Digest of Molecular Biology for Computer Scientists
1. What Is Life?
Another approach to defining “life” is to recognize its fundamental interrelatedness. All living things are related to each other. Any pair of organisms, no matter how different, have a common ancestor sometime in the distant past. Organisms came to differ from each other, and to reach modern levels of complexity through evolution.
Evolution has three components:
- Inheritance, the passing of characteristics from parents to offspring;
- Variation, the processes that make offspring other than exact copies of their parents; and
- In order to evolve, there must be a source of variation in the inheritance.
- Sources of variation include mutation, sexual recombination and genetic rearrangements.
- Most mutations are neutral or deleterious, and evolutionary change by mutation is a very slow, random search of a vast space.
- Sex, the ability of two successful organisms to combine bits of their genomes into an offspring, produces variants with a much higher probability of success.
- Given enough time, the search of the variation space has produced many viable organisms.
- Selection, the process that differentially favors the reproduction of some organisms, and hence their characteristics, over others.
- Selection is the process by which it is determined which variants will persist, and therefore also which parts of the space of possible variations will be explored.
These three factors define an evolutionary process. Perhaps the best definition of life is that it is the result of the evolutionary process taking place on Earth.
I have likened evolution to a search through a very large space of possible organism characteristics. That space can be defined quite precisely. All of an organism’s inherited characteristics are contained in a single messenger molecule: deoxyribonucleic ([di:ˌɒksi:raɪbəʊnu:’kli:ɪk]) acid, or DNA.
- The particular genetic encoding for an organism is called its genotype.
- The resulting physical characteristics of an organism is called its phenotype.
In the search space metaphor, every point in the space is a genotype. Evolutionary variation identifies the legal moves in this space. Selection is an evaluation function that determines how many other points a point can generate, and how long each point persists.
- It is worth noting that search happens in genotype space, but selection occurs on phenotypes.
Prokaryotes & Eukaryotes, Yeasts & People
Since Aristotle, scholars have tried to group these myriad ([ˈmɪriəd], 大量的) species into meaningful classes. This pursuit remains active, and the classifications are, to some degree, still controversial. Traditionally, these classifications have been based on the morphology of organisms. Literally, morphology means shape, but it is generally taken to include internal structure as well. Morhpology is only part of phenotype, however; other parts include physiology (the functioning of living structures) and development.
- physiology: [ˌfɪziˈɒlədʒi], 生理机能, 生理学
- development: The process by which a mature multicellular organism or part of an organism is produced by the addition of new cells, 发育
Here I will follow Woese, Kandler & Wheelis (1990), although some aspects of their taxonomy are controversial. They developed their classification of organisms by using distances based on sequence divergence in a ubiquitous piece of genetic sequence as shown in Figure 1.
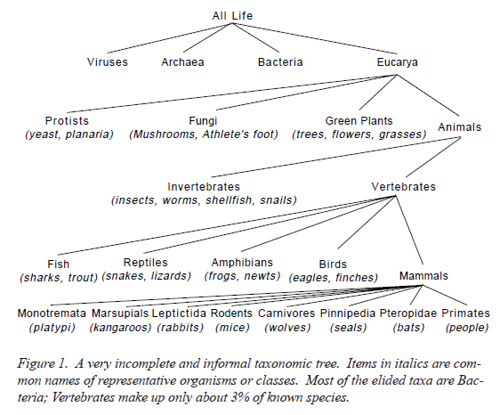
- elide: [iˈlaɪd], to omit; to suppress or alter (as a vowel or syllable); to strike out (as a written word)
更多内容参考 Taxonomic Ranks.
Evolutionary Time and Relatedness
There are a variety of ways to estimate how long ago two organisms diverged; that is, the last time they had a common ancestor. The more related two species are, the more recently they diverged.
Growing knowledge of the DNA sequences of many genes in many organisms makes possible estimates of the time of genetic divergence directly, by comparing their genetic sequences. If the rate of change can be quantified, and standards set, these differences can be translated into a “molecular clock”. The underlying and somewhat controversial assumption is that in some parts of the genome, the rate of mutation is fairly constant.
In order to get a rough idea of the degrees of relatedness among creatures, it is helpful to know the basic timeline of life on Earth.
- The oldest known fossils, stromalites found in Australia, indicate that life began at least 3.8 billion years ago. Geological evidence indicates that a major meteor impact about 4 billion years ago vaporized all of the oceans, effectively destroying any life that may have existed before that.
- Life remained like that for nearly 2 billion years. Then Eukarya came into being. There is evidence that eucarya began as symbiotic collections of simpler cells which were eventually assimilated and became organelles. Therefore, single-celled eukarya become very complex.
- The next major change in the history of life was the invention of sex.
An important difference between multicellular organisms and a colony of unicellular organisms (e.g. coral) is that multicellular organisms have separated germ (reproductive) cells from somatic (all the other) cells.
- Sperm and eggs are germ cells.
- All the other kinds of cells in the body are somatic. E.g. skin cells, or nerve cells, and blood cells.
- Both kinds of cells divide (细胞分裂) and create more of the same kind of cell, but only germ cells make new organisms.
更多内容参考 Cell Cycle.
Multicellular organisms all begin their lives from a single cell, a fertilized egg. From that single cell, all of the specialized cells arise through a process called cellular differentiation (细胞分化).
2. Living Parts: Tissues, Cells, Compartments and Organelles
The main advantage multicellular organisms possess over their single-celled competitors is cell specialization. Groups of cells specialized for a particular function are tissues, and their cells are said to have differentiated. Differentiated cells (except reproductive cells) cannot reproduce an entire organism.
Yet despite all of this variation, all of the cells in a multicellular organism have exactly the same genetic code. The differences between them come from differences in gene expression. Genes code for products that turn on and off other genes, which in turn regulate other genes, and so on.
The composition of cells:
- Membranes
- All present day cells have a phospholipid cell membrane.
- Phospholipids are lipids (oils or fats) with a phosphate group attached. The end with the phosphate group is hydrophillic (attracted to water) and the lipid end is hydrophobic (repelled by water).
- Cell membranes consist of two layers of these molecules, with the hydrophobic ends facing in, and the hydrophillic ends facing out. This keeps water and other materials from getting through the membrane, except through special pores or channels.
- Proteins
- Genetic material
- In Bacteria, the DNA is generally circular.
- In Eukaryotes, the DNA is linear.
- Some viruses (like the AIDS virus) store their genetic material in RNA.
- Nuclei
- Nuclei are the defining feature of Eucaryotic cells
- Cytoplasm
- Cytoplasm is the name for the gel-like collection of substances inside the cell.
- Ribosomes
- The function of ribosomes is to assemble proteins.
- The process of translating genetic information into proteins occurs within ribosomes.
- Mitochondria and Chroloplasts
- Other Parts of Cells
更多内容参考 Eukaryotic Cell Structure.
3. Life as a Biochemical Process
More and more of the functions of life (e.g. cell division, immune reaction, neural transmission) are coming to be understood as the interactions of complicated, self-regulating networks of chemical reactions. The substances that carry out and regulate these activities are generally referred to as biomolecules. Biomolecules include proteins, carbohydrates, lipids—all called macromolecules because they are relatively large—and a variety of small molecules.
The genetic material itself is also now known to be a particular macromolecule: DNA.
Life can be seen as a kind of information processing. The processes that transform matter and energy in living systems do so under the direction of a set of symbolically encoded instructions, i.e. the genomes.
4. The Molecular Building Blocks of Life
Living systems process matter, energy and information.
- The basic units of matter are proteins, which subserve all of the structural and many of the functional roles in the cell;
- The basic unit of energy is a phosphate bond in the molecule adenosine triphosphate (ATP);
- The basic units of information are four nucleotides, which are assembled together into DNA and RNA.
The chemical composition of living things is fairly constant across the entire range of life forms.
- About 70% of any cell is water.
- About 4% are small molecules like sugars, inorganic ions and ATP.
- Proteins make up between 15% and 20% of the cell.
- DNA and RNA range from 2% to 7% of the weight.
- The cell membranes, lipids and other, similar molecules make up the remaining 4% to 7%.
4.1 Energy
Living things obey all the laws of chemistry and physics, including the second law of thermodynamics, which states that the amount of entropy (disorder) in the universe is always increasing. The consumption of energy is the only way to create order in the face of entropy. Life doesn’t violate the second law; living things capture energy in a variety of forms, use it to create internal order, and then transfer energy back to the environment as heat. An increase in organization within a cell is coupled with a greater increase in disorder outside the cell.
Energy is taken out of ATP by the process of hydrolysis, which removes the outermost phosphate group, producing the molecule adenosine diphosphate (ADP). This process generates about 12 kcal (kilocalorie) per mole of ATP, a quantity appropriate for performing many cellular tasks. The energy “charge” of a cell is expressed in the ratio of ATP/ADP and the electrochemical difference between the inside and the outside of the cell (which is called the transmembrane potential). If ATP is depleted, the movement of ions caused by the transmembrane potential will result in the synthesis of additional ATP. If the transmembrane potential has been reduced (for example, after a neuron fires), ATP will be consumed to pump ions back across the gradient and restore the potential.
ATP is involved in most cellular processes, so it is sometimes called a currency metabolite. ATP can also be converted to other high energy phosphate compounds such as creatine phosphate, or other nucleotide triphosphates. In turn, these molecules provide the higher levels of energy necessary to transcribe genes and replicate chromosomes. Energy can also be stored in different chemical forms like carbohydrates and fats.
4.2 Proteins
Proteins are the primary components of living things, and they play many roles.
- Proteins provide structural support and the infrastructure that holds a creature together;
- they are enzymes that make the chemical reactions necessary for life possible;
- they are the switches that control whether genes are turned on or off;
- they are the sensors that see and taste and smell, and the effectors that make muscles move;
- they are the detectors that distinguish self from nonself and create an immune response.
Finding the proteins that make up a creature and understanding their function is the foundation of explanation in molecular biology.
Despite their radical differences in function, all proteins are made of the same basic constituents: the amino acids. Each amino acid shares a basic structure, consisting of
- a central carbon atom (C),
- an amino group (NH3) at one end,
- a carboxyl group (COOH) at the other, and
- a variable sidechain (R),
as shown in Figure 2.
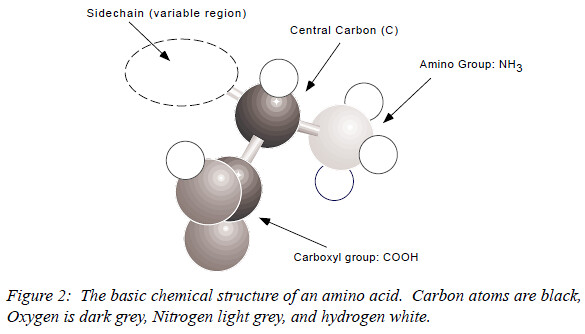
Under biological conditions the amino end of the molecule is positively charged, and the carboxyl end is negatively charged. Chains of amino acids are assembled by a reaction that occurs between the nitrogen atom at the amino end of one amino acid and the carbon atom at the carboxyl end of another, bonding the two amino acids and releasing a molecule of water. The linkage is called a peptide bond, and long chains of amino acids can be strung together into polymers, called polypeptides.
When a peptide bond is formed, the amino acid is changed (losing two hydrogen atoms and an oxygen atom), so the portion of the original molecule integrated into the polypeptide is often called a residue. The sequence of amino acid residues that make up a protein is called the protein’s primary structure. The primary structure is directly coded for in the genetic material.
It is interesting to note that only a small proportion of the very many possible polypeptide chains are naturally occurring proteins. Computationally, this is unsurprising.
The twenty naturally occuring amino acids all have the common elements shown in Figure 2. The varying parts are called sidechains; the two carbons and the nitrogen in the core are sometimes called the backbone. Peptide bonds link together the backbones of a sequence of amino acids. That link can be characterized as having two degrees of rotational freedom, the phi ($\phi$) and psi ($\psi$) angles (although from the point of view of physics this is a drastic simplification, in most biological contexts it is valid). The conformation of a protein backbone (i.e. its shape when folded) can be adequately described as a series of $\phi/\psi$ angles, although it is also possible to represent the shape using the Cartesian coordinates ([kɑ:ˈti:ziən], 笛卡尔坐标系) of the central backbone atom (the alpha carbon, written $C\alpha$), or using various other representational schemes (see, e.g., Hunter or Zhang & Waltz in this volume).
Exactly how the properties of the amino acids in the primary structure of a protein interact to determine the protein’s ultimate conformation remains unknown. The chemical properties of the individual amino acids, however, are known with great precision. These properties form the basis for many representations of amino acids, e.g. in programs attempting to predict structure from sequence. Here is a brief summary of some of them:
4.2.1 Glycine is the simplest amino acid
- glycine: [‘glaɪsi:n], 甘氨酸
Glycine is the simplest amino acid:
- Its sidechain is a single hydrogen atom.
- It is nonpolar, and does not ionize easily.
- The polarity (极性) of a molecule refers to the degree that its electrons are distributed asymmetrically. A nonpolar molecule has a relatively even distribution of charge.
- Ionization (电离) is the process that causes a molecule to gain or lose an electron, and hence become charged overall. The distribution of charge has a strong effect on the behavior of a molecule (e.g. like charges repel).
Another important characteristic of glycine is that as a result of having no heavy (i.e. non-hydrogen) atoms in its sidechain, it is very flexible. That flexibility can give rise to unusual kinks (A tight curl, twist, or bend) in the folded protein.
4.2.2 Alanine is also simple
- alanine: [‘æləni:n], 丙氨酸
Alanine is also small and simple:
- Its sidechain is just a methyl ([‘meθɪl] or [‘meθəl], 甲基) group (consisting of a carbon and three hydrogen atoms).
- Alanine is one of the most commonly appearing amino acids.
4.2.3 Animo acids with aliphatic sidechains
Glycine and alanine’s sidechains are aliphatic ([ˌælə’fætɪk], 脂肪族的), which means that they are straight chains (no loops) containing only carbon and hydrogen atoms.
- There are three other aliphatic amino acids:
- valine: [‘væli:n], 缬氨酸
- leucine: [‘lu:si:n], 亮氨酸
- isoleucine: [ˌaɪsə’lu:ˌsi:n], 异亮氨酸
- The longer aliphatic sidechains are hydrophobic ([ˌhaɪdrə’fəʊbɪk]). Hydrophobicity ([haɪdrəfəʊ’bɪsɪtɪ]) is one of the key factors that determines how the chain of amino acids will fold up into an active protein. Hydrophobic residues tend to come together to form compact core that exclude water. Because the environment inside cells is aqueous ([ˈeɪkwiəs], primarily water), these hydrophobic residues will tend to be on the inside of a protein, rather than on its surface.
4.2.4 Amino acids with large sidechains
In contrast to alanine and glycine, the sidechains of amino acids phenylalanine, tyrosine and tryptophan are quite large.
- phenylalanine: [fenɪ’læləni:n], 苯(基)丙氨酸
- tyrosine: [‘taɪrəˌsi:n], 酪氨酸
- tryptophan: [‘trɪptəˌfæn], 色氨酸
Size matters in protein folding because atoms resist being too close to one another, so it is hard to pack many large sidechains closely.
These sidechains are also aromatic ([ˌærəˈmætɪk], 芳香族的), meaning that they form closed rings of carbon atoms with alternating double bonds (like the simple molecule benzene, [ˈbenzi:n], 苯). These rings are large and inflexible.
Phenylalanine and tryptophan are also hydrophobic. Tyrosine has a hydroxyl ([haɪ’drɒksɪl], 羟基) group (an OH at the end of the ring), and is therefore more reactive than the other sidechains mentioned so far, and less hydrophobic.
These large amino acids appear less often than would be expected if proteins were composed randomly.
Serine and threonine also contain hydroxyl groups, but do not have rings.
- serine: [‘seri:n], 丝氨酸
- threonine: [‘θri:əˌni:n], 苏氨酸
4.2.5 Ionization
Another feature of importance in amino acids is whether they ionize to form charged groups.
Residues that ionize are characterized by their pK, which indicates at what pH (level of acidity) half of the molecules of that amino acid will have ionized.
Arginine and lysine have high pK’s (that is, they ionize in basic environments) and histidine, gluatmic acid and aspartic acid have low pK’s (they ionize in acidic ones).
- arginine: [‘ɑ:dʒəˌni:n], 精氨酸
- lysine: [‘laɪsi:n], 赖氨酸
- histidine: [‘hɪstɪdi:n], 组氨酸
- glutamic acid: [ɡlu:ˈtæmik], 谷氨酸
- aspartic acid: [əˈspɑ:tɪk], 天(门)冬氨酸
Since like charges repel and opposites attract, charge is an important feature in predicting protein conformation. Most of the charged residues in a protein will be found at its surface, although some will form bonds with each other on the inside of the molecule (called salt-bridges) which can provide strong constraints on the ultimate folded form.
4.2.6 Animo acids with hydrophobic sidechains and sulphur atoms
Cysteine and methionine have hydrophobic sidechains that contain a sulphur atom, and each plays an important role in protein structure.
- cysteine: [‘sɪstɪn], 半胱氨酸
- methionine: [me’θaɪəni:n], 蛋氨酸, 甲硫氨酸
The sulphurs make the amino acids’ sidechains very reactive.
- Cysteines can form disulphide ([daɪ’sʌlfaɪd], 二硫化物) bonds with each other; disulphide bonds often hold distant parts of a polypeptide chain near each other, constraining the folded conformation like salt bridges. For that reason, cysteines have a special role in determining the three dimensional structure of proteins. (The chapter by Holbrook, Muskal and Kim in this volume discusses the prediction of this and other folding constraints.)
- Methionine is also important because all eucaryotic proteins, when originally synthesized in the ribosome, start with a methionine. It is a kind of “start” signal in the genetic code. This methionine is generally removed before the protein is released into the cell, however.
4.2.7 Animo acids in enzymes
Histidine is a relatively rare amino acid, but it often appears in the active site of an .
The active site is the small portion of an enzyme that effects the target reaction, and it is the key to understanding the chemistry involved.
The rest of the enzyme provides the necessary scaffolding to bring the active site to bear in the right place, and to keep it away from bonds that it might do harm to.
Other regions of enzymes can also act as a switch, turning the active site on and off in a process called allosteric control. Because histidine’s pK is near the typical pH of a cell, it is possible for small, local changes in the chemical environment to flip it back and forth between being charged and not charged. This ability to flip between states makes it useful for catalyzing chemical reactions. Other charged residues also sometimes play a similar role in catalysis.
| Abbreviation | 1 letter abbreviation | Amino acid name | Chinese name |
|---|---|---|---|
| Ala | A | Alanine [‘æləni:n] | 丙氨酸 |
| Arg | R | Arginine [‘ɑ:dʒəˌni:n] | 精氨酸 |
| Asn | N | Asparagine [ə’spærəˌdʒi:n] | 天冬酰胺 |
| Asp | D | Aspartic acid [əˈspɑ:tɪk] | 天(门)冬氨酸 |
| Asx | B | Aspartic acid or Asparagine | |
| Cys | C | Cysteine [‘sɪstɪn] | 半胱氨酸 |
| Gln | Q | Glutamine [‘glu:təmi:n] | 谷氨酰胺 |
| Glu | E | Glutamic acid [ɡlu:ˈtæmik] | 谷氨酸 |
| Glx | Z | Glutamic acid or Glutamine | |
| Gly | G | Glycine [‘glaɪsi:n] | 甘氨酸 |
| His | H | Histidine [‘hɪstɪdi:n] | 组氨酸 |
| Ile | I | Isoleucine [ˌaɪsə’lu:ˌsi:n] | 异亮氨酸 |
| Leu | L | Leucine [‘lu:si:n] | 亮氨酸 |
| Lys | K | Lysine [‘laɪsi:n] | 赖氨酸 |
| Met | M | Methionine [me’θaɪəni:n] | 甲硫氨酸(蛋氨酸) |
| Phe | F | Phenylalanine [fenɪ’læləni:n] | 苯(基)丙氨酸 |
| Pro | P | Proline [‘prəʊli:n] | 脯氨酸 |
| Pyl | O | Pyrrolysine [pɪ’rɒlaɪzɪn] | 吡咯赖氨酸 |
| Ser | S | Serine [‘seri:n] | 丝氨酸 |
| Sec | U | Selenocysteine [se’li:nəsɪstaɪn] | 硒半胱氨酸 |
| Thr | T | Threonine [‘θri:əˌni:n] | 苏氨酸 |
| Trp | W | Tryptophan [‘trɪptəˌfæn] | 色氨酸 |
| Tyr | Y | Tyrosine [‘taɪrəˌsi:n] | 酪氨酸 |
| Val | V | Valine [‘væli:n] | 缬氨酸 |
| Xaa | X | Any amino acid | |
| Xle | J | Leucine or Isoleucine | |
| TERM | termination codon |
4.2.8 Protein Structures
The genetic code specifies only the amino acid sequence of a protein. As a new protein comes off the ribosome, it folds up into the shape that gives it its biochemical function, sometimes called its active conformation (the same protein unfolded into some other shape is said to be denatured, which is what happens, e.g. to the white of an egg when you cook it). In the cell, this process takes a few seconds, which is a very long time for a chemical reaction. The complex structure of the ribosome may play a role in protein folding, and a few proteins need helper molecules, termed chaperones to fold properly.
- The protein primary structure is the amino acid sequence.
- The protein tertiary structure is the position of the atoms in a folded protein.
- The protein secondary structure is the general three-dimensional form of local segments of proteins which can be formally defined by the pattern of hydrogen bonds of the protein (such as $\alpha$-helices and $\beta$-sheets) that are observed in an atomic-resolution structure. More specifically, the secondary structure is defined by the patterns of hydrogen bonds formed between amine hydrogen and carbonyl oxygen atoms contained in the backbone peptide bonds of the protein.
- There are two main kinds of secondary structure:
- $\alpha$-helices are corkscrew-shaped conformations where the amino acids are packed tightlytogether
- $\beta$-sheets are long flat sheets made up of two or more adjacent strands of the molecule, extended so that the amino acids are stretched out as far from each other as they can be.
- Each extended chain is called a $\beta$-strand, and two or more $beta$-strands held together by hydrogen bonds are called a $\beta$-sheet.
- $\beta$-sheets can be composed of strands running in the same direction (called a parallel $\beta$-sheet) or running in the opposite direction (antiparallel).
- Other kinds of secondary structure include structures that are even more tightly packed than $\alpha$-helices called $3-10$ helices, and a variety of small structures that link other structures, called $\beta$-turns.
- Some local combinations of secondary structures have been observed in a variety of different proteins. For example, two $\alpha$-helices linked by a turn with an approximately 60° angle have been observed in a variety of proteins that bind to DNA. This pattern is called the helix-turn-helix motif, and is an example of what is known as super-secondary structure.
- There are two main kinds of secondary structure:
Finally, some proteins only become functional when assembled with other molecules. Additions necessary to make the folded protein active are termed the protein’s quaternary structure.
- Some proteins bind to copies of themselves; for example, some DNA-binding proteins only function as dimers (linked pairs).
- Other proteins require prosthetic groups such as heme or chlorophyl.
4.3 Nucleic Acids
There are four nucleotides found in DNA. Each nucleotide consists of three parts:
- one of two base molecules (a purine ([‘pjʊrɪn], 嘌吟) or a pyrimidine ([paɪ’rɪmɪdi:n], 嘧啶)),
- The purine nucleotides are adenine ([‘ædənɪn], 腺嘌吟)(A) and guanine ([‘gwɑ:ni:n], 鸟嘌呤)(G), and
- the pyrimidines are cytosine ([‘saɪtəʊsi:n], 胞嘧啶)(C) and thymine ([‘θaɪmi:n], 胸腺嘧啶)(T).
- plus a sugar (ribose [‘raɪbəʊs] in RNA and deoxyribose [di:ˌɒksɪ’raɪbəʊs] in DNA), and
- one or more phosphate groups.
Nucleotides are sometimes called bases, and, since DNA consists of two complementary strands bonded together, these units are often called base-pairs. The length of a DNA sequences is often measured in thousands of bases, abbreviated kb.
The nucleotides are linked to each other in the polymer by phosphodiester ([ˌfə’sfɒdɪəstə], 磷酸二酯) bonds. This bond is directional, a strand of DNA has a head (called the 5’ end) and a tail (the 3’ end).
One well known fact about DNA is that it forms a double helix; that is, two helical (spiral-shaped) strands of the polypeptide, running in opposite directions, held together by hydrogen bonds.
In most biological circumstances, the DNA forms a classic double helix, called B-DNA; in certain circumstances, however, it can become supercoiled or even reverse the direction of its twist (this form is called Z-DNA). These alternative forms may play a role in turning particular genes on and off. There is some evidence that the geometry of the B-DNA form (e.g for example, differing twist angles between adjacent base pairs) may also be exploited by cell mechanisms. The fact that the conformation of the DNA can have a biological effect over and above the sequence it encodes highlights an important lesson for computer scientists: there is more information available to a cell than appears in the sequence databases.
5. Genetic Expression: From Blueprint to Finished Product
5.1 Genes, the Genome and the Genetic Code
The genetic information of an organism can be stored in one or more distinct DNA molecules; each is called a chromosome. In some sexually reproducing organisms, called diploids, each chromosome contains two similar DNA molecules physically bound together, one from each parent. Sexually reproducing organisms with single DNA molecules in their chromosomes are called haploid. Human beings are diploid with 23 pairs of linear chromosomes. In Bacteria, it is common for the ends of the DNA molecule to bind together, forming a circular chromosome. All of the genetic information of an organism, taken together as a whole, is refered to as its genome.
The primary role of nucleic acids is to carry the encoding of the primary structure of proteins. Each non-overlapping triplet of nucleotides, called a codon, corresponds to a particular amino acid. Most amino acids are encoded by more than one codon. For example, alanine is represented in DNA by the codons GCT, GCC, GCA and GCG. Notice that the first two nucleotides of these codons are all identical, and that the third is redundant. Although this is not true for all of the amino acids, most codon synonyms differ only in the last nucleotide. This phenomenon is called the degeneracy of the code.
Since codons come in triples, there are three possible places to start parsing a segment of DNA. For example, the chain ...AATGCGATAAG... could be read ...AAT-GCG-ATA... or ...ATG-CGATAA... or ...TGC-GAT-AAG.... This problem is similar to decoding an asynchronous serial bit stream into bytes. Each of these parsings is called a reading frame. A parsing with a long enough string of codons with no intervening stop codons is called an open reading frame, or ORF; and could be translated into a protein.
Not only are there three possible reading frames in a DNA sequence, it is possible to read off either strand of the double helix (但是读的顺序是定死的,一定是 5’ end 到 3’ end). This is sometimes called reading from the antisense or complementary strand. An antisense message can also be parsed three ways, making a total of 6 possible reading frames for every DNA sequence.
DNA sequences coding for a single protein in most eucaryotes have noncoding sequences, called introns, inserted into them. These introns are spliced out before the sequence is mapped into amino acids. Different eucaryotes have a variety of different systems for recognizing and removing these introns. Most bacteria don’t have introns. It is not known whether introns evolved only after the origin of eucaryotes, or whether selective pressure has caused bacteria to lose theirs. The segments of DNA that actually end up coding for a protein are called exons. You can keep these straight by remembering that introns are insertions, and that exons are expressed.
Every cell in the body has the same DNA, but each cell type has to generate a different set of proteins, and even within a single cell type, its needs change throughout its life. An increasing number of DNA signals that appear to play a role in the control of expression are being characterized. There are a variety of signals identifying where proteins begin and end, where splices should occur, and an exquisitely detailed set of mechanisms for controlling which proteins should be synthesized and in what quantities. Large scale features of a DNA molecule, such as a region rich in Cs and Gs can play a biologically important role, too.
Finally, some exceptions to the rules I mentioned above should be noted. DNA is sometimes found in single strands, particularly in some viruses. Viruses also play other tricks with nucleic acids, such as transcribing RNA into DNA, going against the normal flow of information in the cell. Even non-standard base-pairings sometimes play an important role, such as in the structure of transfer RNA.
5.2 RNA: Transcription, Translation, Splicing & RNA Structure
The process of mapping from DNA sequence to folded protein in eucaryotes involves many steps.
- The first step is the transcription of a portion of DNA into an RNA molecule, called a messenger RNA (mRNA). This process begins with the binding of a molecule called RNA polymerase to a location on the DNA molecule. Exactly where that polymerase binds determines which strand of the DNA will be read and in which direction. Parts of the DNA near the beginning of a protein coding region contain signals which can be recognized by the polymerase; these regions are called promoters. The polymerase catalyzes a reaction which causes the DNA to be used as a template to create a complementary strand of RNA, called the primary transcript. This transcript contains introns as well as exons. At the end of the transcript, 250 or more extra adenosines, called a poly-A tail, are often added to the RNA. The role of these nucleotides is not known, but the distinctive signature is sometimes used to detect the presence of mRNAs.
- The next step is the splicing the exons together. This operation takes place in a ribosome-like assembly called a spliceosome. The RNA remaining after the introns have been spliced out is called a mature mRNA. It is then transported out of the nucleus to the cytoplasm ([ˈsaɪtəʊplæzəm], 细胞质), where it then binds to a ribosome (注意它们之间的关系:mRNA binds to ribosome; ribosome 根据 mRNA 来生产 protein).
A ribosome is a very complex combination of RNA and protein. It is at the ribosome that the mRNA is used as a blueprint for the production of a protein; this process is called translation. The reading frame that the translation will use is determined by the ribosome. The translation process depends on the presence of molecules, called transfer-RNA or tRNAs, which make the mapping from codons in the mRNA to amino acids. tRNAs have an anti-codon (that binds to its corresponding codon) near one end and the corresponding amino acid on the other end. The anti-codon end of the tRNAs bind to the mRNA, bringing the amino acids corresponding the mRNA sequence into physical proximity, where they form peptide bonds with each other (mRNA 的 codon 好比 angle parking spaces, tRNA 的 anti-codon 好比卡车车头,tRNA 上的 aa 好比车厢;停好车后车厢之间全部连接形成肽键,然后 folding).
Once the protein has folded, other transformations can occur. Various kinds of chemical groups can be bound to different places on the proteins, including sugars, phosphate, acetyl or methyl groups. These additions can change the hydrogen bonding proclivity or shape of the protein, and may be necessary to make the protein active, or may keep it from having an effect before it is needed. The general term for these transformations is post-translational modifications. Once this process is complete, the protein is then transported to the part of the cell where it will accomplish its function.
5.3 Genetic Regulation
Every cell has the same DNA. Yet the DNA in some cells codes for the proteins needed to function as, say, a muscle, and other code for the proteins to make the lens of the eye. The difference lies in the regulation of the genetic machinery. At any particular time, a particular cell is producing only a small fraction of the proteins coded for in its DNA. And the amount of each protein produced must be precisely regulated in order for the cell to function properly. The cell will change the proteins it synthesizes in response to the environment or other cues. The mechanisms that regulate this process constitute a finely tuned, highly parallel system with extensive multifactoral feedback and elaborate control structure. It is also not yet well understood.
Genes are generally said to be on or off (or expressed/not expressed), although the amount of protein produced is also important. The production process is controlled by a complex collection of proteins in the nucleus of eucaryotic cells that influence which genes are expressed. Perhaps the most important of these proteins are the histones (组蛋白), which are tightly bound to the DNA in the chromosomes of eucaryotes. Other proteins swarm around the DNA, some influencing the production of a single gene (either encouraging or inhibiting it), while others can influence the production of large numbers of genes at once. An important group of these proteins are called topoisomerases ([ˌtɒpɔɪ’sʌməreɪz], 拓扑异构酶); they rearrange and untangle the DNA in various ways, and are the next most prevalent proteins in the chromosome.
Many regulatory proteins recognize and bind to very specific sequences in the DNA. The sequences that these proteins recognize tend to border the protein coding regions of genes, and are known generally as control regions:
- Sequences that occur just upstream (towards the 5’ end) of the coding region that encourage the production of the protein are called promoters.
- Similar regions either downstream of the coding region or relatively far upstream are called enhancers.
- Sequences that tend to prevent the production of a protein are called silencers.
Cells need to turn entire suites of genes on and off in response to many different events, ranging from normal development to trying to repair damage to the cell. The control mechanisms are responsive to the level of a product already in the cell (for homeostatic control) as well as to a tremendous variety of extracellular signals. Perhaps the most amazing activities in gene regulation occur during development; not only are genes turned on and off with precise timing, but the control can extend to producing alternative splicings of the nascent primary transcripts (as is the case in the transition from fetal to normal hemoglobin).
5.4 Catalysis & Metabolic Pathways
The translation of genes into proteins, crucial as it is, is only a small portion of the biochemical activity in a cell. Proteins do most of the work of managing the flow of energy, synthesizing, degrading and transporting materials, sending and receiving signals, exerting forces on the world, and providing structural support.
Somewhat surprisingly, a large proportion of the chemical processes that underlie all of these activities are shared across a very wide range of organisms. These shared processes are collectively referred to as intermediary metabolism ([məˈtæbəlɪzəm], 新陈代谢). These include
- (catabolism, [kə’tæbəlɪzəm], 异化作用) the catabolic ([kætə’bɒlɪk]) processes for breaking down proteins, fats and carbohydrates (such as those found in food) and
- (anabolism, [ə’nabəˌlɪzəm], 同化作用) the anabolic ([ə’næbəlɪk]) processes for building new materials.
Similar collections of reactions that are more specialized to particular organisms are called secondary metabolism. The substances that these reactions produce and consume are called metabolites.
The biochemical processes in intermediary metabolism are almost all catalyzed reactions. enzyme 本身就是一种 catalyst. Common classes of enzymes include
- dehydrogenase: [di:’haɪdrədʒəneɪs], 脱氢酶
- synthetase: [‘sɪnθɪteɪs], 合成酶
- protease: [ˈprəʊtieɪz], 蛋白酶 (for breaking down proteins)
- decarboxylas: [di:kɑ:’bɒksəleɪs], 脱羧酶
- transferase: [‘trænsfəˌreɪs], 转移酶 (moving a chemical group from one place to another)
- kinase: [‘kɪneɪs], 激酶 (从高能供体分子(如 ATP)转移磷酸基团到特定靶分子(受質)的酶; 这一过程谓之磷酸化. 一般而言, 磷酸化的目的是“激活”或“能化”受質, 增大它的能量)
- phosphatase: [‘fɒsfəteɪs], 磷酸酶 (adding or removing phosphate groups, respectively)
The materials transformed by catalysts are called substrates ([ˈsʌbstreɪt], 底物).
A final point to note about enzymatic reactions is that in many cases the reactions can proceed in either direction. That is, and enzyme that transforms substance A into substance B can often also facilitate the transformation of B into A. The direction of the transformation depends on the concentrations of the substrates and on the energetics of the reaction.
Even the basic transformations of intermediary metabolism can involve dozens or hundreds of catalyzed reactions. These combinations of reactions, which accomplish tasks like turning foods into useable energy or compounds are called metabolic pathways.
In addition to the feedback loops among the substrates in the pathways, the presence or absence of substrates can affect the behavior of the enzymes themselves, through what is called allosteric regulation. These interactions occur when a substance binds to an enzyme someplace other than its usual active site (the atoms in the molecule that have the enzymatic effect). Binding at this other site changes the shape of the enzyme, thereby changing its activity. Another method of controlling enzymes is called competitive inhibition. In this form of regulation, substance other than the usual substrate of the enzyme binds to the active site of the enzyme, preventing it from having an effect on its substrate.
5.5 Genetic Mechanisms of Evolution
Most mutations have relatively little effect. Mutations in the middle of introns generally have no effect at all (although mutations at the ends of an intron can affect the splicing process). Mutations in the third position of most codons have little effect at the protein level because of the redundancy of the genetic code. Even mutations that cause changes in the sequence of a protein are often neutral. Of course, some point mutations are lethal, and others lead to diseases. Very rarely, a mutation will be advantageous; it will then rapidly get fixed in the population, as the organisms with the conferred advantage out-reproduce the ones without it.
6. Sources of Biological Knowledge
The purpose of this section is to describe some of the basic experimental methods of molecular biology. These methods are important not only in understanding the source of possible errors in the data, but also because computational methods for managing laboratory activities and analyzing raw data are another area where AI can play a role.
6.1 Model Organisms: Germs, Worms, Weeds, Bugs & Rodents
The following six organisms form the main collection of models used in molecular biology:
E. coli
- Escherichia coli: [ˌeʃəˈrikiə] [‘kəʊlaɪ], 大肠杆菌
Because it is a relatively simple organism with fast reproduction time and is safe and easy to work with, E. coli has been the focus of a great deal of research in genetics and molecular biology of the cell. Although it is a Bacterium, many of the basic biochemical mechanisms of E. coli are shared by humans.
E. coli is a common target for genetic engineering, where genes from other organisms are inserted into the bacterial genome then produced in quantity。
Saccharomyces cerevisiae
It is better known as brewer’s yeast (酿酒酵母), and it is another safe, easy to grow, short generation time organism.
Unlike the bacterium E. coli, yeasts are eucaryotes, with a cell nucleus, mitochondria, a eucaryotic cell membrane, and many of the other cellular components and processes found in most other eucaryotes, including people.
One of the crucial steps in sequencing large amounts of DNA is to be able to prepare many copies of moderate sized pieces of DNA. An widely used method for doing this is the yeast artificial chromosome (or YAC).
Arabidopsis
- Arabidopsis: [əræ’bɪdɒpsɪs], 拟南芥
Arabidopsis makes a good model because it undergoes the same processes of growth, development, flowering and reproduction as most higher plants, but it’s genome has 30 times less DNA than corn, and very little repetitive DNA.
It also produces lots of seeds, and takes only about six weeks to grow to maturity.
C. elegans
- Caenorhabditis elegans: [ˌseɪnɵræbˈdɪtɪs ˈɛlɛɡænz], 秀丽隐杆线虫
The adult organism has exactly 959 cells, and every normal worm consists of exactly the same collection of cells in the same places doing the same thing.
It is one of the simplest creatures with a nervous system (which involves about a third of its cells).
Not only is the complete anatomy of the organism known, but a complete cell fate map has been generated, tracing the developmental lineage of each of each cell throughout the lifespan of the organism.
D. melanogaster, i.e. common fruit fly
- Drosophila melanogaster: [drɒˈsɒfɪlə] [mɛ.ɫa.nɔˈɡas.tɛr]
These flies have short generation times, and many different genetically determined morphological characteristics (e.g. eye color) that can readily be determined by visual inspection.
M. musculus, i.e. house mouse
- Mus musculus: [mʌsk’jʊləs],
Mice are mammals, and, as far as biochemistry is concerned, are practically identical to people. Many questions about physiology, reproduction, functioning of the immune and nervous systems and other areas of interest can only be addressed by examining creatures that are very similar to humans; mice nearly always fit the bill.
The similarities between mice and people mean also that the mouse is a very complicated creature; it has a relatively large, complex genome, and mouse development and physiology is not as regular or consistent as that of C. elegans or Drosophila.
7. Experimental Methods
Imaging
- E.g. light microscope and electon microscope.
- New technologies including the Atomic Force Microscope (AFM) and the Scanning Tunnelling Microscope (STM) offer the potential to create images of individual molecules.
Gel Electrophoresis
- [ɪˌlektrəʊfə’ri:sɪs], 凝胶电泳
- A charged molecule, when placed in an electric field, will be accelerated; positively charged molecules will move toward negative electrodes and vice versa.
- By placing a mixture of molecules of interest in a medium and subjecting them to an electric charge, the molecules will migrate through the medium and separate from each other. How fast the molecules will move depends on their charge and their size—bigger molecules see more resistance from the medium.
- The procedure, called electrophoresis involves putting a spot of the mixture to be analyzed at the top of a polyacrylamide ([ˌpɒli:ə’krɪləˌmaɪd], 聚丙烯酰胺) or agarose ([‘ɑ:gərəʊs], 琼脂糖) gel, and applying an electric field for a period of time. Then the gel is stained so that the molecules become visible; the stains appear as stripes along the gel, and are called bands.
- The location of the bands on the gel are proportional to the charge and size of the molecules in the mixture.
- The intensity of the stain is an indication of the amount of a particular molecule in the mixture.
- If the molecules are all the same charge, or have charge proportional to their size (as, for example, DNA does) then electrophoresis separates them purely by size.
- The adjacent, parallel runs are sometimes called lanes.
- A variation on this technique allows the sorting of molecules by a chemical property called the isoelectric point (等电点), which is related to its pK.
- A combination of the two methods, called 2D electrophoresis (双向电泳) is capable of very fine distinctions, for example, mapping each protein in a cell to a unique spot in two-space, the size of the spot indicating the amount of the protein.
- In addition, if a desired molecule can be separated from the mixture this way, individual spots or bands can be removed from the gel for further processing, in a procedure called blotting.
Cloning
- In order for a cloned gene to be expressed, it must contain the appropriate transcription signals for the target cell line. One way biologists ensure that this will happen is to put the new gene into a cloning vector.
- A cloning vector is a small piece of DNA, taken from a virus, a plasmid, or the cell of a higher organism, that can be stably maintained in an organism, and into which a foreign DNA fragment can be inserted for cloning purposes.
- Cloning is generally first performed using E. coli, and cloning vectors in E. coli include bacteriophages ([bæk’tɪərɪəʃəɪdʒ], a virus that infects bacteria) (such as phage λ) and plasmids ([‘plæzmɪd], 质粒, a small DNA molecule within a cell that is physically separated from a chromosomal DNA and can replicate independently).
- In order to cut and paste desired DNA fragments into vectors, biologists use restriction enzymes, which cut DNA at precisely specified points.
- These enzymes are produced naturally by bacteria as a way of attacking foreign DNA.
- For example, the commonly used enzyme EcoRI (from E. coli) cuts DNA between the G and the A in the sequence GAATTC; these target sequences are called restriction sites.
Hybridization and Immunological Staining
- Biological compounds can show remarkable specificity, for example, binding very selectively only to one particular compound. This ability plays an important role in the laboratory, where researchers can identify the presence or absence of a particular molecule (or even a region of a molecule) in vanishingly small amounts.
- Antibodies are the molecules that the immune system uses to identify and fight off invaders. Antibodies are extremely specific, recognizing and binding to only one kind of molecule. Dyes can be attached to the antibody, forming a very specific system for identifying the presence (and possibly quantifying the amount) of a target molecule that is present in a system.
- One technique measures how similar two related DNA sequences are by testing how strongly the single-stranded versions of the molecules stick to each other, or hybridize. The more easily they come apart, the more differences there are between their sequences.
- It is also possible to attach a dye or other marker to a specific piece of DNA (called a probe) and then hybridize it to a longer strand of DNA. The location along the strand that is complementary to the probe will then be marked.
Gene Mapping and Sequencing
- First, because crossover is an important component of inheritance in sexually reproducing organisms, genes that are near each other on the chromosome will tend to be inherited together. In fact, this forms the basis for linkage analysis, which is a technique that looks at the relationships between genes (or phenotypes) in large numbers of matings (in this context, often called crosses) to identify which genes tend to be inherited together, and are therefore likely to be near each other.
- Second, it is possible to clone genes of known locations, opening up a wide range of possible experimental manipulations.
- Finally, it is currently possible to determine the sequence of moderate size pieces of DNA, so if an important gene has been mapped, it is possible to find the sequence of that area, and discover the protein that is responsible for the genetic characteristic. This is especially important for understanding the basis of inherited diseases.
The existence of several different kinds of restriction enzymes makes possible a molecular method of creating genetic maps.
- The application of each restriction enzyme (the process is called a digest) creates a different collection of restriction fragments (the cut up pieces of DNA). By using gel electrophoresis, it is possible to determine the size of these fragments. Using multiple enzymes, together and separately, results in sets of fragments which can be (partially) ordered with respect to each other, resulting in a genetic map. AI techniques for reasoning about partial orders have been effectively applied to the problem of assembling the fragments into a map.
- Restriction fragment mapping becomes problematic when applied to large stretches of DNA, because the enzymes can produce many pieces of about the same size, making the map ambiguous. The use of different enzymes can help address this problem to a limited degree, but a variety of other techniques are now also used:
- Contigs + Cosmids:
- contig: 叠连群, A set of overlapping DNA segments, derived from a single source of genetic material, from which the complete sequence may be deduced.
- cosmid: 黏粒, A plasmid into which a short nucleotide sequence of a bacteriophage has been inserted to create a vector capable of cloning large fragments of DNA
- PCR: polymerase chain reaction
- PCR exponentially amplifies (makes copies of) a segment of a DNA molecule, given a unique pair of sequences that bracket the desired piece.
- 这个 unique pair of sequences that bracket the desired piece 我们称为 primer
- 从种类上来说,primer 属于 oligonucleotide
- oligonucleotide: [ˌoʊlɪgoʊ’nu:kli:ətaɪd], 寡核苷酸, 是一类只有20个以下碱基的短链核苷酸的总称, or oligo for short (oligomer 是低聚物).
- The primers, the target DNA and the enzyme DNA polymerase are then combined. The mixture is heated, so that the hydrogen bonds in the target DNA break and the molecule splits into two single strands. When the mixture cools sufficiently, the primers bond to the regions around the area of interest, and the DNA polymerase replicates the DNA downstream of the primers. By using a heat resistant polymerase from an Archaea species that lives at high temperatures, it is possible to rapidly cycle this process, doubling the amount of desired segment of DNA each time.
- 具体可以看这个 演示
- In order to use PCR for genome mapping and sequencing, a collection of unique (short) sequences spread throughout the genome must be identified for use as primers. The primer sequences must be unique in the genome so that the source of amplified DNA is unambiguous, and they have to be relatively short so that they are easy to synthesize. The sites in the genome that correspond to these primer sequences are called sequence tagged sites or STSs. The more STSs that are known, the finer grained the map of the genome they provide.
- PCR exponentially amplifies (makes copies of) a segment of a DNA molecule, given a unique pair of sequences that bracket the desired piece.
- Contigs + Cosmids:
Crystallography ([ˌkrɪstəˈlɔ:grəfi], 晶体学) and NMR (nuclear magnetic resonance)
- Additional information about protein structure is necessary to understand how the proteins function. This structural information is at the present primarily gathered by X-ray crystallography.
- A promising alternative to crystallography for determining protein structure is multi-dimensional nuclear magnetic resonance, or NMR.
Computational Biology
主要介绍了一些 database,需要的时候可以看看。稍微有点老。
留下评论