rcpp sugar provides equivalents.
16.5.2 Sets
The following function uses an unordered set to implement an equivalent to duplicated() for integer vectors. Note the use of seen.insert(x[i]).second:
insert()returns a pair,- the
.firstvalue is an iterator that points to element and - the
.secondvalue is a boolean that’s true if the value was a new addition to the set.
// [[Rcpp::plugins(cpp11)]]
#include <Rcpp.h>
#include <unordered_set>
using namespace Rcpp;
// [[Rcpp::export]]
LogicalVector duplicatedC(IntegerVector x) {
std::unordered_set<int> seen;
int n = x.size();
LogicalVector out(n);
for (int i = 0; i < n; ++i) {
out[i] = !seen.insert(x[i]).second;
}
return out;
}
Note that unordered sets are only available in C++ 11, which means we need to use the cpp11 plugin, [[Rcpp::plugins(cpp11)]].
16.6 Case studies (略)
16.7 Using Rcpp in a package (略)
17. R’s C interface
To see R’s complete C API, look at the header file Rinternals.h. It’s easiest to find and display this file from within R:
rinternals <- file.path(R.home("include"), "Rinternals.h")
file.show(rinternals)
All functions are defined with either the prefix Rf_ or R_ but are exported without it (unless #define R_NO_REMAP has been used).
I do not recommend using C for writing new high-performance code. Instead write C++ with Rcpp. The Rcpp API protects you from many of the historical idiosyncracies of the R API, takes care of memory management for you, and provides many useful helper methods.
To understand existing C code, it’s useful to generate simple examples of your own that you can experiment with. To that end, all examples in this chapter use the inline package, which makes it extremely easy to compile and link C code to your current R session.
17.1 Calling C functions from R
Generally, calling a C function from R requires two pieces: a C function and an R wrapper function that uses .Call(). The simple function below adds two numbers together and illustrates some of the complexities of coding in C:
// In C ----------------------------------------
#include <R.h>
#include <Rinternals.h>
SEXP add(SEXP a, SEXP b) {
SEXP result = PROTECT(allocVector(REALSXP, 1));
REAL(result)[0] = asReal(a) + asReal(b);
UNPROTECT(1);
return result;
}
# In R ----------------------------------------
add <- function(a, b) {
.Call("add", a, b)
}
(An alternative to using .Call is to use .External. It is used almost identically, except that the C function will receive a single argument containing a LISTSXP, a pairlist from which the arguments can be extracted. This makes it possible to write functions that take a variable number of arguments. However, it’s not commonly used in base R and inline does not currently support .External functions.)
In this chapter we’ll produce the two pieces in one step by using the inline package. This allows us to write:
add <- cfunction(c(a = "integer", b = "integer"), "
SEXP result = PROTECT(allocVector(REALSXP, 1));
REAL(result)[0] = asReal(a) + asReal(b);
UNPROTECT(1);
return result;
")
add(1, 5)
17.2 R’s C data structures
At the C-level, all R objects are stored in a common datatype, the SEXP, or S-expression. All R objects are S-expressions so every C function that you create must return a SEXP as output and take SEXPs as inputs. (Technically, this is a pointer to a structure with typedef SEXPREC.) A SEXP is a variant type, with subtypes for all R’s data structures. The most important types are:
REALSXP: numeric vectorINTSXP: integer vectorLGLSXP: logical vectorSTRSXP: character vectorVECSXP: listCLOSXP: function (closure)ENVSXP: environment
Beware: In C, lists are called VECSXPs not LISTSXPs. This is because early implementations of lists were Lisp-like linked lists, which are now known as “pairlists”.
Character vectors are a little more complicated than the other atomic vectors. A STRSXPs contains a vector of CHARSXPs, where each CHARSXP points to C-style string stored in a global pool. This design allows individual CHARSXP’s to be shared between multiple character vectors, reducing memory usage.
There are also SEXPs for less common object types:
CPLXSXP: complex vectorsLISTSXP: “pair” lists. At the R level, you only need to care about the distinction lists and pairlists for function arguments, but internally they are used in many more placesDOTSXP: ‘…’SYMSXP: names/symbolsNILSXP:NULL
And SEXPs for internal objects, objects that are usually only created and used by C functions, not R functions:
LANGSXP: language constructsCHARSXP: “scalar” stringsPROMSXP: promises, lazily evaluated function argumentsEXPRSXP: expressions
There’s no built-in R function to easily access these names, but pryr provides sexp_type():
library(pryr)
sexp_type(10L)
#> [1] "INTSXP"
sexp_type("a")
#> [1] "STRSXP"
sexp_type(T)
#> [1] "LGLSXP"
sexp_type(list(a = 1))
#> [1] "VECSXP"
sexp_type(pairlist(a = 1))
#> [1] "LISTSXP"
17.3 Creating and modifying vectors
At the heart of every C function are conversions between R data structures and C data structures. Inputs and output will always be R data structures (SEXPs) and you will need to convert them to C data structures in order to do any work.
An additional complication is the garbage collector: if you don’t protect every R object you create, the garbage collector will think they are unused and delete them.
17.3.1 Creating vectors and garbage collection
The simplest way to create a new R-level object is to use allocVector(). It takes two arguments, the type of SEXP (or SEXPTYPE) to create, and the length of the vector:
dummy <- cfunction(body = '
SEXP dbls = PROTECT(allocVector(REALSXP, 4));
SEXP lgls = PROTECT(allocVector(LGLSXP, 4));
SEXP ints = PROTECT(allocVector(INTSXP, 4));
SEXP vec = PROTECT(allocVector(VECSXP, 3));
SET_VECTOR_ELT(vec, 0, dbls);
SET_VECTOR_ELT(vec, 1, lgls);
SET_VECTOR_ELT(vec, 2, ints);
UNPROTECT(4);
return vec;
')
dummy()
#> [[1]]
#> [1] 2.85e-316 1.71e-316 2.35e-316 0.00e+00
#> [[2]]
#> [1] TRUE TRUE TRUE FALSE
#> [[3]]
#> [1] 1 1 1 0
PROTECT()tells R that the object is in use and shouldn’t be deleted if the garbage collector is activated.UNPROTECT()takes a single integer argument,n, and unprotects the lastnobjects that were protected.- The number of protects and unprotects must match.
- If not, R will warn about a “stack imbalance in .Call”.
Other specialised forms of protection are needed in some circumstances:
UNPROTECT_PTR()unprotects the object pointed to by the SEXPs.PROTECT_WITH_INDEX()saves an index of the protection location that can be used to replace the protected value usingREPROTECT().
Properly protecting the R objects you allocate is extremely important! Improper protection leads to difficulty diagnosing errors, typically segfaults, but other corruption is possible as well. In general, if you allocate a new R object, you must PROTECT it.
For real functions, you may want to loop through each element in the vector and set it to a constant. The most efficient way to do that is to use memset():
zeroes <- cfunction(c(n_ = "integer"), '
int n = asInteger(n_);
SEXP out = PROTECT(allocVector(INTSXP, n));
memset(INTEGER(out), 0, n * sizeof(int));
UNPROTECT(1);
return out;
')
zeroes(10);
#> [1] 0 0 0 0 0 0 0 0 0 0
17.3.2 Missing and non-finite values
is_na <- cfunction(c(x = "ANY"), '
int n = length(x);
SEXP out = PROTECT(allocVector(LGLSXP, n));
for (int i = 0; i < n; i++) {
switch(TYPEOF(x)) {
case LGLSXP:
LOGICAL(out)[i] = (LOGICAL(x)[i] == NA_LOGICAL);
break;
case INTSXP:
LOGICAL(out)[i] = (INTEGER(x)[i] == NA_INTEGER);
break;
case REALSXP:
LOGICAL(out)[i] = ISNA(REAL(x)[i]);
break;
case STRSXP:
LOGICAL(out)[i] = (STRING_ELT(x, i) == NA_STRING);
break;
default:
LOGICAL(out)[i] = NA_LOGICAL;
}
}
UNPROTECT(1);
return out;
')
is_na(c(NA, 1L))
#> [1] TRUE FALSE
is_na(c(NA, 1))
#> [1] TRUE FALSE
is_na(c(NA, "a"))
#> [1] TRUE FALSE
is_na(c(NA, TRUE))
#> [1] TRUE FALSE
17.3.3 Accessing vector data
Use helper functions REAL(), INTEGER(), LOGICAL(), COMPLEX(), and RAW() to access the C array inside numeric, integer, logical, complex, and raw vectors:
add_one <- cfunction(c(x = "numeric"), "
int n = length(x);
SEXP out = PROTECT(allocVector(REALSXP, n));
for (int i = 0; i < n; i++) {
REAL(out)[i] = REAL(x)[i] + 1; # REAL(out)[i] for out[i]
}
UNPROTECT(1);
return out;
")
add_one(as.numeric(1:10))
#> [1] 2 3 4 5 6 7 8 9 10 11
When working with longer vectors, there’s a performance advantage to using the helper function once and saving the result in a pointer:
px = REAL(x);
pout = REAL(out);
for (int i = 0; i < n; i++) {
pout[i] = px[i] + 2;
}
17.3.4 Character vectors and lists
Strings and lists are more complicated because the individual elements of a vector are SEXPs, not basic C data structures.
- Each element of a
STRSXPis aCHARSXPs, an immutable object that contains a pointer to C string stored in a global pool. STRING_ELT(x, i)extract theCHARSXPatx[i].CHAR(STRING_ELT(x, i))to get the actualconst char*string.
SET_STRING_ELT(x, i, value)set string atx[i].mkChar()turns a C string into aCHARSXP.mkString()turns a C string into aSTRSXP.
abc <- cfunction(NULL, '
SEXP out = PROTECT(allocVector(STRSXP, 3));
SET_STRING_ELT(out, 0, mkChar("a"));
SET_STRING_ELT(out, 1, mkChar("b"));
SET_STRING_ELT(out, 2, mkChar("c"));
UNPROTECT(1);
return out;
')
abc()
#> [1] "a" "b" "c"
17.3.5 Modifying inputs
add_three <- cfunction(c(x = "numeric"), '
REAL(x)[0] = REAL(x)[0] + 3;
return x;
')
x <- 1
y <- x
add_three(x)
#> [1] 4
x
#> [1] 4
y
#> [1] 4
Not only has it modified the value of x, it has also modified y! This happens because of R’s lazy copy-on-modify semantics. To avoid problems like this, always duplicate() inputs before modifying them:
add_four <- cfunction(c(x = "numeric"), '
SEXP x_copy = PROTECT(duplicate(x));
REAL(x_copy)[0] = REAL(x_copy)[0] + 4;
UNPROTECT(1);
return x_copy;
')
x <- 1
y <- x
add_four(x)
#> [1] 5
x
#> [1] 1
y
#> [1] 1
If you’re working with lists, use shallow_duplicate() to make a shallow copy; duplicate() will also copy every element in the list.
17.3.6 Coercing scalars
There are a few helper functions that turn length one R vectors into C scalars:
asLogical(x):LGLSXP=> intasInteger(x):INTSXP=> intasReal(x):REALSXP=> doubleCHAR(asChar(x)):STRSXP=>const char*
And helpers to go in the opposite direction:
ScalarLogical(x): int =>LGLSXPScalarInteger(x): int =>INTSXPScalarReal(x): double =>REALSXPmkString(x):const char*=>STRSXP
17.3.7 Long vectors
As of R 3.0.0, R vectors can have length greater than 2^31 - 1. This means that vector lengths can no longer be reliably stored in an int and if you want your code to work with long vectors, you can’t write code like int n = length(x). Instead use the R_xlen_t type and the xlength() function, and write R_xlen_t n = xlength(x).
17.4 Pairlists
In R code, there are only a few instances when you need to care about the difference between a pairlist and a list. In C, pairlists play much more important role because they are used for calls, unevaluated arguments, attributes, and in .... In C, lists and pairlists differ primarily in how you access and name elements.
Unlike lists (VECSXPs), pairlists (LISTSXPs) have no way to index into an arbitrary location. Instead, R provides a set of helper functions that navigate along a linked list. The basic helpers are:
CAR(), which extracts the first element of the list, and- CAR short for “Contents of the Address part of Register number”. 是 lisp 术语。
CDR(), which extracts the rest of the list.- CDR short for “Contents of the Decrement part of Register number”
- These can be composed to get
CAAR(),CDAR(),CADDR(),CADDDR(), and so on. - Corresponding to the getters, R provides setters
SETCAR(),SETCDR(), etc.
car <- cfunction(c(x = "ANY"), 'return CAR(x);')
cdr <- cfunction(c(x = "ANY"), 'return CDR(x);')
cadr <- cfunction(c(x = "ANY"), 'return CADR(x);')
x <- quote(f(a = 1, b = 2))
# The first element
car(x)
#> f
# Second and third elements
cdr(x)
#> $a
#> [1] 1
#>
#> $b
#> [1] 2
# Second element
car(cdr(x))
#> [1] 1
cadr(x)
#> [1] 1
Pairlists are always terminated with R_NilValue. To loop over all elements of a pairlist, use this template:
count <- cfunction(c(x = "ANY"), '
SEXP el, nxt;
int i = 0;
for(nxt = x; nxt != R_NilValue; el = CAR(nxt), nxt = CDR(nxt)) {
i++;
}
return ScalarInteger(i);
')
count(quote(f(a, b, c)))
#> [1] 4
count(quote(f()))
#> [1] 1
You can make new pairlists with CONS() (for CONStruct) and new calls with LCONS(). Remember to set the last value to R_NilValue. Since these are R objects as well, they are eligible for garbage collection and must be PROTECTed.
new_call <- cfunction(NULL, '
SEXP REALSXP_10 = PROTECT(ScalarReal(10));
SEXP REALSXP_5 = PROTECT(ScalarReal(5));
SEXP out = PROTECT(LCONS(install("+"), LCONS(
REALSXP_10, LCONS(
REALSXP_5, R_NilValue
)
)));
UNPROTECT(3);
return out;
')
gctorture(TRUE)
new_call()
#> 10 + 5
gctorture(FALSE)
TAG() and SET_TAG() allow you to get and set the tag (aka name) associated with an element of a pairlist. The tag should be a symbol. To create a symbol (the equivalent of as.symbol() in R), use install().
Attributes are also pairlists, but come with the helper functions setAttrib() and getAttrib():
set_attr <- cfunction(c(obj = "SEXP", attr = "SEXP", value = "SEXP"), '
const char* attr_s = CHAR(asChar(attr));
duplicate(obj);
setAttrib(obj, install(attr_s), value);
return obj;
')
x <- 1:10
set_attr(x, "a", 1)
#> [1] 1 2 3 4 5 6 7 8 9 10
#> attr(,"a")
#> [1] 1
(Note that setAttrib() and getAttrib() must do a linear search over the attributes pairlist.)
There are some (confusingly named) shortcuts for common setting operations: classgets(), namesgets(), dimgets(), and dimnamesgets() are the internal versions of the default methods of class<-, names<-, dim<-, and dimnames<-.
17.5 Input validation
It’s usually easier to valid the input at the R level:
add_ <- cfunction(signature(a = "integer", b = "integer"), "
SEXP result = PROTECT(allocVector(REALSXP, 1));
REAL(result)[0] = asReal(a) + asReal(b);
UNPROTECT(1);
return result;
")
add <- function(a, b) {
stopifnot(is.numeric(a), is.numeric(b)) # validation
stopifnot(length(a) == 1, length(b) == 1) # validation
add_(a, b)
}
Alternatively, if we wanted to be more accepting of diverse inputs we could do the following:
add <- function(a, b) {
a <- as.numeric(a)
b <- as.numeric(b)
if (length(a) > 1) warning("Only first element of a used")
if (length(b) > 1) warning("Only first element of b used")
add_(a, b)
}
To coerce objects at the C level, use PROTECT(new = coerceVector(old, SEXPTYPE)). This will return an error if the SEXP can not be converted to the desired type.
To check if an object is of a specified type, you can use TYPEOF, which returns a SEXPTYPE:
is_numeric <- cfunction(c("x" = "ANY"), "
return ScalarLogical(TYPEOF(x) == REALSXP);
")
is_numeric(7)
#> [1] TRUE
is_numeric("a")
#> [1] FALSE
There are also a number of helper functions which return 0 for FALSE and 1 for TRUE:
- For atomic vectors:
isInteger(),isReal(),isComplex(),isLogical(),isString(). - For combinations of atomic vectors:
isNumeric()(integer, logical, real),isNumber()(integer, logical, real, complex),isVectorAtomic()(logical, integer, numeric, complex, string, raw). - For matrices (
isMatrix()) and arrays (isArray()). - For more esoteric objects:
isEnvironment(),isExpression(),isList()(a pair list),isNewList()(a list),isSymbol(),isNull(),isObject()(S4 objects),isVector()(atomic vectors, lists, expressions).
Note that some of these functions behave differently to similarly named R functions with similar names. For example isVector() is true for atomic vectors, lists, and expressions, where is.vector() returns TRUE only if its input has no attributes apart from names.
17.6 Finding the C source code for a function
In the base package, R doesn’t use .Call(). Instead, it uses two special functions: .Internal() and .Primitive(). Finding the source code for these functions is an arduous task: you first need to look for their C function name in src/main/names.c and then search the R source code. pryr::show_c_source() automates this task using GitHub code search:
tabulate
#> function (bin, nbins = max(1L, bin, na.rm = TRUE))
#> {
#> if (!is.numeric(bin) && !is.factor(bin))
#> stop("'bin' must be numeric or a factor")
#> if (typeof(bin) != "integer")
#> bin <- as.integer(bin)
#> if (nbins > .Machine$integer.max)
#> stop("attempt to make a table with >= 2^31 elements")
#> nbins <- as.integer(nbins)
#> if (is.na(nbins))
#> stop("invalid value of 'nbins'")
#> .Internal(tabulate(bin, nbins)) # Then search this function!
#> }
#> <bytecode: 0x62c5bd0>
#> <environment: namespace:base>
pryr::show_c_source(.Internal(tabulate(bin, nbins)))
#> tabulate is implemented by do_tabulate with op = 0
Internal and primitive functions (i.e. functions wrapped by .Internal() and .Primitive()) have a somewhat different interface than .Call() functions. They always have four arguments:
SEXP call: the complete call to the function.CAR(call)gives the name of the function (as a symbol);CDR(call)gives the arguments.SEXP op: an “offset pointer”. This is used when multiple R functions use the same C function. For exampledo_logic()implements&,|, and!.show_c_source()prints this out for you.SEXP args: a pairlist containing the unevaluated arguments to the function.SEXP rho: the environment in which the call was executed.
例子略。
留下评论