R PCA Example
0. More Math Definitions
If $X$ is a matrix with each variable in a column and each observation in a row then the SVD is a “matrix decomposition” that decomposes the original matrix into 3 separate matrices as
P.S. Octave 里是 [U, S, V] = svd(X),$X = U \ast S \ast V^T$,只是记号不同而已)
where the columns of U are orthogonal ([ɔ:’θɒgənl], 正交的) (U a.k.a left singular vectors), the columns of V are orthogonal (V a.k.a right singular vectors) and D is a diagonal matrix (D a.k.a singular values).
- 注:如果向量 $x$ 和 $y$ 的点积为 0,i.e. $x*y^T = 0$,则称 $x$ 和 $y$ 正交。上面说 “columns of
Uare orthogonal” 意思是 “U的 columns (转置后)是两两正交的”,用 Octave 的写法就是U(:,i)' * U(:,j) = 0。 - 注2:
U的 column(转置后)还是个单位向量,i.e.U(:,i)' * U(:,i) = 1 - 注3:结合 注1 和 注2,有
U' * U = U * U' = I - 注4:其实
V就是U',i.e.U * V = I
1. 题外话: Impute Missing Data before PCA
比如可以使用 Bioconductor 的 {impute} 包。安装方法:
source("http://bioconductor.org/biocLite.R")
biocLite("impute")
比如使用 knn 策略来 impute:
matrix2 <- impute.knn(matrix)$data
Knn, or k-nearest-neighbors, is a policy that take the k (10 by default in the code above) rows closest to the row with NA, impute the NA with average of the k rows.
2. Face Example
Load the .rda file [face.rda][/assets/posts/2014-09-09-r-pca-example/face.rda].
load("face.rda")
image(t(faceData)[, nrow(faceData):1]) ## t for transpose; 相当于 Octave 的 X'
## 这里转置再上下颠倒一下完全是因为这个图片本身就是歪的,并没有什么特殊用意
3. Variance Explained
udv <- svd(scale(faceData))
plot(udv$d^2/sum(udv$d^2), pch = 19, xlab = "Singular vector", ylab = "Variance explained")
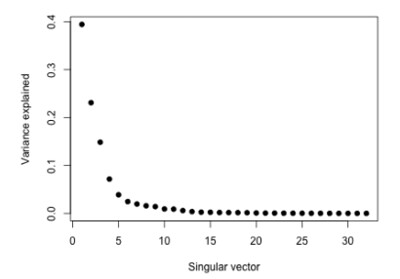
注意这里和 Machine Learning: Dimensionality Reduction 那篇不同,这里是直接把 $X$ 拿来分解了,然后再计算的协方差。
4. Create Approximations
udv <- svd(scale(faceData)) ## Note that '%*%' is matrix multiplication
## scale 就是指 feature scaling/mean normalization (centering),i.e. subtract the mean then divide by the standard deviation
## dim(faceData) = 32x32
## dim(udv$u) = 32x32
## str(udv$d) = 1x32, 因为是 diagonal 于是把 0 全都省了
## dim(udv$v) = 32x32
approx1 <- (udv$u[, 1] * udv$d[1]) %*% t(udv$v[, 1]) ## 这里必须加一个括号,不然 'd %*% t(v)' 会先结合
approx5 <- udv$u[, 1:5] %*% diag(udv$d[1:5]) %*% t(udv$v[, 1:5]) ## 'diag' is used to make the diagonal matrix out of d
approx10 <- udv$u[, 1:10] %*% diag(udv$d[1:10]) %*% t(udv$v[, 1:10])
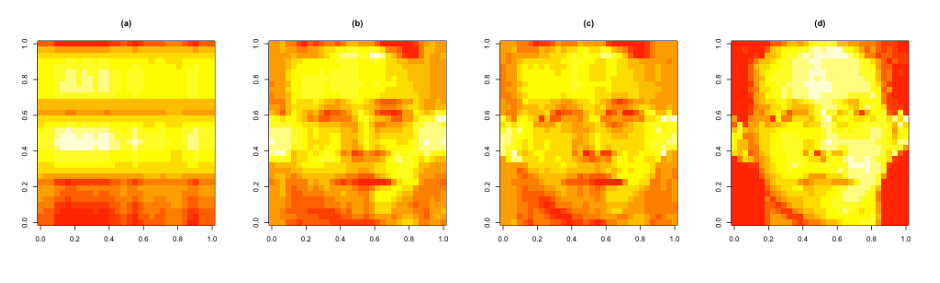
5. Plot Approximations
par(mfrow = c(1, 4))
image(t(approx1)[, nrow(approx1):1], main = "(a)")
image(t(approx5)[, nrow(approx5):1], main = "(b)")
image(t(approx10)[, nrow(approx10):1], main = "(c)")
image(t(faceData)[, nrow(faceData):1], main = "(d)") ## Original data
~~~~~~~~~~ 2015-12-06 补充:开始 ~~~~~~~~~~
以下参考 Running PCA and SVD in R。
x <- t(e)
pc <- prcomp(x)
names(pc)
## [1] "sdev" "rotation" "center" "scale" "x"
## `pc$x[, 1]` is PC1;
## `pc$x[, 2]` is PC2;
## 依此类推
## pc$x[, 1] == udv$u[, 1];
## pc$x[, 2] == udv$u[, 2];
## 依此类推
## `pc$rotation` is the rotation matrix
## pc$rotation == udv$v
## `pc$sdev` 是 sample standard deviations
## 更准确地说,`pc$sdev` 是 unbiased estimates of standard deviations,所以带了一个 (n-1) 的 correction
## pc$sdev^2 == sv$d^2/(ncol(e) - 1)
~~~~~~~~~~ 2015-12-06 补充:结束 ~~~~~~~~~~
留下评论